Data Protection Techniques Needed to Guarantee Privacy
This article takes a look at the concepts of data privacy and personal data. It presents several privacy protection techniques and explains how they contribute to preserving the privacy of individuals.
By Elise Devaux, Statice
The economics, legal, and corporate implications of data privacy are now too strong to be ignored. In the last decades, different privacy-enhancing techniques were proposed to respond to ever-increasing requirements of technical and societal nature. But how do you decide which approach to use?
The scope of data privacy
Two years after the General Data Protection Regulation (GDPR) introduction, personal data is at the epicenter of today’s privacy requirements. Over 60 jurisdictions modern privacy and data protection laws to regulate personal data processing.
Under the GDPR, any information relating to an identified or identifiable natural person is personal data. This inclusive definition encompasses both direct and indirect identifiers. Direct identifiers are information that explicitly identifies a person, such as a name, a social security number, or biometric data. Indirect, or quasi, identifiers refer to information that can be combined with additional data to identify a person. They are, for example, medical records, dates and places of birth, or financial information.
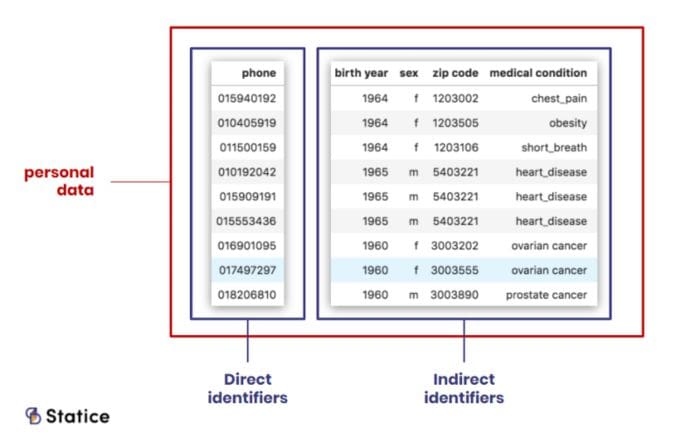
Traditionally, a risk hierarchy existed between these two types of attributes. Direct identifiers were perceived as more “sensitive” than quasi-identifiers. In many data releases, only the former attributes were subject to some privacy protection mechanism, while the latter were released in clear. Such releases were often followed by prompt re-identification of the supposedly ‘protected’ subjects. It soon became apparent that quasi-identifiers could be just as ‘sensitive’ as direct identifiers. With the GDPR, this notion has finally made it into law: both types of attributes are put on the same level, identifiers and quasi-identifiers attributes are personal data and present an equally important privacy breach risk.
Nowadays protection laws strictly regulate personal data processing. This makes a strong case for implementing privacy protection techniques. Indeed, failure to comply exposes companies to severe penalties. Besides, implementing proper privacy protections might lead to customer trust increase. In a world plagued by data breaches and privacy violations, people are increasingly concerned about what happens to their data. And finally, data breaches targeting personal data are costing companies money. Personal data remains the most expensive item to lose in a breach.
Most often, it is personal data that we seek to protect. However, any sensitive data can require privacy protection. For example, any business information, such as financial information or trade secrets, can need to remain private. Protecting business or classified information is usually a matter of holding on to corporate value.
These elements could incite companies to decrease the amount of personal data they collect and process. However, information is at the core of product and service development for many companies. By deleting personal data, companies would pass on many of the benefits and values they could derive from it. For all these reasons, companies must find privacy protection mechanisms to remain data-driven while safeguarding individuals' privacy.
Anonymization as means of privacy protection
A way to guarantee the privacy of personal and sensitive data is to anonymize it. Anonymization refers to the process of irreversibly transforming data to prevent the re-identification of individuals. Meaning that if a company releases an anonymized dataset, it’s theoretically impossible to re-identify a person from it, either directly or indirectly. Anonymization represents the highest form of privacy protection. However, perfect anonymity of data is rarely achieved, as it would render the data almost useless.
For some time, the middle ground has been to use lighter privacy protection mechanisms, mechanisms such as data masking or pseudonymization. These processes aim at protecting data by removing or altering its direct, sometimes indirect, identifiers. It's quite frequent to see the term "anonymization" in references to these methods. However, the two have clear legal and technical implications.
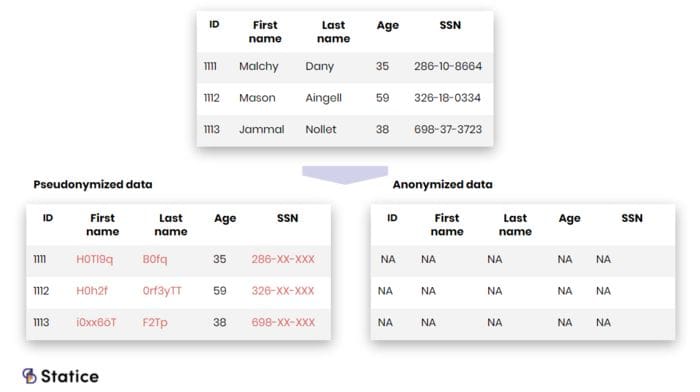
On the technical side, these techniques produce data with different levels of privacy protection. Masking or pseudonymization techniques can be reversed. They complicate the identification of individuals but don't remove the possibility of re-identifying someone. They're a weaker privacy protection mechanism than anonymization, which minimizes to greater extent re-identification risks.
On the legal side, modern data privacy laws, such as the GDPR and the California Consumer Privacy Act (CCPA), differentiate between pseudonymization and anonymization processes. The latest is considered private enough that anonymized data isn’t subject to personal data protection laws anymore. Pseudonymized data, on the other hand, still represents a risk for individual privacy and must be handled as personal data.
Privacy protection techniques
Different privacy protection techniques offer different protection levels. It is essential to know and understand how they work. Depending on the nature of the application and the data, you can choose one technique or another.
As mentioned above, pseudonymization, or data masking, is commonly used to protect data privacy. It consists of altering data, most of the time, direct identifiers, to protect individuals' privacy in the datasets. There are several techniques to produce pseudonymized data:
- Encryption: hiding sensitive data using a cipher protected by an encryption key.
- Shuffling: scrambling data within a column to disassociate its original other attributes.
- Suppression: nulling or removing from the dataset the sensitive columns.
- Redaction: masking out parts of the entirety of a column’s values.

Data generalization is another approach to protect privacy. The underlying idea is to prevent a person’s identification by reducing the details available in the data. There are, as well, various approaches to generalizing data. For example, it's possible to generate an aggregated value from the sensitive data or use a value range in place of a numerical value. Among data generalization techniques, we can find popular privacy models such as k-anonymity, l-diversity, t-closeness expressly designed to mitigate data disclosure risks.

Synthetic data offers an alternative approach to privacy protection. Instead of altering or masking the original data, one generates completely new artificial data. Machine learning models help create this new dataset that mimics the statistical properties of the original data.

The shortcomings of traditional data protection techniques
Data masking and generalization techniques are popular protection mechanisms. However, they present some drawbacks that it’s essential to know.
Pseudonymization presents limitations when it comes to data privacy. In multiple instances, researchers proved that this technique could lead to re-identification and disclosure of individual' identities. Most of the time, when you mask or remove data identifiers, the quasi-identifiers are still present. They can link individuals across secondary data sources, ultimately disclosing people's identity and breaching privacy.
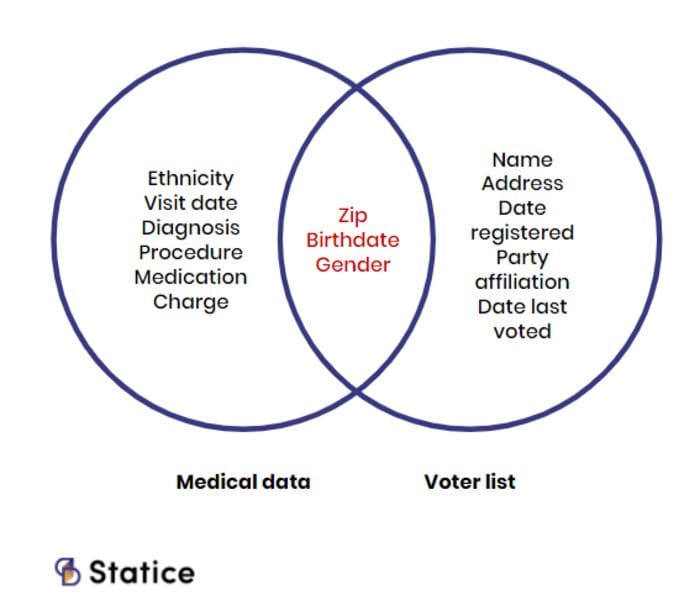
On the other hand, data generalization methods are known to deteriorate the value of the data. For example, when values are highly aggregated, the resulting data loses its statistical granularity. This granularity could have brought value to analyses. Researchers showed that some generalization methods, such as k-anonymity, had privacy loopholes.
Synthetic data allows finding a balance between the data privacy and data utility shortcomings of other methods. However, it can also present limitations and risks depending on the technology and the process used to generate the synthetic data. For example, some techniques can fail at properly mimicking data that holds unusual data points. Synthetic datasets can also suffer from privacy breaches when proper protections aren’t ensured.
There are more and more opportunities to address the privacy shortcomings of traditional techniques. Technologies are showing increasing signs of maturity. The number of PrivacyTech companies is rising quickly, and the industry is quickly attracting large fundings. Public bodies are starting to promote privacy-preserving technology. For instance, the UK government acknowledged in its National Data Strategy that synthetic data and other privacy-enhancing technologies represent an opportunity for innovation. Leading industry analysts such as Gartner also recognizes the rise of these technologies.
Bio: Elise Devaux (@elise_deux) is a tech enthusiast digital marketing manager, working at Statice, a startup specialized in synthetic data as a privacy-preserving solution.
Related:
- How “Anonymous” is Anonymized Data?
- 10 Use Cases for Privacy-Preserving Synthetic Data
- 10 Steps for Tackling Data Privacy and Security Laws in 2020