Unveiling the Power of Meta’s Llama 2: A Leap Forward in Generative AI?
This article explores the technical details and implications of Meta's newly released Llama 2, a large language model that promises to revolutionize the field of generative AI. We delve into its capabilities, performance, and potential applications, while also discussing its open-source nature and the company's commitment to safety and transparency.

Image created by Author with Midjourney
Introduction
Recent breakthroughs in artificial intelligence (AI), particularly in generative AI, have captured the public's imagination and demonstrated the potential of these technologies to drive a new era of economic and social opportunities. One such breakthrough is Meta's Llama 2, the next generation of their open-source large language model.
Meta's Llama 2 is trained on a mix of publicly available data, and designed to drive applications such as OpenAI’s ChatGPT, Bing Chat, and other modern chatbots. Trained on a mix of publicly available data, Meta claims that Llama 2’s performance is improved significantly over previous Llama models. The model is available for fine-tuning on AWS, Azure, and Hugging Face’s AI model hosting platform in pretrained form, making it more accessible and easier to run. You can also download the model here.
But what sets Llama 2 apart from its predecessor and other large language models? Let's delve into its technical details and implications.
Technical Details and Performance
There are two flavors of Llama 2: Llama 2 and Llama-2-Chat. Llama-2-Chat has been fine-tuned for two-way conversations. Both versions come further subdivided into models of varying sophistication: 7 billion parameter, 13 billion parameter, and 70 billion parameter models. The models were trained on two trillion tokens, which is 40% morethen the first Llama model, including over 1 million human annotations.
Llama 2 has a context length of 4096, and employs reinforcement learning from human feedback specifically for safety and helpfulness in the case of Llama-Chat-2's training. Llama 2 outperforms other LLMs, including like Falcon and MPT, in the areas of reasoning, coding, proficiency, and knowledge tests, according to Meta.
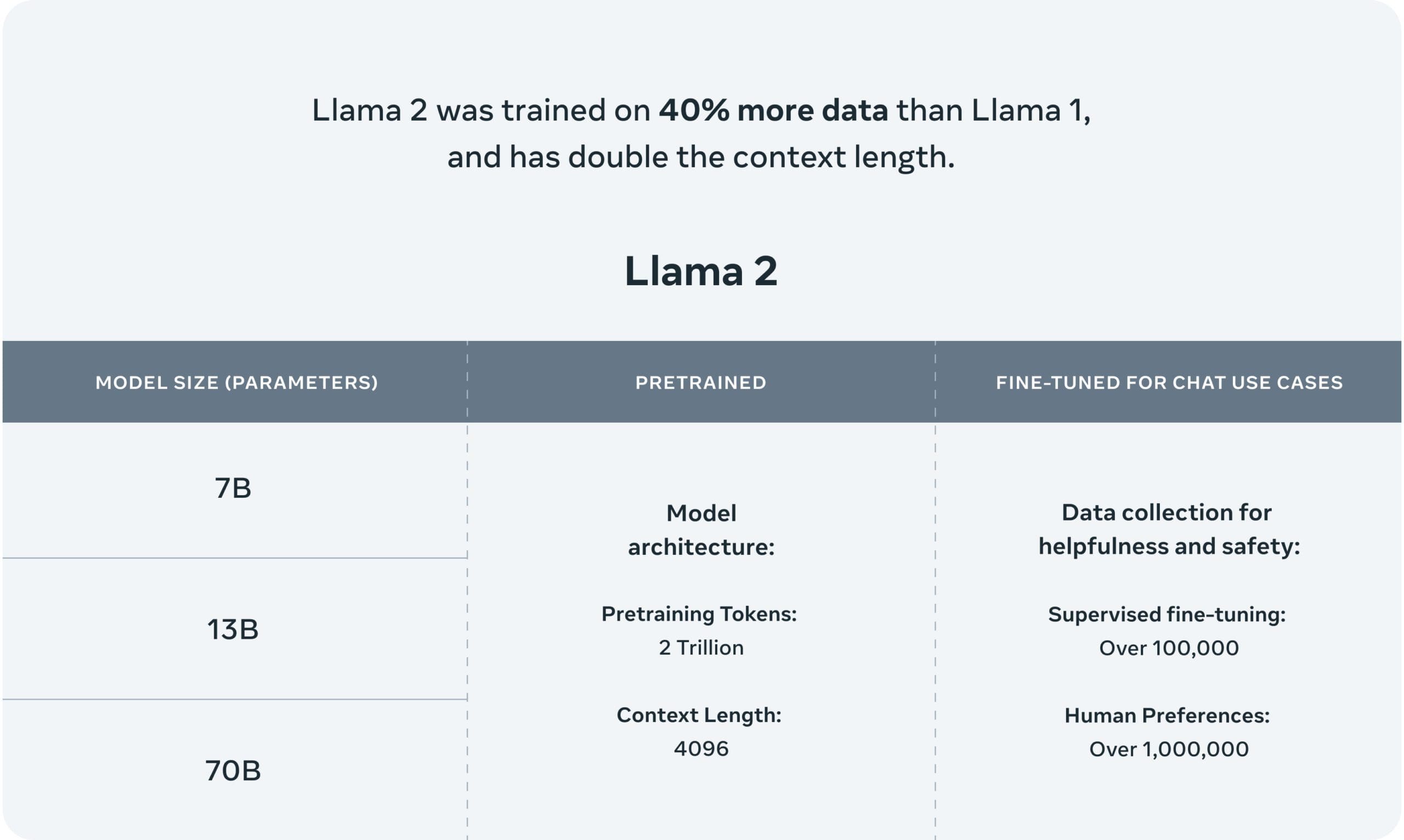
Llama 2 technical overview
(Image source: Meta)
Furthermore, Llama 2 is optimized to run locally on Windows and on smartphones and PCs packing Qualcomm’s Snapdragon on-device technology, which means we can expect AI-powered apps that work without relying on cloud services starting from 2024.
"These new on-device AI experiences, powered by Snapdragon, can work in areas with no connectivity or even in airplane mode."
—Qualcomm (source: CNET)
Open-Source and Safety
One of the key aspects of Llama 2 is its open-source nature. Meta believes that by making AI models available openly, they can benefit everyone. This development permits both the business and research worlds to access tools that would become prohibitive to build and scale themselves, which opens up myriad opportunities for research, experimentation and development.
Meta also emphasizes safety and transparency. Llama 2 has been "red-teamed," and thus has been tested for safety by generating adversarial prompts for the purposes of fine-tuning the model, both internally and externally. Meta discloses how the models are evaluated and tweaked, promoting transparency in the development process.
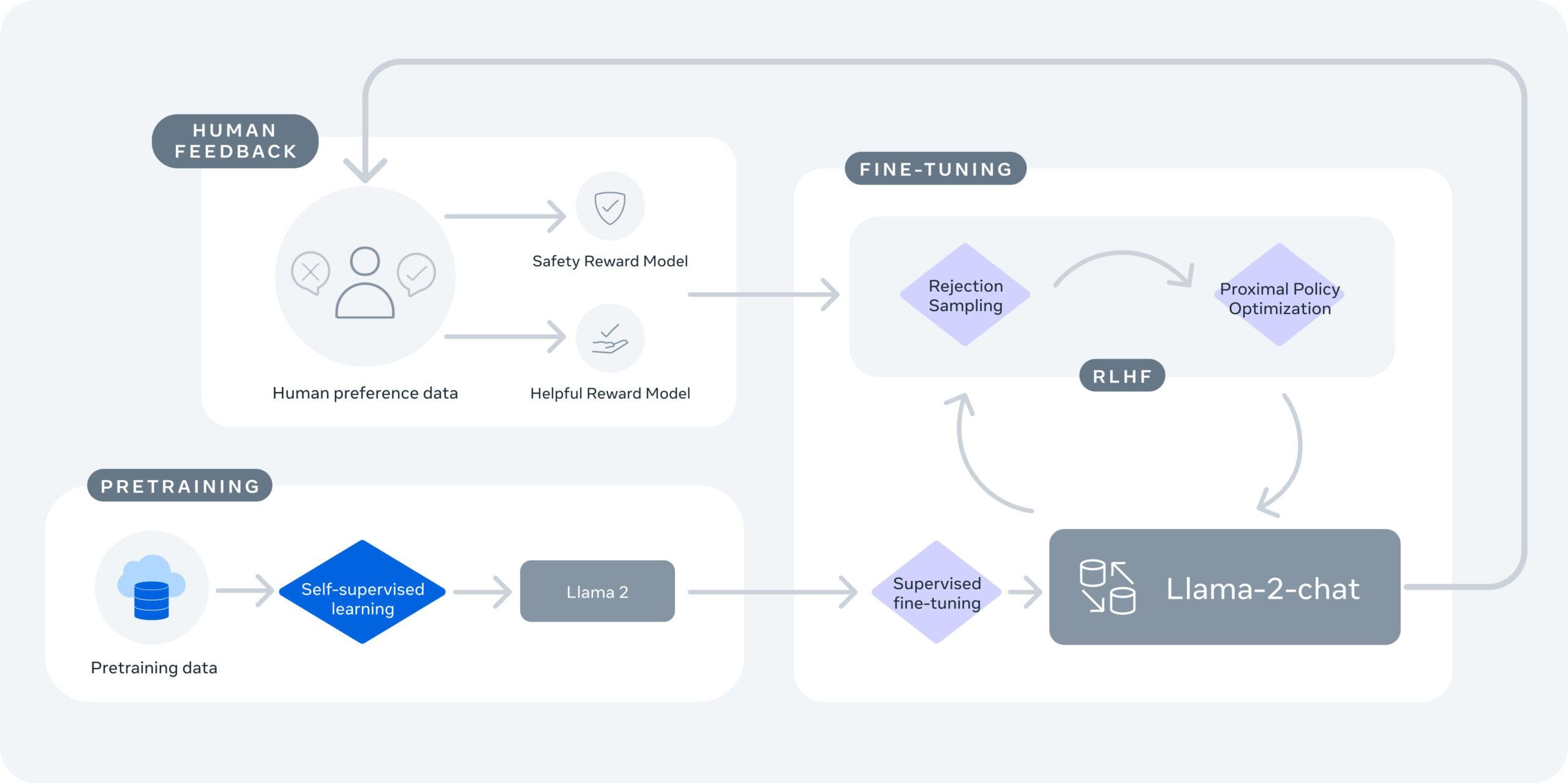
Reinforcement learning from human feedback is used for safety and helpfulness during Llama-2-Chat model training
(Image source: Meta)
Conclusion
Llama 2 does its best to continue Meta's perspective in the field of generative AI. Its improved performance, open-source nature, and commitment to safety and transparency make Llama 2 a promising model for a wide range of applications. As more developers and researchers gain access, we can expect to see a surge in innovative AI-powered solutions.
As we move forward, it will remain crucial to continue addressing the challenges and biases inherent in AI models. However, Meta's commitment to safety and transparency sets a positive precedent for the industry. With the release of Llama 2, we now have another tool available in our generative AI arsenal, and one that makes open access an ongoing commitment.
Matthew Mayo (@mattmayo13) is a Data Scientist and the Editor-in-Chief of KDnuggets, the seminal online Data Science and Machine Learning resource. His interests lie in natural language processing, algorithm design and optimization, unsupervised learning, neural networks, and automated approaches to machine learning. Matthew holds a Master's degree in computer science and a graduate diploma in data mining. He can be reached at editor1 at kdnuggets[dot]com.