Key Machine Learning Technique: Nested Cross-Validation, Why and How, with Python code
Selecting the best performing machine learning model with optimal hyperparameters can sometimes still end up with a poorer performance once in production. This phenomenon might be the result of tuning the model and evaluating its performance on the same sets of train and test data. So, validating your model more rigorously can be key to a successful outcome.
By Omar Martinez, Arcalea.
In this article, we’ll briefly discuss and implement a technique that, in the grand scheme of things, might be getting less attention than it deserves. The previous statement comes from the observation that it’s a well-known issue that some models have a tendency to underperform in production compared to the performance in the model building stage. While there is an abundance of potential culprits for this issue, a common cause could lie in the model selection process.
A standard model selection process will usually include a hyperparameter optimization phase, in which, through the use of a validation technique, such as k-fold cross-validation (CV), an “optimal” model will be selected based on the results of a validation test. However, this process is vulnerable to a form of selection bias, which makes it unreliable in many applications. This is discussed in detail on a paper from Gavin Cawley & Nicola Talbot, in which we can find the following nugget of information:
“In a biased evaluation protocol, occasionally observed in machine learning studies, an initial model selection step is performed using all of the available data, often interactively as part of a “preliminary study.” The data are then repeatedly re-partitioned to form one or more pairs of random, disjoint design and test sets. These are then used for performance evaluation using the same fixed set of hyper-parameter values. This practice may seem at first glance to be fairly innocuous, however the test data are no longer statistically pure, as they have been “seen” by the models in tuning the hyperparameters.”
- On Over-fitting in Model Selection and Subsequent Selection Bias in Performance Evaluation, 2010.
To illustrate why this is happening, let’s use an example. Suppose that we are working on a machine learning task, in which we are selecting a model based on n rounds of hyperparameter optimization, and we do this by using a grid search and cross-validation. Now, if we are using the same train and test data at each one of the nth iterations, this means that information of performance on the test set is being incorporated into the training data via the choice of hyperparameters. At each iteration, this information can be capitalized by the process to find the best performing hyperparameters, and that leads to a test dataset that is no longer pure for performance evaluation. If n is large at some point, then we might consider the test set as a secondary training set (loosely speaking).
On the bright side, there are some techniques that can help us tackle this problem. One consists of having a train set, a test set, and also a validation set, and then tuning hyperparameters based on performance on the validation set.
The other strategy, and the focus of this article, is nested cross-validation, which coincides with one of the proposed solutions from the paper above, by treating the hyperparameter optimization as a part of the model fitting itself and evaluating it with a different validation set that is part of an outer layer of cross-validation.
Put simply, fitting, including the fitting of the hyperparameters, that in itself includes an inner CV process, is just like any other part of the model process and not a tool to evaluate model performance for that particular fitting approach. To evaluate performance, you use the outer cross-validation process. In practice, you do this by letting grid-search (or any other object you use for optimization) handle the inner cross-validation and then use cross_val_score to estimate generalization error in the outer loop. Thus, the final score will be obtained by averaging test set scores over several splits, as a regular CV process.
Here’s a simplified overview of the approach. This illustration is by no means technically rigorous but is to provide some intuition behind the whole process.
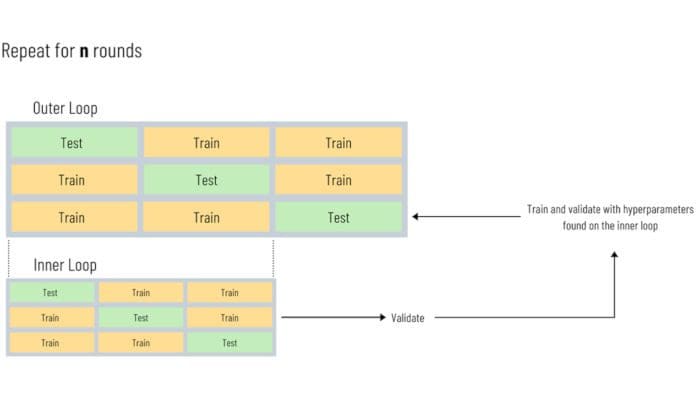
Simplified Illustration of the Nested Cross-Validation Process.
Nested Cross-validation in Python
Implementing nested CV in python, thanks to scikit-learn, is relatively straightforward.
Let’s look at an example. We’ll start by loading the wine dataset from sklearn.datasets and all of the necessary modules.
Now, we proceed to instantiate the classifier and then specify the number of rounds/trials we would like to run, in other words, how many times we’ll perform the whole process of going through both the inner and outer loops. Because this is computationally expensive and we are doing this only for demonstration purposes, let's choose 20. Remember, the number of rounds represents how many times you’ll split your dataset differently on each of the CV processes.
The next step involves creating a dictionary that will establish the hyperparameter space that we are going to explore in each round, and we also create two empty arrays to store the results from the nested and the non-nested processes.
The next step is crucial, we are going to create a for loop that will iterate for the number of rounds we've specified, and that will contain two different cross-validation objects.
For this example, we'll use 5-fold cross-validation for both the outer and inner loops, and we use the value of each round (i) as the random_state for both CV objects.
Then, we proceed to create and configure the object to perform the hyperparameter optimization. In this case, we'll use grid-search. Notice that we pass to grid-search the 'inner_cv' object as the cross-validation method.
Subsequently, notice that for the final scores of the "nested" cross-validation process, we use the cross_val_score function and feed it the classifier object 'clf' (includes its own CV process), which is the object we used to perform the hyperparameter optimization, and also the 'outer_cv' cross-validation object. In this process, we also fit the data and then store the results of each process inside the empty arrays we created before.
We can now calculate the difference in the accuracy scores of both the "simple" cross-validation and the nested cross-validation processes to see how much they disagree with each other on average.
In this case, by nested cross-validation scores, we mean the scores of the nested process (not to be confused with the inner cross-validation process), and we compare them with the scores of the regular process (non-nested).
Output:
Avg. difference of 0.001698 with std. dev. of 0.003162.
As we can see, the non-nested scores, on average, are more optimistic. Thus, relying solely on the information of that process might result in a biased model selection.
We can also plot the scores of each iteration and create a plot to get a visual comparison of how both processes behaved.
Output:
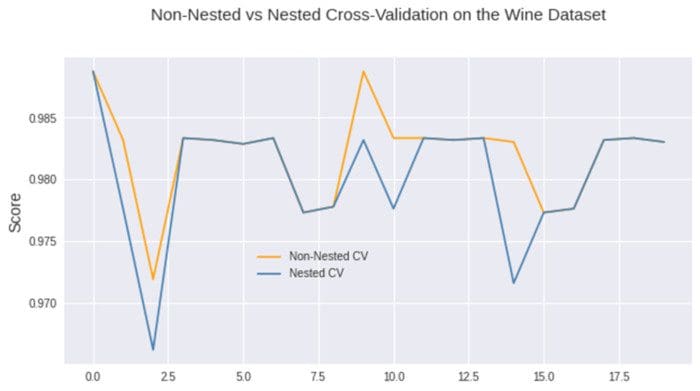
Finally, we can also plot the difference in each round for both CV processes.
Output:
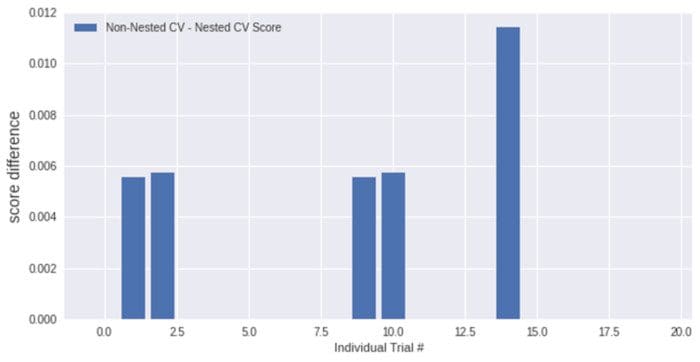
Final thoughts
While cross-validation is an industry-standard to assess generalization, it’s important to consider the problem at hand and potentially implement a more rigorous process to avoid a selection bias while choosing the final model. From personal experience, this is significatively more important when you’re dealing with small datasets and when the system is built to support non-trivial decisions.
Nested cross-validation is not a perfect process, it is computationally expensive, and it’s definitely not a panacea for poor model performance in production. However, in most scenarios, the process will allow you to get a more realistic view of the generalization capacity of each model.
You can find the notebook with all of the code from the article on GitHub.
Bio: Eduardo Martinez is a marketer with a postgraduate degree in business analytics. Currently at Arcalea, Eduardo consolidates data science frameworks with marketing processes.
Related: