Dolly 2.0: ChatGPT Open Source Alternative for Commercial Use
Dolly 2.0 was trained on a human-generated dataset of prompts and responses. The training methodology is similar to InstructGPT but with a claimed higher accuracy and lower training costs of less than $30.

Image from Author | Bing Image Creator
Dolly 2.0 is an open-source, instruction-followed, large language model (LLM) that was fine-tuned on a human-generated dataset. It can be used for both research and commercial purposes.
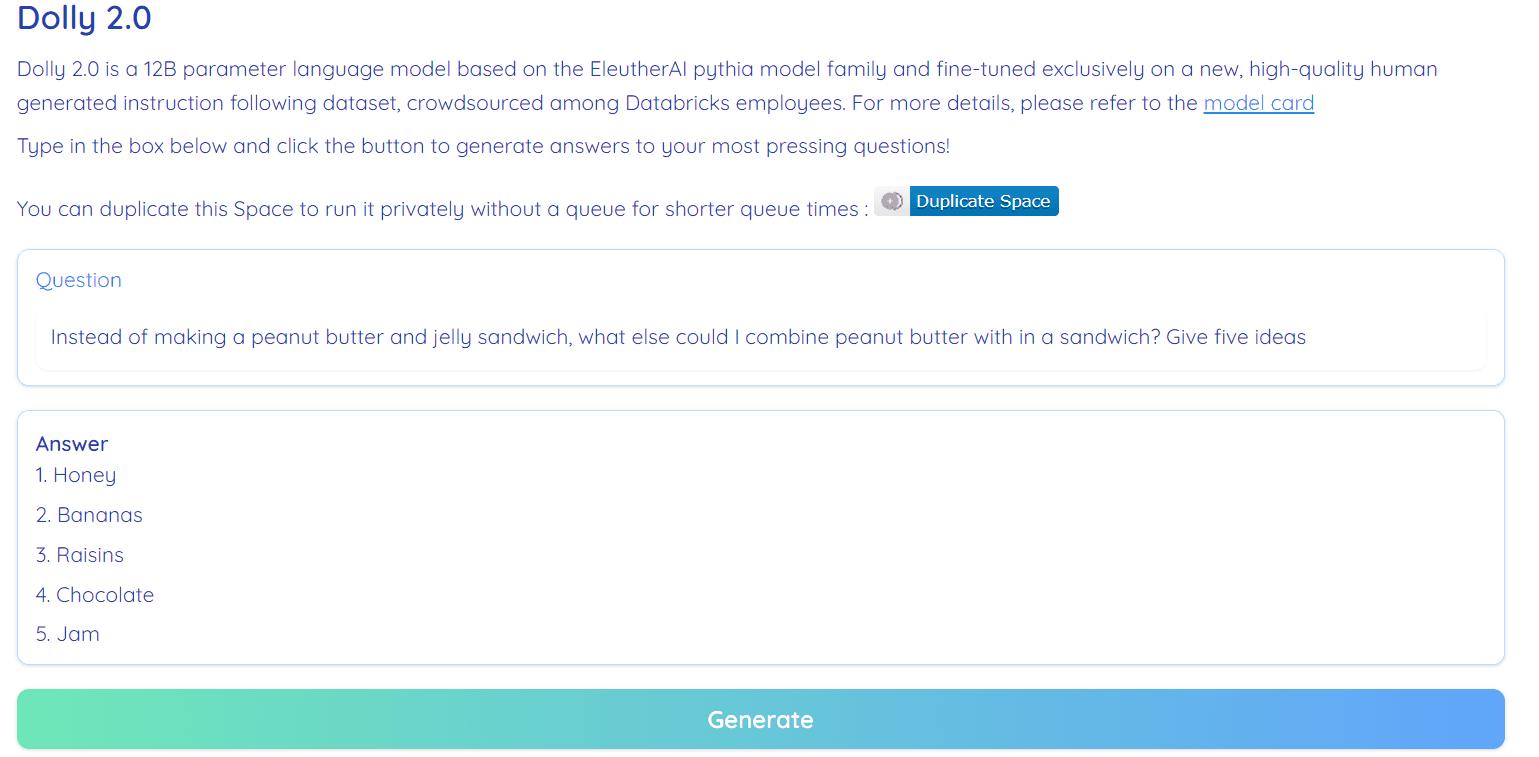
Image from Hugging Face Space by RamAnanth1
Previously, the Databricks team released Dolly 1.0, LLM, which exhibits ChatGPT-like instruction following ability and costs less than $30 to train. It was using the Stanford Alpaca team dataset, which was under a restricted license (Research only).
Dolly 2.0 has resolved this issue by fine-tuning the 12B parameter language model (Pythia) on a high-quality human-generated instruction in the following dataset, which was labeled by a Datbricks employee. Both model and dataset are available for commercial use.
Why do we need a Commercial License Dataset?
Dolly 1.0 was trained on a Stanford Alpaca dataset, which was created using OpenAI API. The dataset contains the output from ChatGPT and prevents anyone from using it to compete with OpenAI. In short, you cannot build a commercial chatbot or language application based on this dataset.
Most of the latest models released in the last few weeks suffered from the same issues, models like Alpaca, Koala, GPT4All, and Vicuna. To get around, we need to create new high-quality datasets that can be used for commercial use, and that is what the Databricks team has done with the databricks-dolly-15k dataset.
databricks-dolly-15k Dataset
The new dataset contains 15,000 high-quality human-labeled prompt/response pairs that can be used to design instruction tuning large language models. The databricks-dolly-15k dataset comes with Creative Commons Attribution-ShareAlike 3.0 Unported License, which allows anyone to use it, modify it, and create a commercial application on it.
How did they create the databricks-dolly-15k dataset?
The OpenAI research paper states that the original InstructGPT model was trained on 13,000 prompts and responses. By using this information, the Databricks team started to work on it, and it turns out that generating 13k questions and answers was a difficult task. They cannot use synthetic data or AI generative data, and they have to generate original answers to every question. This is where they have decided to use 5,000 employees of Databricks to create human-generated data.
The Databricks have set up a contest, in which the top 20 labelers would get a big award. In this contest, 5,000 Databricks employees participated that were very interested in LLMs
Results
The dolly-v2-12b is not a state-of-the-art model. It underperforms dolly-v1-6b in some evaluation benchmarks. It might be due to the composition and size of the underlying fine-tuning datasets. The Dolly model family is under active development, so you might see an updated version with better performance in the future.
In short, the dolly-v2-12b model has performed better than EleutherAI/gpt-neox-20b and EleutherAI/pythia-6.9b.

Image from Free Dolly
Getting Started
Dolly 2.0 is 100% open-source. It comes with training code, dataset, model weights, and inference pipeline. All of the components are suitable for commercial use. You can try out the model on Hugging Face Spaces Dolly V2 by RamAnanth1.
Image from Hugging Face
Resource:
- Training and inference code: databrickslabs/dolly
- Dolly 2.0 model weights: databricks/dolly-v2-12b
- databricks-dolly-15k dataset: dolly/data
Dolly 2.0 Demo: Dolly V2 by RamAnanth1
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master's degree in Technology Management and a bachelor's degree in Telecommunication Engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.