How to MLOps like a Boss: A Guide to Machine Learning without Tears
If you have ever emailed a .pickle file to engineers for deployment, this is for YOU!

Image by Editor
The MLOps market was estimated at $23.2billion in 2019 and is projected to reach $126 billion by 2025 due to rapid adoption.
Introduction
Many data science projects don’t see the light of the day. MLOps is a process that spans from the data stage to deployment stage and ensures the success of machine learning models. In this post, you will learn about the key stages in MLOps (from a data scientist’s perspective) along with some common pitfalls.
Motivation for MLOps
MLOps is a practice that focuses on operationalizing data science models. Usually, in most enterprises, data scientists are responsible for creating the modeling datasets, pre-processing the data, feature engineering, and finally building the model. Then the model is “thrown” over the wall to the engineering team to be deployed into the API/Endpoint. The science and engineering often times happen in silos, which leads to delays in deployment or incorrect deployments in the worst case.
MLOps addresses the challenge of deploying enterprise scale ML models accurately and quickly.
The data science equivalent of the saying “Easier said than done” should probably be “Easier built than deployed”.
MLOps can be the silver bullet to the difficulties enterprises face putting machine learning models into production. For those of us data scientists, the finding that ~90% of ML models don’t make it to production, should not come as a surprise. MLOps brings the discipline and process to the data science and engineering teams to ensure that they collaborate closely and continuously. This collaboration is crucial to ensure successful model deployment.
MLOps in a nutshell
For those familiar with DevOps, MLOps is to machine learning applications that DevOps is to software applications.
MLOps comes in multiple flavors depending on who you ask. However, there are a five key stages that are critical to a successful MLOps strategy. As a side note, a crucial element that needs to be a part of each of these stages is communication with stakeholders.
Problem framing
Understand the business problem inside out. This is one of the key steps to successful model deployment and usage. Engage with all the stakeholders at this stage to get buy-in for the project. It could be engineering, product, compliance etc.
Solution framing
Only and Only after the problem statement is hashed out, proceed to thinking about the “How”. Is machine learning required to tackle this business problem? At the onset, it might seem weird that as a data scientist, I am suggesting to steer away from machine learning. That’s only because with “great power comes great responsibility”. Responsibility in this case would be to make sure that the machine learning model is built, deployed and monitored carefully to ensure that it satisfies and continues to satisfy the business requirement. The timelines and resources should also be discussed at this stage with the stakeholders.
Data preparation
Once you have decided to go down the route of machine learning, start thinking of the “Data”. This stage includes steps such as data gathering, data cleaning, data transformation, feature engineering and labeling (for supervised learning). Here the adage that needs to be remembered is “garbage in garbage out”. This step is usually the most painstaking step in the process and is critical to ensure model success. Ensure to validate the data and features multiple times to make sure that they are aligned with the business problem. Document all your many assumptions that you take while creating a dataset. Ex: Are the outliers for a feature actually outliers?
Model building and analysis
In this stage, build and evaluate multiple models and select the model architecture that best solves the problem at hand. The chosen metric for optimization should reflect the business requirement. Today, there are numerous machine learning libraries that help expedite this step. Remember to log and track your experiments to ensure reproducibility of your machine learning pipeline.
Model serving and monitoring
Once we have the model object built from the previous stage, we need to think of how we are going to make it “useable” by our end-users. Response latency needs to be minimized while maximizing throughput. Some popular options to serve the model are - REST API endpoint, as a docker container on the cloud or on an edge device. We can’t yet celebrate once we have deployed the model object, as they are very dynamic in nature. For example, the data could drift in production causing model decay or there could be adversarial attacks on the model. We need to have a robust monitoring infrastructure in place for the machine learning application. Two things need to be monitored here:
- The health of the environment where we deploy (eg: load, usage, latency)
- The health of the model itself (eg: performance metrics, output distribution).
The cadence of the monitoring process also needs to be determined at this stage. Are you going to monitor your ML application daily, weekly or monthly?
Now, you have a robust machine learning application built, deployed and monitored. But alas, the wheel doesn’t stop spinning, as the above steps need to be iterated upon continuously.
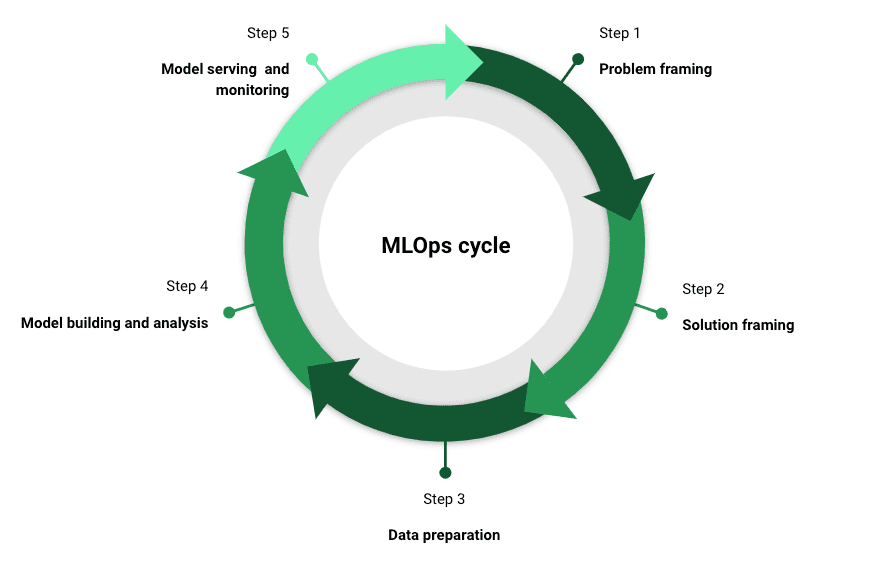
MLOps cycle for successful data science projects | Image by Author
FinTech Case Study
To put the above five stages in practice, let’s assume for this section that you are a data scientist at a FinTech company in charge of deploying a fraud model to detect fraudulent transactions.
In this case, start with a deep dive into the type of fraud (first party or third party?) you are trying to detect. How are transactions identified as fraud or not? Are they reported by the end user or do you have to use heuristics to identify fraud? Who would be consuming the model? Is it going to be used in real time or in batch mode? Answers to the above questions are crucial to solving this business problem.
Next, think about what solution best addresses this problem. Do you need machine learning to address this or can you start with a simple heuristic to tackle fraud? Is all the fraud coming from a small set of IP addresses?
If you decide to build a machine learning model (assume supervised learning for this case), you will need labels and features. How will you address missing variables? What about outliers? What’s the observation window for fraud labels? i.e how long does it take for a user to report a fraud transaction? Is there a data warehouse you can use to build features? Make sure to validate the data and features before moving ahead. This is also a good time to engage with the stakeholders about the direction of the project.
Once you have the data needed, build the model and perform the necessary analysis. Make sure the model metric is aligned with the business usage. (eg: could be recall at the first decile for this use-case). Does the chosen model algorithm satisfy the latency requirement?
Lastly, coordinate with engineering to deploy and serve the model. Because fraud detection is a very dynamic environment, where fraudsters strive to stay ahead of the system, monitoring is very crucial. Have a monitoring plan for both the data and the model. Measures such as the PSI (population stability index) are common to keep track of data drift. How often will you retrain the model?
You can now successfully create business value by reducing fraudulent transactions using machine learning (if needed!).
Conclusion
Hope that after reading this article, you see the benefits of implementing MLOps at your firm. To summarize, MLOps ensures that the data science team is:
- solving the right business problem
- using the right tool to solve the problem
- leveraging the dataset that represents the problem
- building the optimal machine learning model
- and finally deploying and monitoring the model to ensure continued success
However, be mindful of the common pitfalls to ensure that your data science project doesn’t become a tombstone in the data science graveyard! The fact that a data science application is a living and breathing thing should be remembered. The data and model need to be continuously monitored. AI governance should be considered right from the beginning and not as an afterthought.
With these principles in mind, I am confident that you can truly create business value leveraging machine learning (if needed!).
MLOps References
- Machine Learning Engineering for Production (MLOps)
- A Gentle Introduction to MLOps
- MLOps Practices for Data Scientists
- MLOps: The Upcoming Shining Star
Natesh Babu Arunachalam is a data science leader at Mastercard, currently focused on building innovative AI applications using open banking data.