Serving ML Models in Production: Common Patterns
Over the past couple years, we've seen 4 common patterns of machine learning in production: pipeline, ensemble, business logic, and online learning. In the ML serving space, implementing these patterns typically involves a tradeoff between ease of development and production readiness. Ray Serve was built to support these patterns by being both easy to develop and production ready.
By Simon Mo, Edward Oakes and Michael Galarnyk
This post is based on Simon Mo’s “Patterns of Machine Learning in Production” talk from Ray Summit 2021.
Over the past couple years, we've listened to ML practitioners across many different industries to learn and improve the tooling around ML production use cases. Through this, we've seen 4 common patterns of machine learning in production: pipeline, ensemble, business logic, and online learning. In the ML serving space, implementing these patterns typically involves a tradeoff between ease of development and production readiness. Ray Serve was built to support these patterns by being both easy to develop and production ready. It is a scalable and programmable serving framework built on top of Ray to help you scale your microservices and ML models in production.
This post goes over:
- What is Ray Serve
- Where Ray Serve fits in the ML Serving Space
- Some common patterns of ML in production
- How to implement these patterns using Ray Serve
What is Ray Serve?

Ray Serve is built on top of the Ray distributed computing platform, allowing it to easily scale to many machines, both in your datacenter and in the cloud.
Ray Serve is an easy-to-use scalable model serving library built on Ray. Some advantages of the library include:
- Scalability: Horizontally scale across hundreds of processes or machines, while keeping the overhead in single-digit milliseconds
- Multi-model composition: Easily compose multiple models, mix model serving with business logic, and independently scale components, without complex microservices.
- Batching: Native support for batching requests to better utilize hardware and improve throughput.
- FastAPI Integration: Scale an existing FastAPI server easily or define an HTTP interface for your model using its simple, elegant API.
- Framework-agnostic: Use a single toolkit to serve everything from deep learning models built with frameworks like PyTorch, Tensorflow and Keras, to Scikit-Learn models, to arbitrary Python business logic.
You can get started with Ray Serve by checking out the Ray Serve Quickstart.
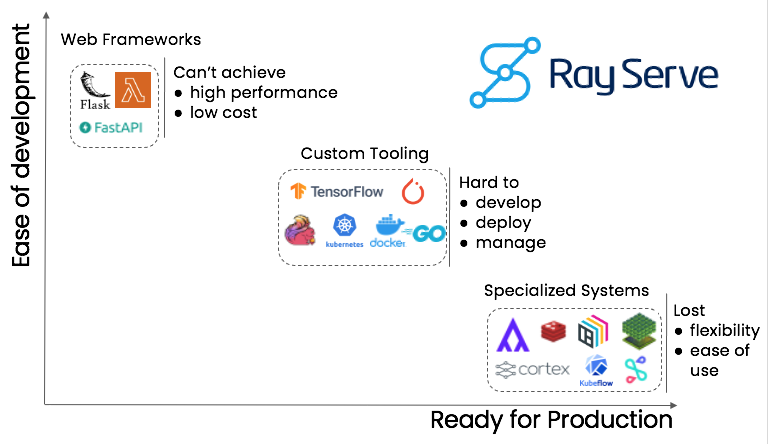
Where Ray Serve fits in the ML Serving Space
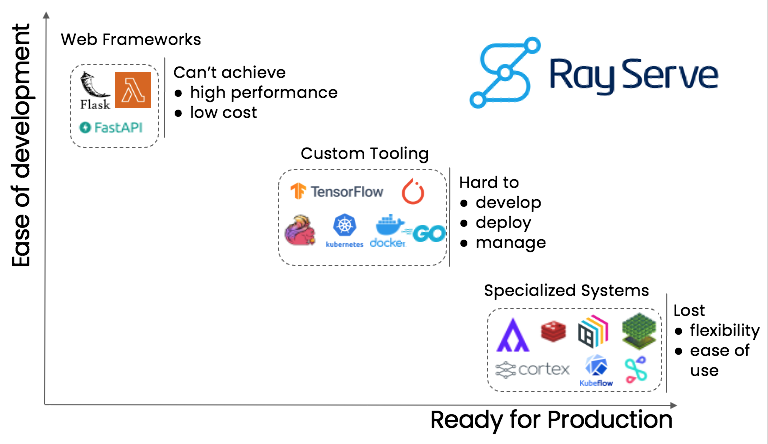
The image above shows that In the ML serving space, there is typically a tradeoff between ease of development and production readiness.
Web Frameworks
To deploy a ML service, people typically start with the simplest systems out of the box like Flask or FastAPI. However, even though they can deliver a single prediction well and work well in proofs of concept, they cannot achieve high performance and scaling up is often costly.
Custom Tooling
If web frameworks fail, teams typically transition to some sort of custom tooling by gluing together several tools to make the system ready for production. However, these custom toolings are typically hard to develop, deploy, and manage.
Specialized Systems
There is a group of specialized systems for deploying and managing ML models in production. While these systems are great at managing and serving ML models, they often have less flexibility than web frameworks and often have a high learning curve.
Ray Serve
Ray Serve is a web framework specialized for ML model serving. It aspires to be easy to use, easy to deploy, and production ready.
What makes Ray Serve Different?

There are so many tools for training and serving one model. These tools help you run and deploy one model very well. The problem is that machine learning in real life is usually not that simple. In a production setting, you can encounter problems like:
- Wrangling with infrastructure to scale beyond one copy of a model.
- Having to work through complex YAML configuration files, learn custom tooling, and develop MLOps expertise.
- Hit scalability or performance issues, unable to deliver business SLA objectives.
- Many tools are very costly and can often lead to underutilization of resources.
Scaling out a single model is hard enough. For many ML in production use cases, we observed that complex workloads require composing many different models together. Ray Serve is natively built for this kind of use case involving many models spanning multiple nodes. You can check out this part of the talk where we go in depth about Ray Serve’s architectural components.
Patterns of ML Models in Production
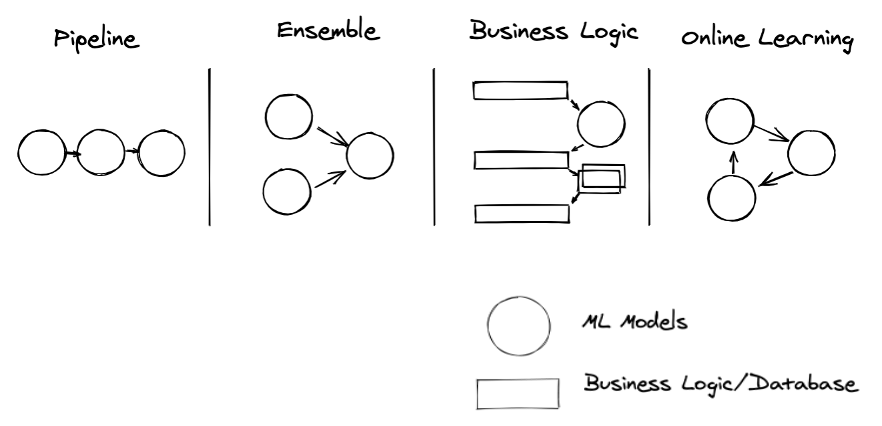
A significant portion of ML applications in production follow 4 model patterns:
- pipeline
- ensemble
- business logic
- online learning
This section will describe each of these patterns, show how they are used, go over how existing tools typically implement them, and show how Ray Serve can solve these challenges.
Pipeline Pattern
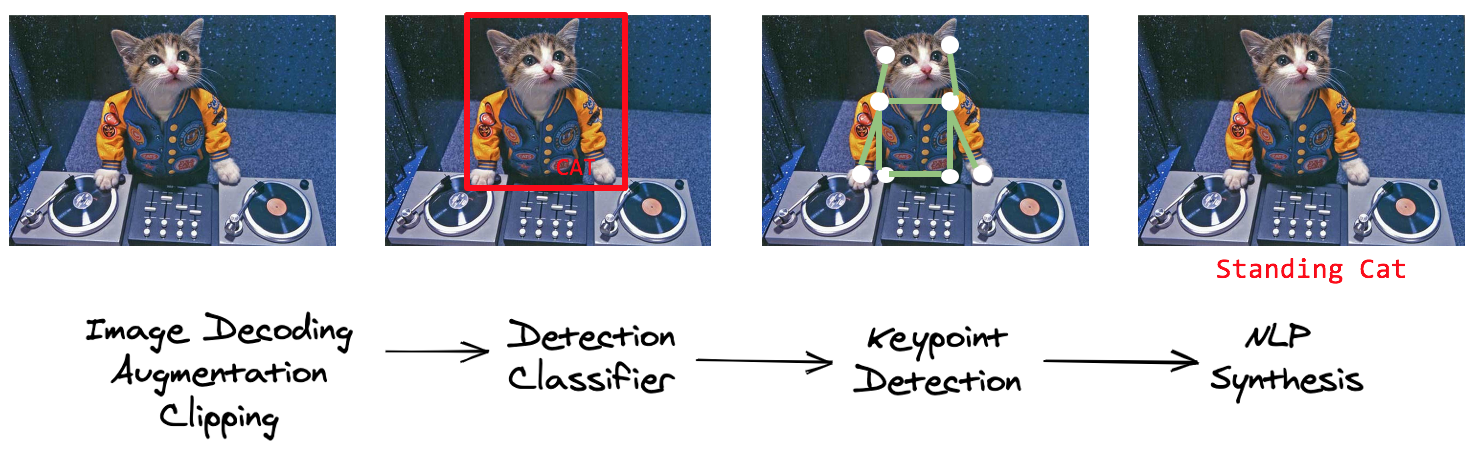
A typical computer vision pipeline
The image above shows a typical computer vision pipeline that uses multiple deep learning models to caption the object in the picture. This pipeline consists of the following steps:
1) The raw image goes through common preprocessing like image decoding, augmentation and clipping.
2) A detection classifier model is used to identify the bounding box and the category. It's a cat.
3) The image is passed into a keypoint detection model to identify the posture of the object. For the cat image, the model could identify key points like paws, neck, and head.
4) Lastly, an NLP synthesis model generates a category of what the picture shows. In this case, a standing cat.
A typical pipeline rarely consists of just one model. To tackle real-life issues, ML applications often use many different models to perform even simple tasks. In general, pipelines break a specific task into many steps, where each step is conquered by a machine learning algorithm or some procedure. Let’s now go over a couple pipelines you might already be familiar with.
Scikit-Learn Pipeline
Pipeline([(‘scaler’, StandardScaler()), (‘svc’, SVC())])
scikit-learn’s pipeline can be used to combine multiple “models” and “processing objects” together.
Recommendation Systems
[EmbeddingLookup(), FeatureInteraction(), NearestNeighbors(), Ranking()]
There are common pipeline patterns in recommendation systems. Item and video recommendations like those that you might see at Amazon and YouTube, respectively, typically go through multiple stages like embedding lookup, feature interaction, nearest neighbor models, and ranking models.
Common Preprocessing
[HeavyWeightMLMegaModel(), DecisionTree()/BoostingModel()]
There are some very common use cases where some massive ML models are used to take care of common processing for text or images. For example, at Facebook, groups of ML researchers at FAIR create state of the art heavyweight models for vision and text. Then different product groups create downstream models to tackle their business use case (e.g. suicide prevention) by implementing smaller models using random forest. The shared common preprocessing step oftentimes are materialized into a feature store pipeline.
General Pipeline Implementation Options

Before Ray Serve, implementing pipelines generally meant you had to choose between wrapping your models in a web server or using many specialized microservices.
In general, there are two approaches to implement a pipeline: wrap your models in a web server or use many specialized microservices.
Wrap Models in a Web Server
The left side of the image above shows models that get run in a for loop during the web handling path. Whenever a request comes in, models get loaded (they can also be cached) and run through the pipeline. While this is simple and easy to implement, a major flaw is that this is hard to scale and not performant because each request gets handled sequentially.
Many Specialized Microservices
The right side of the image above shows many specialized microservices where you essentially build and deploy one microservice per model. These microservices can be native ML platforms, Kubeflow, or even hosted services like AWS SageMaker. However, as the number of models grow, the complexity and operational cost drastically increases.
Implementing Pipelines in Ray Serve
@serve.deployment
class Featurizer: …
@serve.deployment
class Predictor: …
@serve.deployment
class Orchestrator
def __init__(self):
self.featurizer = Featurizer.get_handle()
self.predictor = Predictor.get_handle()
async def __call__(self, inp):
feat = await self.featurizer.remote(inp)
predicted = await self.predictor.remote(feat)
return predicted
if __name__ == “__main__”:
Featurizer.deploy()
Predictor.deploy()
Orchestrator.deploy()
In Ray Serve, you can directly call other deployments within your deployment. In this code above, there are three deployments. Featurizer and Predictor are just regular deployments containing the models. The Orchestrator receives the web input, passes it to the featurizer process via the featurizer handle, and then passes the computed feature to the predictor process. The interface is just Python and you don’t need to learn any new framework or domain-specific language.
Ray Serve achieves this with a mechanism called ServeHandle which gives you a similar flexibility to embed everything in the web server, without sacrificing performance or scalability. It allows you to directly call other deployments that live in other processes on other nodes. This allows you to scale out each deployment individually and load balance calls across the replicas.
If you would like to get a deeper understanding of how this works, check out this section of Simon Mo’s talk to learn about Ray Serve’s architecture. If you would like an example of a computer vision pipeline in production, check out how Robovision used 5 ML models for vehicle detection.
Ensemble Pattern
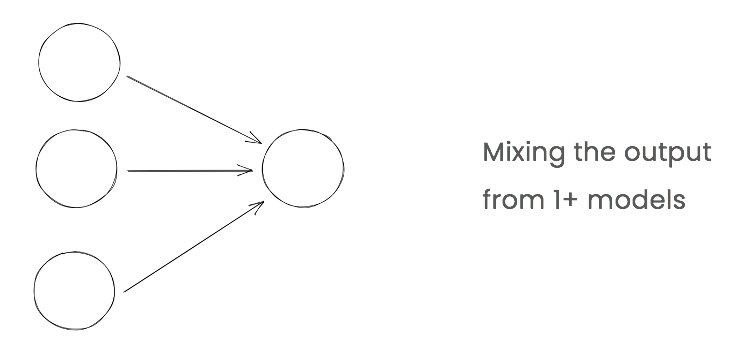
In a lot of production use cases, a pipeline is appropriate. However, one limitation of pipelines is that there can often be many upstream models for a given downstream model. This is where ensembles are useful.
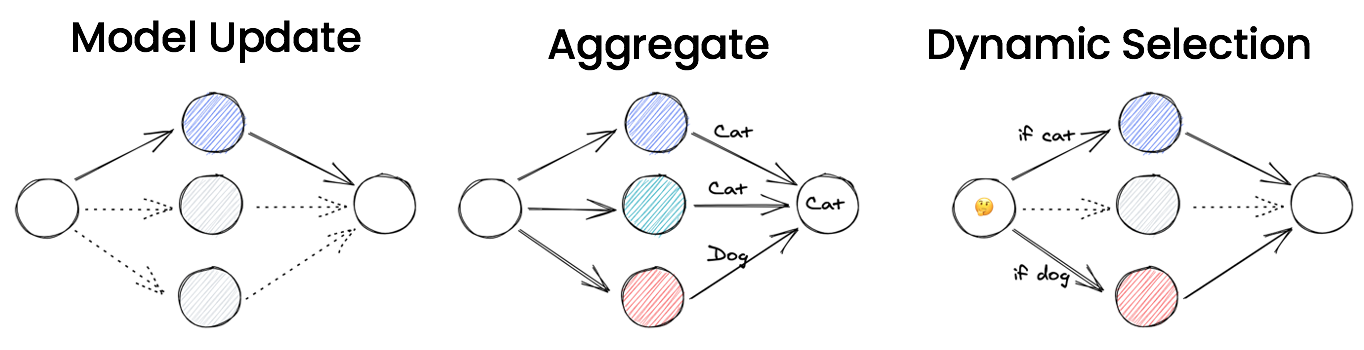
Ensemble Use Cases
Ensemble patterns involve mixing output from one or more models. They are also called model stacking in some cases. Below are three use cases of ensemble patterns.
Model Update
New models are developed and trained over time. This means there will always be new versions of the model in production. The question becomes, how do you make sure the new models are valid and performant in live online traffic scenarios? One way to do this is by putting some portion of the traffic through the new model. You still select the output from the known good model, but you are also collecting live output from the newer version of the models in order to validate it.
Aggregation
The most widely known use case is for aggregation. For regression models, outputs from multiple models are averaged. For classification models, the output will be a voted version of multiple models’ output. For example, if two models vote for cat and one model votes for dog, then the aggregated output will be cat. Aggregation helps combat inaccuracy in individual models and generally makes the output more accurate and “safer”.
Dynamic Selection
Another use case for ensemble models is to dynamically perform model selection given input attributes. For example, if the input contains a cat, model A will be used because it is specialized for cats. If the input contains a dog, model B will be used because it is specialized for dogs. Note that this dynamic selection doesn’t necessarily mean the pipeline itself has to be static. It could also be selecting models given user feedback.
General Ensemble Implementation Options

Before Ray Serve, implementing ensembles generally meant you had to choose between wrapping your models in a web server or using many specialized microservices.
Ensemble implementations suffer the same sort of issues as pipelines. It is simple to wrap models in a web server, but it is not performant. When you use specialized microservices, you end up having a lot of operational overhead as the number of microservices scale with the number of models.
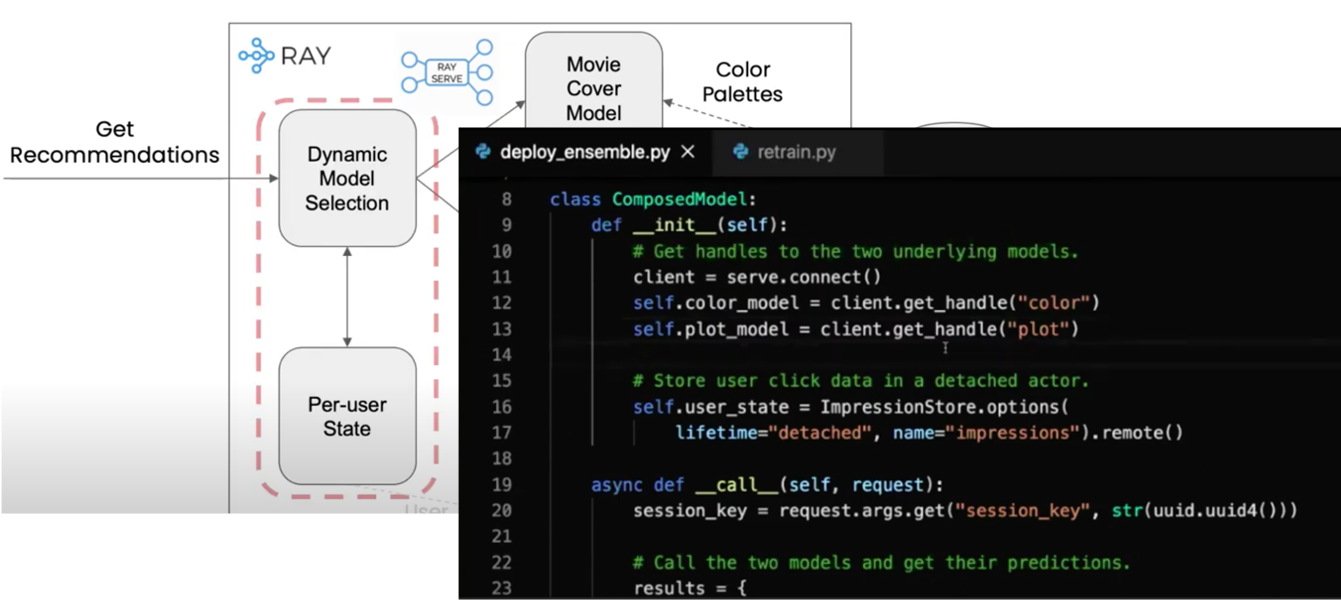
Ensemble example from the 2020 Anyscale demo
With Ray Serve, the kind of pattern is incredibly simple. You can look at the 2020 Anyscale demo to see how to utilize Ray Serve’s handle mechanism to perform dynamic model selection.
Another example of using Ray Serve for ensembling is Wildlife Studios combining output of many classifiers for a single prediction. You can check out how they were able to serve in-game offers 3x faster with Ray Serve.
Business Logic Pattern
Productionizing machine learning will always involve business logic. No models can stand-alone and serve requests by themselves. Business logic patterns involve everything that’s involved in a common ML task that is not ML model inference. This includes:
- Database lookups for relational records
- Web API calls for external services
- Feature store lookup for pre-compute feature vectors
- Feature transformations like data validation, encoding, and decoding.
General Business Logic Implementation Options

The pseudocode for the web handler above does the following things:
- It loads the model (let’s say from S3)
- Validates the input from the database
- Looks up some pre-computed features from the feature store.
Only after the web handler completes these business logic steps are the inputs passed through to ML models. The problem is that the requirements of model inference and business logic lead to the server being both network bounded and compute bounded. This is due to the model loading step, database lookup, and feature store lookups being network bounded and I/O heavy as well as the model inference being compute bound and memory hungry. The combination of these factors lead to an inefficient utilization of resources. Scaling will be expensive.
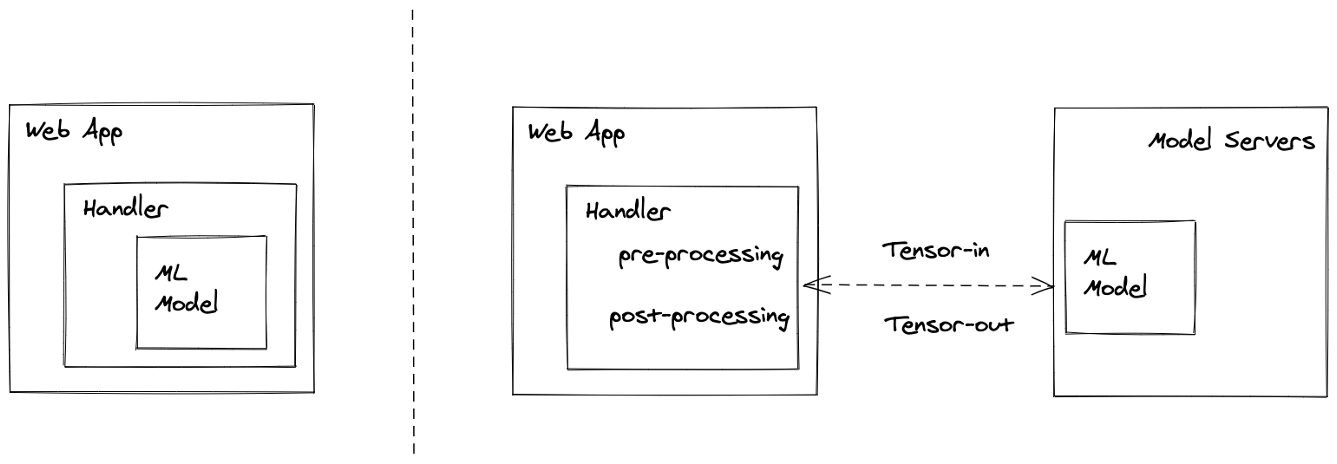
Web handler approach (left) and microservices approach (right)
A common way to increase utilization is to split models out into model servers or microservices.
The web app is purely network bounded while the model servers are compute bounded. However, a common problem is the interface between the two. If you put too much business logic into the model server, then the model servers become a mix of network bounded and compute bounded calls.
If you let the model servers be pure model servers, then you have the “tensor-in, tensor-out” interface problem. The input types for model servers are typically very constrained to just tensors or some alternate form of it. This makes it hard to keep the pre-processing, post-processing, and business logic in sync with the model itself.
It becomes hard to reason about the interaction between the processing logic and the model itself because during training, the processing logic and models are tightly coupled, but when serving, they are split across two servers and two implementations.
Neither the web handler approach nor the microservices approach is satisfactory.
Implementing Business Logic in Ray Serve
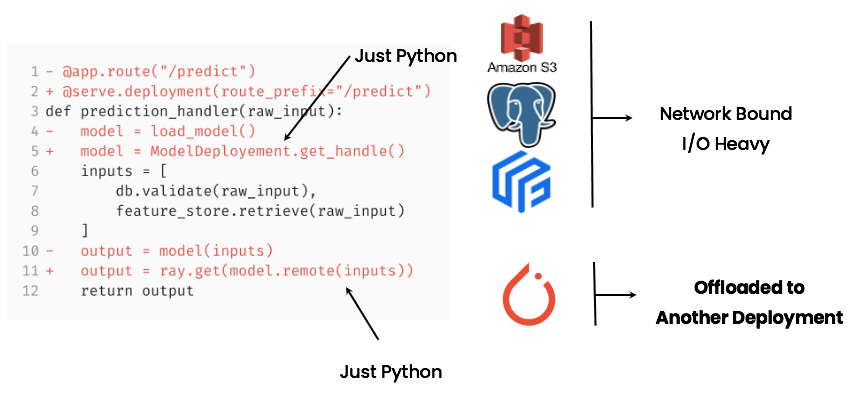
Business Logic in Ray Serve
With Ray Serve, you just have to make some simple changes to the old web server to alleviate the issues described above. Instead of loading the model directly, you can retrieve a ServeHandle that wraps the model, and offload the computation to another deployment. All the data types are preserved and there is no need to write “tensor-in, tensor-out” API calls--you can just pass in regular Python types. Additionally, the model deployment class can stay in the same file, and be deployed together with the prediction handler. This makes it easy to understand and debug the code. model.remote looks like just a function and you can easily trace it to the model deployment class.
In this way, Ray Serve helps you split up the business logic and inference into two separation components, one I/O heavy and the other compute heavy. This allows you to scale each piece individually, without losing the ease of deployment. Additionally, because model.remote is just a function call, it’s a lot easier to test and debug than separate external services.
Ray Serve FastAPI Integration
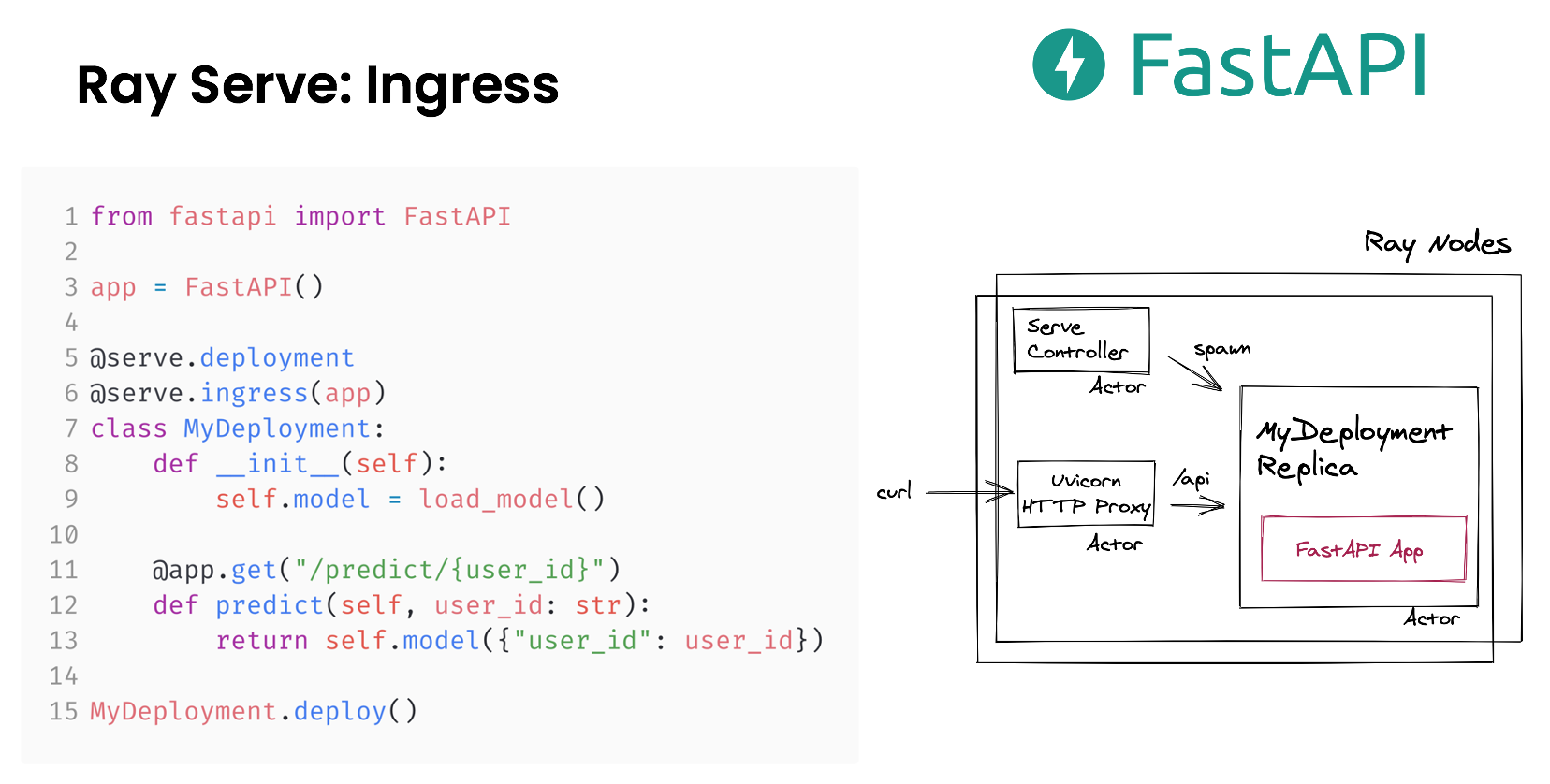
Ray Serve: Ingress with FastAPI
An important part of implementing business logic and other patterns is authentication and input validation. Ray Serve natively integrates with FastAPI, which is a type safe and ergonomic web framework. FastAPI has features like automatic dependency injection, type checking and validation, and OpenAPI doc generation.
With Ray Serve, you can directly pass the FastAPI app object into it with @serve.ingress. This decorator makes sure that all existing FastAPI routes still work and that you can attach new routes with the deployment class so states like loaded models, and networked database connections can easily be managed. Architecturally, we just made sure that your FastAPI app is correctly embedded into the replica actor and the FastAPI app can scale out across many Ray nodes.
Online Learning
Online learning is an emerging pattern that’s become more and more widely used. It refers to a model running in production that is constantly being updated, trained, validated and deployed. Below are three use cases of online learning patterns.
Dynamically Learn Model Weights
There are use cases for dynamically learning model weights online. As users interact with your services, these updated model weights can contribute to a personalized model for each user or group.
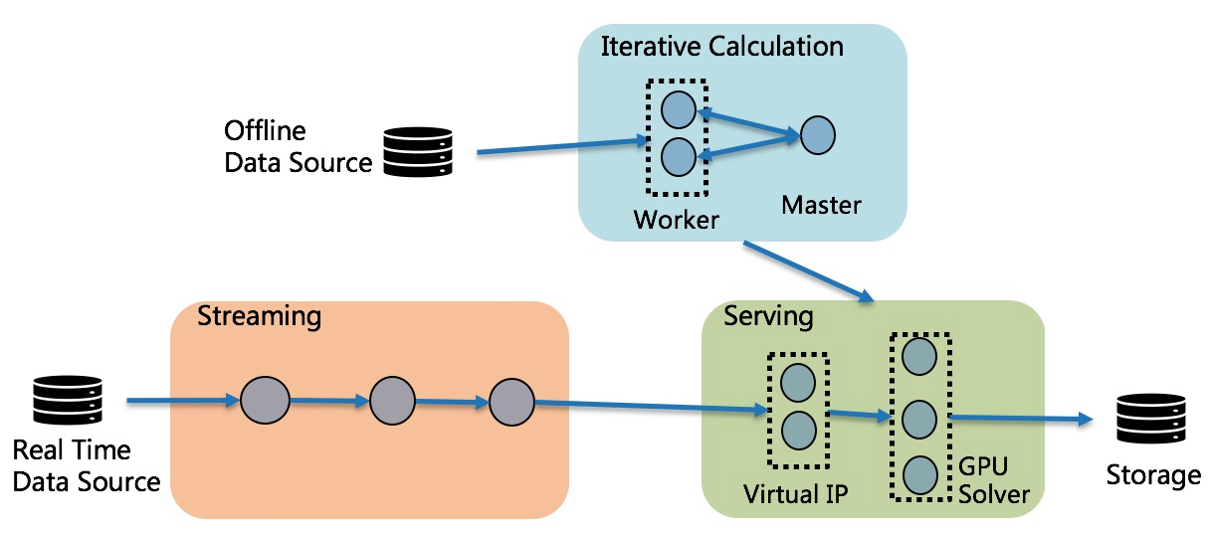
Online Learning example at Ant Group (image courtesy of Ant Group)
One case study of online learning consists of an online resource allocation business solution at Ant Group. The model is trained from offline data, then combined with real time streaming data source, and then served live traffic. One thing to note is that online learning systems are drastically more complex than their static serving counterparts. In this case, putting models in the web server, or even splitting it up into multiple microservices, would not help with the implementation.
Dynamically Learn Parameters to Orchestrate Models
There are also use cases for learning parameters to orchestrate or compose models, for example, learning which model a user prefers. This manifests often in model selection scenarios or contextual bandit algorithms.
Reinforcement Learning
Reinforcement learning is the branch of machine learning that trains agents to interact with the environment. The environment can be the physical world or a simulated environment. You can learn about reinforcement learning here and see how you can deploy a RL model using Ray Serve here.
Conclusion
Ray Serve is easy to develop and production ready.
This post went over 4 main patterns of machine learning in production, how Ray Serve can help you natively scale and work with complex architectures, and how ML in production often means many models in production. Ray Serve is built with all of this in mind on top of the distributed runtime Ray. If you’re interested in learning more about Ray, you can check out the documentation, join us on Discourse, and check out the whitepaper! If you're interested in working with us to make it easier to leverage Ray, we're hiring!
Original. Reposted with permission.
Related:
- Getting Started with Distributed Machine Learning with PyTorch and Ray
- How to Speed up Scikit-Learn Model Training
- How to Build a Data Science Portfolio