Unveiling the Potential of CTGAN: Harnessing Generative AI for Synthetic Data
CTGAN and other generative AI models can create synthetic tabular data for ML training, data augmentation, testing, privacy-preserving sharing, and more.
We all know that GANs are gaining traction in the generation of unstructured synthetic data, such as images and texts. However, very little work has been done on generating synthetic tabular data using GANs. Synthetic data has numerous benefits, including its use in machine learning applications, data privacy, data analysis, and data augmentation. There are only a few models available for generating synthetic tabular data, and CTGAN (Conditional Tabular Generative Adversarial Network) is one of them. Like other GANs, it uses a generator and discriminator neural network to create synthetic data with similar statistical properties to real data. CTGAN can preserve the underlying structure of the real data, including correlations between columns. The added benefits of CTGAN include augmentation of the training procedure with mode-specific normalization, a few architectural changes, and addressing data imbalance by employing a conditional generator and training-by-sampling.
In this blog post, I used CTGAN to generate synthetic data based on a dataset on Credit Analysis collected from Kaggle.
Pros of CTGAN
- Generates synthetic tabular data that have similar statistical properties as the real data, including correlations between different columns.
- Preserves the underlying structure of real data.
- The synthetic data generated by CTGAN can be used for a variety of applications, such as data augmentation, data privacy, and data analysis.
- Can handle continuous, discrete, and categorical data.
Cons of CTGAN
- CTGAN requires a large amount of real tabular data to train the model and generate synthetic data that have similar statistical properties to the real data.
- CTGAN is computationally intensive and may require a significant amount of computing resources.
- The quality of the synthetic data generated by CTGAN may vary depending on the quality of the real data used to train the model.
Tuning CTGAN
Like all other machine learning models CTGAN performs better when it is tuned. And there are multiple parameters to be considered while tuning CTGANs. However, for this demonstration, I used all the default parameters that come with ‘ctgan library’:
- Epochs: Number of times generator and discriminator networks are trained on the dataset.
- Learning rate: The rate at which the model adjusts the weights during training.
- Batch size: Number of samples used in each training iteration.
- Generator and discriminator networks size.
- Choice of the optimization algorithm.
CTGAN also takes account of hyperparameters, such as the dimensionality of the latent space, the number of layers in the generator and discriminator networks, and the activation functions used in each layer. The choice of parameters and hyperparameters affects the performance and quality of the generated synthetic data.
Validation of CTGAN
Validation of CTGAN is tricky as it comes with limitations such as difficulties in the evaluation of the quality of the generated synthetic data, particularly when it comes to tabular data. Though there are metrics that can be used to evaluate the similarity between the real and synthetic data, it can still be challenging to determine if the synthetic data accurately represents the underlying patterns and relationships in the real data. Additionally, CTGAN is vulnerable to overfitting and can produce synthetic data that is too similar to the training data, which may limit their ability to generalize to new data.
A few common validations techniques include:
- Statistical Tests: To compare statistical properties of generated data and real data. For example, tests such as correlation analysis, Kolmogorov-Smirnov test, Anderson-Darling test, and chi-squared test to compare the distributions of the generated and real data.
- Visualization: By plotting histograms, scatterplots, or heatmaps to visualize the similarities and differences.
- Application Testing: By using synthetic data in real-world applications see if it performs similarly to the real data.
Case Study
About Credit Analysis Data
Credit analysis data contains client data in continuous and discrete/categorical formats. For demonstration purposes, I have pre-processed the data by removing rows with null values and deleting a few columns that were not needed for this demonstration. Due to limitations in computational resources, running all the data and all columns would require a lot of computation power that I do not have. Here is the list of columns for continuous and categorical variables (discrete values such as Count of Children (CNT_CHINDREN) are treated as categorical variables):
Categorical Variables:
TARGET
NAME_CONTRACT_TYPE
CODE_GENDER
FLAG_OWN_CAR
FLAG_OWN_REALTY
CNT_CHILDREN
Continuous Variables:
AMT_INCOME_TOTAL
AMT_CREDIT
AMT_ANNUITY
AMT_GOODS_PRICE
Generative models require a large amount of clean data to be trained on for better results. However, due to limitations in computation power, I have selected only 10,000 rows (precisely 9,993) from the over 300,000 rows of real data for this demonstration. Although this number may be considered relatively small, it should be sufficient for the purpose of this demonstration.
Location of the Real Data:
https://www.kaggle.com/datasets/kapoorshivam/credit-analysis
Location of the generated synthetic Data:
- Synthetic Credit Analysis Data by CTGAN (Kaggle)
- Synthetic Tabular Data Set Generated by CTGAN (Research Gate)
- DOI: 10.13140/RG.2.2.23275.82728

Credit Analysis Data | Image by Author
Results
I have generated 10k (9997 to be exact) synthetic data points and compared them to the real data. The results look good, although there is still potential for improvement. In my analysis, I used the default parameters, with 'relu' as the activation function and 3000 epochs. Increasing the number of epochs should result in a better generation of real-like synthetic data. The generator and discriminator loss also looks good, with lower losses indicating closer similarity between the synthetic and real data:
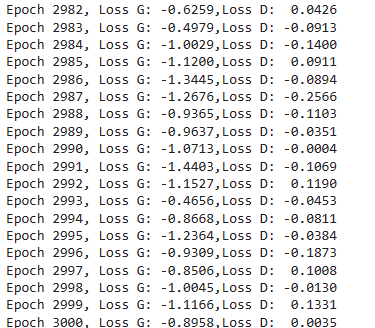
Generator and Discriminator loss | Image by Author
The dots along the diagonal line in the Absolute Log Mean and Standard Deviation diagram indicate that the quality of the generated data is good.
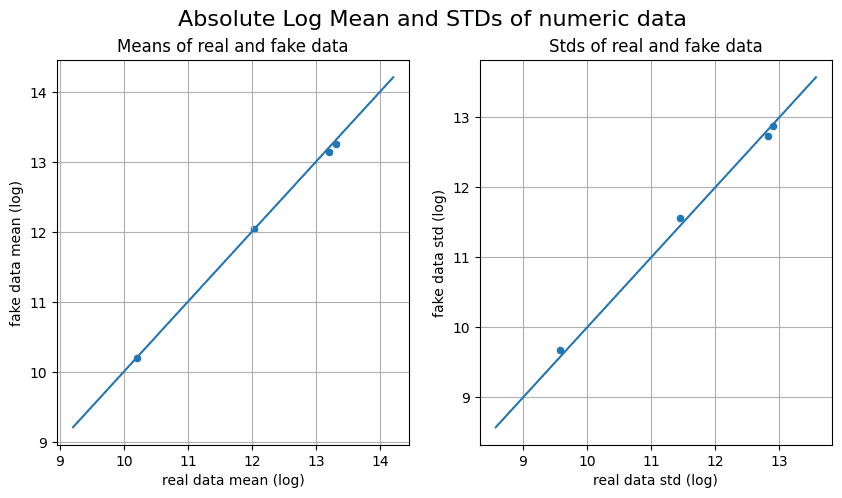
Absolute Log Mean and Standard Deviations of Numeric Data | Image by Author
The cumulative sums in the following figures for continuous columns are not exactly overlapping, but they are close, which indicates a good generation of synthetic data and the absence of overfitting. The overlap in categorical/discrete data suggests that the synthetic data generated is near-real. Further statistical analyses are presented in the following figures:
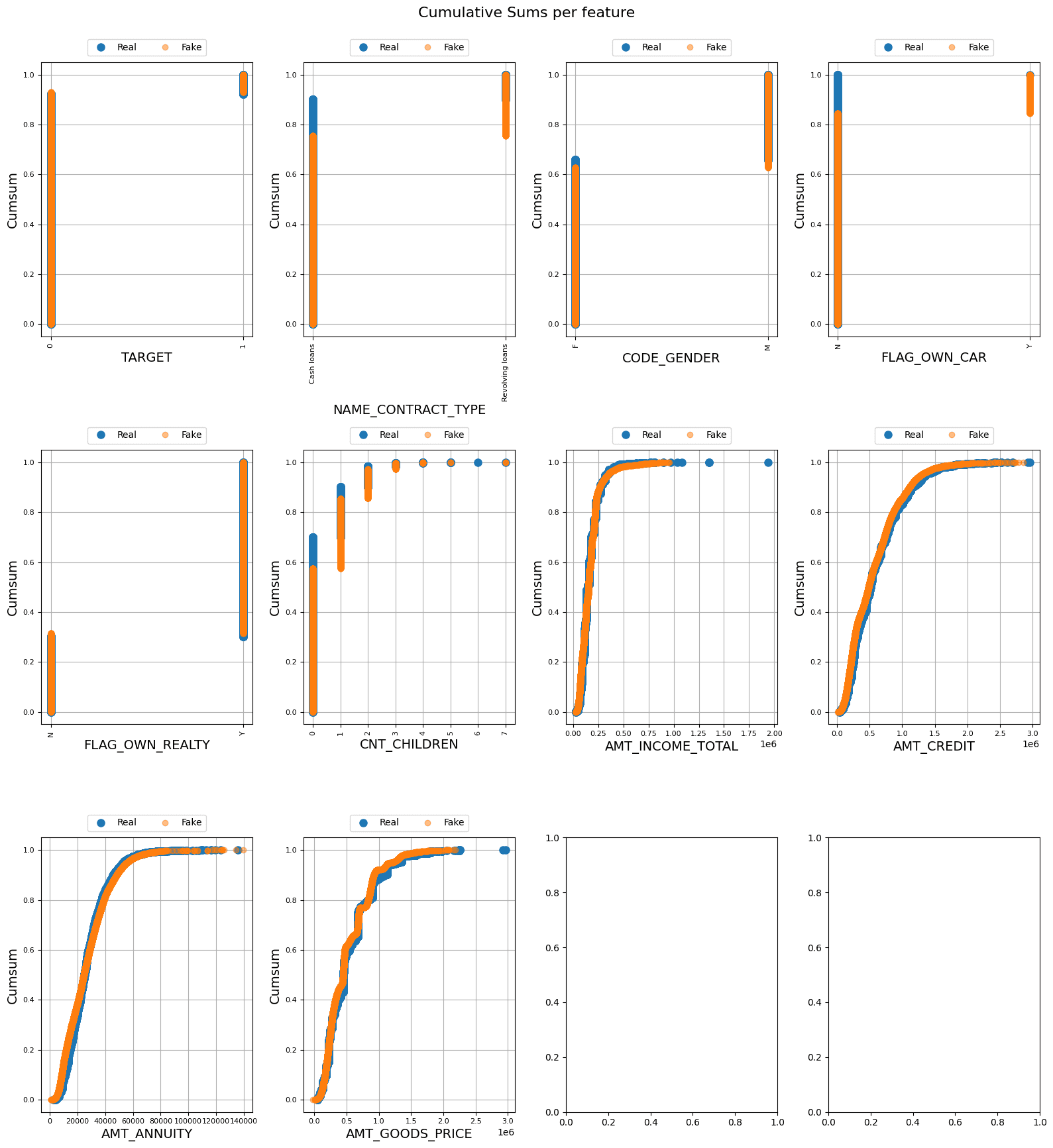
Cumulative Sums per Feature | Image by Author
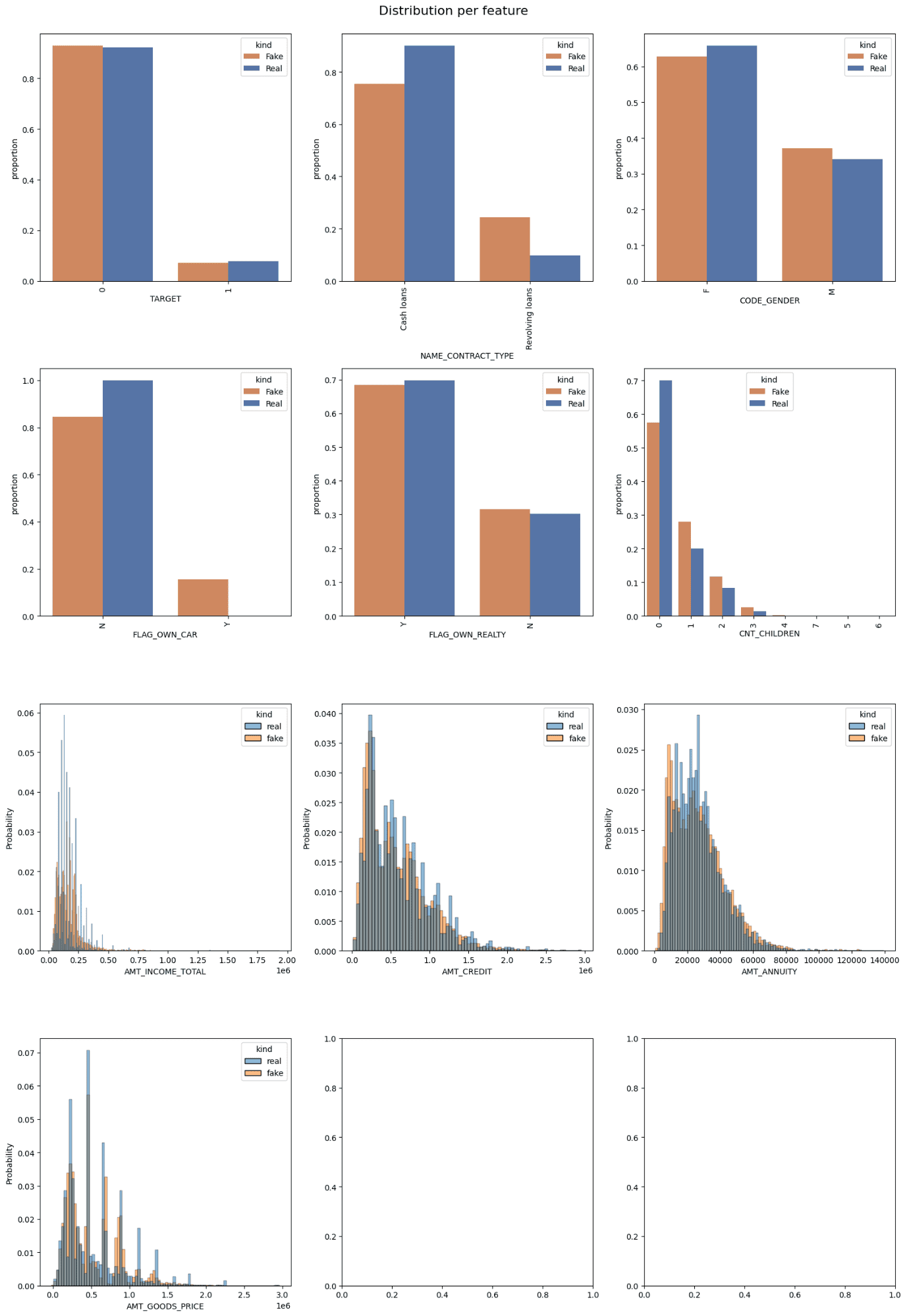
Distribution of Features| Image by Author
Distribution of Features | Image by Author
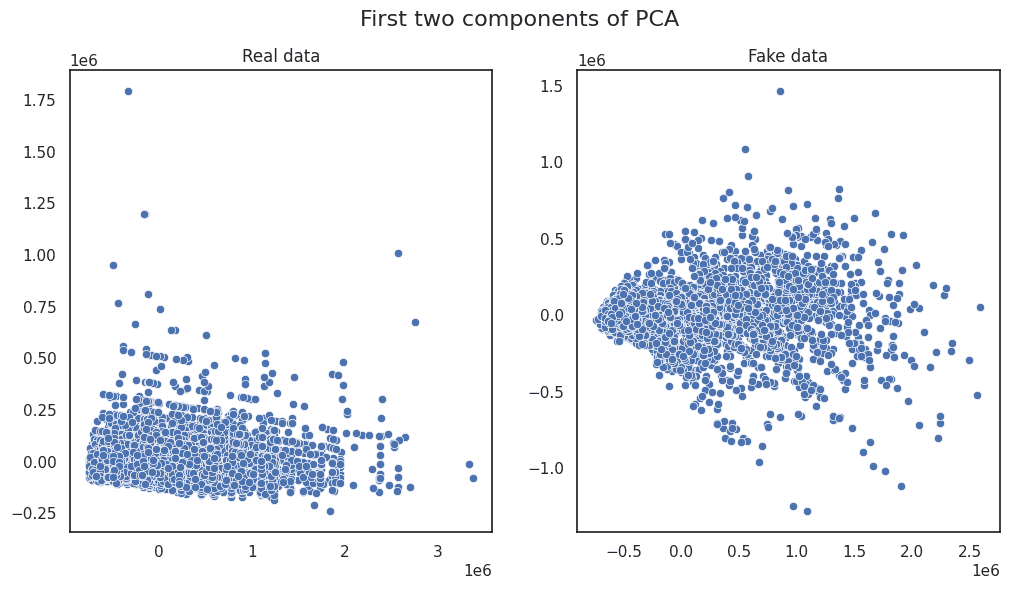
Principal Component Analysis | Image by Author
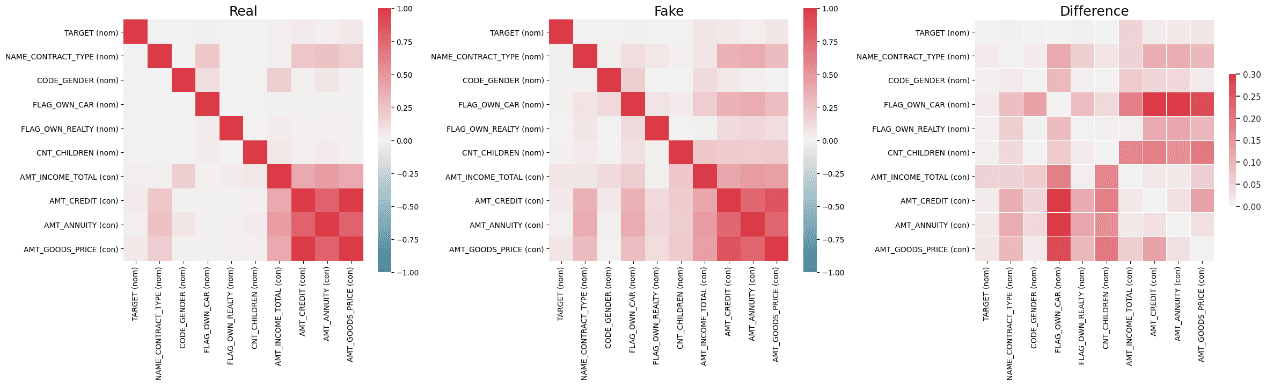
The following correlation diagram shows noticeable correlations between the variables. It is important to note that even after thorough fine-tuning, there may be variations in properties between real and synthetic data. These differences can actually be beneficial, as they may reveal hidden properties within the dataset that can be leveraged to create novel solutions. It has been observed that increasing the number of epochs leads to improvements in the quality of synthetic data.
Correlation among variables (Real Data) | Image by Author
Correlation among variables (Synthetic Data) | Image by Author
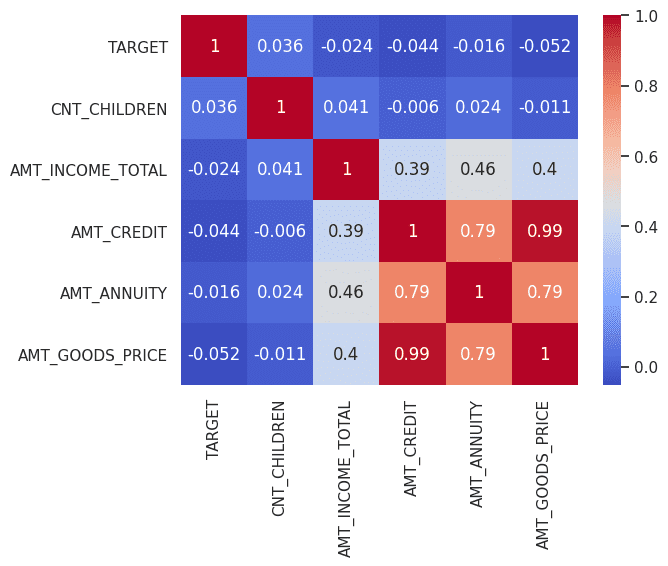
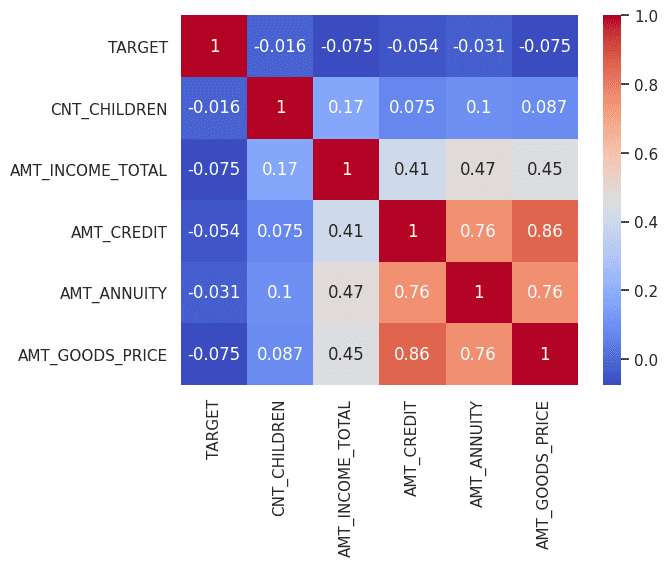
The summary statistics of both the sample data and real data also appear to be satisfactory.
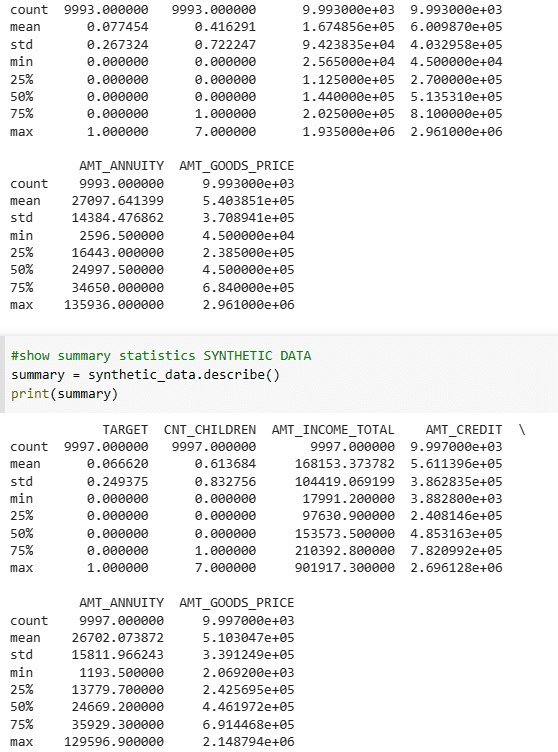
Summary Statistics of Real Data and Synthetic Data | Image by Author
Python Code
# Install CTGAN
!pip install ctgan
# Install table evaluator to analyze generated synthetic data
!pip install table_evaluator
# Import libraries
import torch
import pandas as pd
import seaborn as sns
import torch.nn as nn
from ctgan import CTGAN
from ctgan.synthesizers.ctgan import Generator
# Import training Data
data = pd.read_csv("./application_data_edited_2.csv")
# Declare Categorical Columns
categorical_features = [
"TARGET",
"NAME_CONTRACT_TYPE",
"CODE_GENDER",
"FLAG_OWN_CAR",
"FLAG_OWN_REALTY",
"CNT_CHILDREN",
]
# Declare Continuous Columns
continuous_cols = ["AMT_INCOME_TOTAL", "AMT_CREDIT", "AMT_ANNUITY", "AMT_GOODS_PRICE"]
# Train Model
from ctgan import CTGAN
ctgan = CTGAN(verbose=True)
ctgan.fit(data, categorical_features, epochs=100000)
# Generate synthetic_data
synthetic_data = ctgan.sample(10000)
# Analyze Synthetic Data
from table_evaluator import TableEvaluator
print(data.shape, synthetic_data.shape)
table_evaluator = TableEvaluator(data, synthetic_data, cat_cols=categorical_features)
table_evaluator.visual_evaluation()
# compute the correlation matrix
corr = synthetic_data.corr()
# plot the heatmap
sns.heatmap(corr, annot=True, cmap="coolwarm")
# show summary statistics SYNTHETIC DATA
summary = synthetic_data.describe()
print(summary)
Conclusion
The training process of CTGAN is expected to converge to a point where the generated synthetic data becomes indistinguishable from the real data. However, in reality, convergence cannot be guaranteed. Several factors can affect the convergence of CTGAN, including the choice of hyperparameters, the complexity of the data, and the architecture of the models. Furthermore, the instability of the training process can lead to mode collapse, where the generator produces only a limited set of similar samples instead of exploring the full diversity of the data distribution.
Ray Islam is a Data Scientist (AI and ML) and Advisory Specialist Leader at Deloitte, USA. He holds a PhD in Engineering from the University of Maryland, College Park, MD, USA and has worked with major companies like Lockheed Martin and Raytheon, serving clients such as NASA and the US Airforce. Ray also has MASc in Engineering from Canada, a MSc in International Marketing, and an MBA from, UK. He is also the Editor-in-Chief of the upcoming peer-reviewed International Research Journal of Ethics for AI (INTJEAI), and his research interests include generative AI, augmented reality, XAI, and ethics in AI.