Design Patterns in Machine Learning for MLOps
This article outlines some of the most common design patterns encountered when creating successful Machine Learning solutions.

Photo by Juliana Malta on Unsplash
Introduction
Design Patterns are a set of best practices and reusable solutions to common problems. Data Science and other disciplines such as Software Development, Architecture, etc. are constituted by a large number of recurring problems and therefore trying to categories the most common ones and provide different forms of blueprints to easily recognize them and solve them could provide an immense benefit to the wider community.
The idea of using Design Patterns in Software Development was first brought by Erich Gamma et. al. in “Design Patterns: Elements of Reusable Object-Oriented Software” [1] and recently applied to Machine Learning processes thanks to Sara Robinson et. al. in “Machine Learning Design Patterns” [2].
As part of this article, we are now going to discover the different Design Patterns constituting MLOps. MLOps (Machine Learning -> Operations) is a set of processes designed to transform experimental Machine Learning models into productionized services ready to make decisions in the real world. At his core, MLOps is based on the same principles of DevOps but with an additional focus on data validation and continuous training/evaluation (Figure 1).
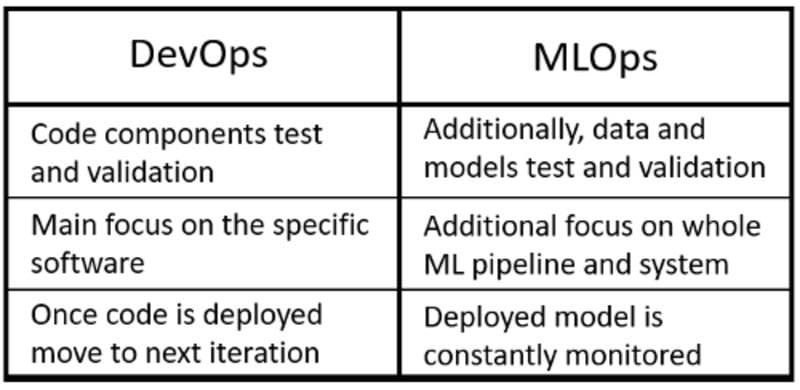
Figure 1: DevOps and MLOps (Image by Author).
Some of the main benefits of MLOps are:
- Improved time to market (faster deployments).
- Increased model robustness (easier to identify data drift, retraining models, etc.).
- More flexibility to train/compare different ML models.
On the other hand, DevOps emphasizes two key concepts for software development: Continuous Integration (CI) and Continuous Delivery (CD). Continuous Integration focuses on using a central repository as a means for teams to collaborate on a project and automating as much as possible the process of adding, testing and validating new code as it gets added by the different team members. In this way, it is possible to test at any time if the different parts of an application can correctly communicate with each other and identify as soon as possible any form of error. Continuous Delivery focuses instead on smoothly updating software deployments, trying to avoid as much as possible any form of downtime.
MLOps Design Patterns
Workflow Pipeline
Machine Learning (ML) projects are constructed by many different steps (Figure 2).

Figure 2: ML Project Key Steps (Image by Author).
When prototyping a new model, it can be quite common to start by using a single script (monolithic) in order to code the whole process but as the project might increase in complexity and more team members might start getting involved, it could then become necessary to divide each different step of the project into a separate script (microservice). Some of the benefits of taking this approach could then be:
- Easier to experiment with changes in the orchestration of the different steps.
- Make the project scalable by definition (new steps can be easily added and removed).
- Each team member can be able to focus on a different step in the flow.
- Separated artefacts can be created for each different step.
The Workflow Pipeline design pattern, aims to define a blueprint in order to create ML Pipelines. ML Pipelines can be represented as a Directed Acyclic Graph (DAG), in which each of its steps is characterized by a container (Figure 3).
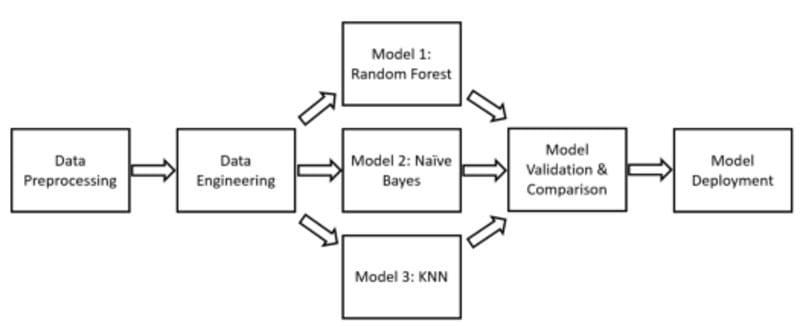
Figure 3: Directed Acyclic Graph Example (Image by Author).
Following this structure, it could then be possible to create reproducible and manageable ML processes. Some of the benefits of using Workflow Pipelines could then be:
- By adding and removing steps in the flow, complex experiments can be created to test different preprocessing techniques, machine learning models and hyperparameters.
- Saving individually the output of each different step, it can be possible to avoid re-running steps at the beginning of the pipeline if any change has been applied just in the final steps (therefore saving time and computational power).
- In case of errors, it can be easy to identify which step might need to be updated.
- Once deployed to production using CI/CD, pipelines can be scheduled to re-run based on different factors such as: time interval, external triggers, changes in ML metrics, etc.
Feature Store
Feature Stores are a data management layer designed for Machine Learning processes (Figure 4). The main use of this design pattern is to simplify how organizations manage and use Machine Learning features. This is done, by creating some form of central repository used by a company to store all the features which have ever been created for ML processes. In this way, if Data Scientists might need the same subset of features for different ML projects, they would not have to go through the process of converting raw data into processed features multiple times (which could be time expensive). Two of the most common open-source Feature Store solutions are Feast and Hopsworks.
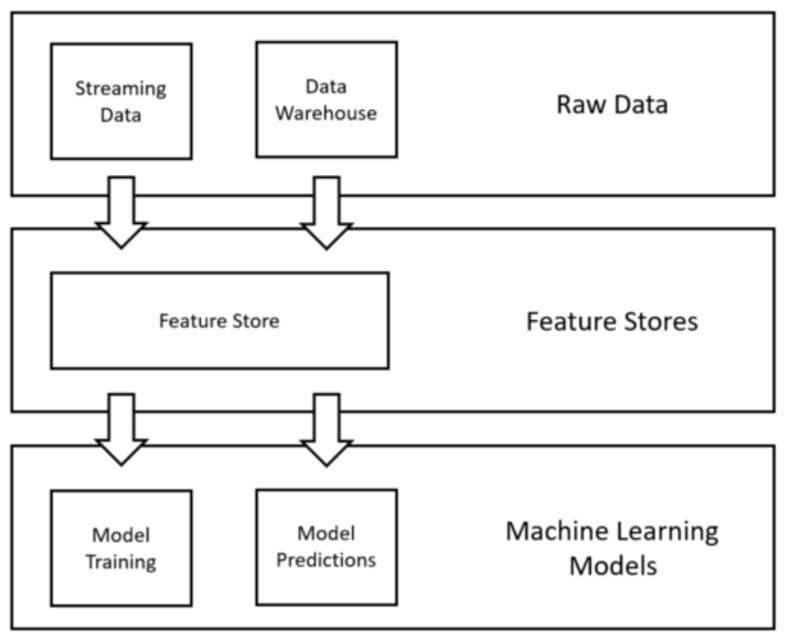
Figure 4: Feature Store Design Pattern (Image by Author).
Additional information about Feature Stores can be found in my previous article.
Transform
The Transform design pattern aims to make it easier to deploy and maintain Machine Learning models in production by keeping inputs, features and transforms as separate entities (Figure 5). Raw data needs in fact to usually go through different preprocessing steps in order to then be used as input for a Machine Learning model and some of these transformations needs then to be saved in order to be reused when preprocessing data for inference.
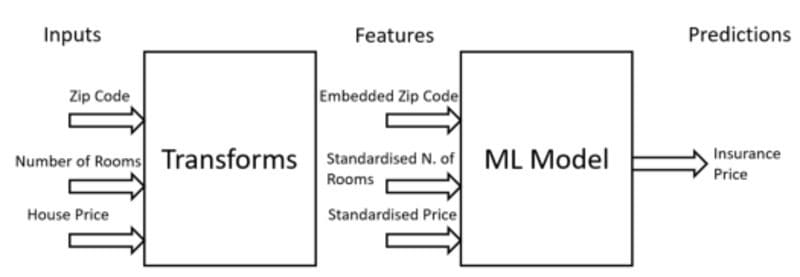
Figure 5: Inputs and Features relationship (Image by Author).
For example, normalization/standardization techniques are commonly applied to numerical data before training an ML model in order to deal with outliers and make the data look like more a gaussian distribution. These transformations should then be saved so that they could be reused in the future when new data is made available for inference. If these transformations would not be saved, we would then create a data skew between training and serving with the input data provided for inference having a different distribution compared to the input data used to train the ML model.
An alternative solution in order to avoid any type of skew between training and serving is to make use of the Feature Store design pattern.
Multimodal Input
Different types of data such as images, text, numbers, etc. can be used in order to train ML models, although some types of models can only accept a specific type of input data. For example, the Resnet-50 is able to take just images as input data, while other ML models such as KNN (K Nearest Neighbor) are able to take just numeric data as input.
In order to try to solve an ML problem, it might be necessary to use different forms of input data. In this case, some form of transformation needs to be applied in order to create a common representation of all our different types of input data (Multimodal Input design pattern). As an example, let us imagine we are provided with a combination of text, numeric and categorical data. In order to train an ML model, we could then make use of techniques such as sentiment analysis, bag of words or word embeddings to convert the text data into a numeric format and one-hot-encoding to convert the categorical data as well. In this way, we would then have all our data in the same format (numeric), ready to be used for training.
Cascade
In some scenarios, it cannot be possible to solve an ML problem using just a single ML model. In this case, it would then be necessary to create a series of ML models which are dependent on each other in order to achieve an end goal. As an example, let us imagine we are trying to predict what kind of items to recommend to a user (Figure 6). To solve this problem, we want first to create a model able to predict if the user is more or less than 18 years old and then depending on the response from this model route our flow to one of two different ML recommendation engines (one designed to recommend products for above 18 users and the other one to recommend products to under 18 users).
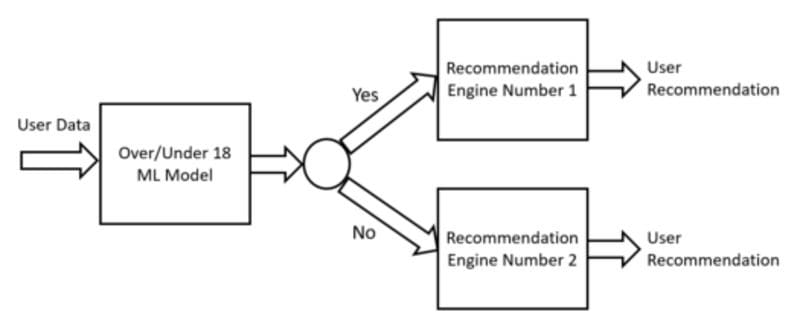
Figure 6: Cascade Design Pattern (Image by Author).
In order to create this Cascade of ML models, we would then need to make sure to train them together. In fact, because of their dependency on one another, if the first model would change (without updating the other models) this could then lead to instability to the subsequent models. This type of process could then be automated using the Workflow Pipeline design pattern.
Conclusion
In this article, we explored some of the most common Design Patterns underpinning MLOps. In case you are interested in finding out more about Design Patterns in Machine Learning, additional information is available in this talk by Valliappa Lakshmanan at AIDevFest20 and the “Machine Learning Design Patterns” book public GitHub repository.
Contacts
If you want to keep updated with my latest articles and projects follow me on Medium and subscribe to my mailing list. These are some of my contacts details:
Bibliography
[1] “Design Patterns: Elements of Reusable Object-Oriented Software” (Addison-Wesley, 1995). Accessed at: www.uml.org.cn/c%2B%2B/pdf/DesignPatterns.pdf
[2] “Machine Learning Design Patterns” (Sara Robinson et. al., 2020) Accessed at: https://www.oreilly.com/library/view/machine-learning-design/9781098115777/
Pier Paolo Ippolito is a Data Scientist and MSc in Artificial Intelligence graduate from the University of Southampton. He has a strong interest in AI advancements and machine learning applications (such as finance and medicine). Connect with him on Linkedin.
Original. Reposted with permission.