Machine Learning Is Not Like Your Brain Part 6: The Importance of Precise Synapse Weights and the Ability to Set Them Quickly
In Part Six, I’ll show how limitations in synapses are even more of a problem. Precise synapse weights and the ability to set them quickly to a specific value are crucial to ML and biological neurons offer neither.
As far as we know, the weight of a synapse can only be changed by near-concurrent firing of the two neurons it connects. This is completely at odds with the fundamental architecture of ML’s backpropagation algorithm.
You could think of backpropagation as a little man sitting on the sidelines of a neural network who looks at the network output, compares it to the desired output, and then dictates new weights for the synapses within the network. In a biological system, there is no mechanism to dictate the weight of any specific synapse. You might try to increase the synapse weight by firing the two neurons it connects, but there is no way to do that either. You can’t just request to fire neurons 1000 and 1001 to increase the synapse between them because there is no way to fire a specific neuron in the network.
The only mechanism we’re sure of to adjust a synapse weight is called Hebbian Learning. It is the mechanism which is often whimsically expressed as, “Neurons which fire together, wire together.” But as in all things biological, it’s not as simple as that. Studies in “synaptic plasticity” yield curves such as those in the Figures which show that to strengthen a synapse connecting a source neuron to a target neuron, the source needs to fire shortly before the target. To reduce a synapse weight, the target must fire shortly before the source. This makes overall sense in that if a neuron contributes to another’s firing, the synapse connecting the two should be strengthened and vice versa.
There are a few more issues to note in the diagrams. First, although the overall concept is summarized in Figure B, Figure A shows a large amount of scatter in the observed data. This means that the ability to set a synapse to any specific value is very limited, as has been confirmed with simulation.
You can also observe that to make any substantive change in a synapse weight takes a number of repetitions. Even in a theoretical environment (without the scatter), you can conclude that the greater precision you need in a synapse value, the longer it will take to set it. For example, if you’d like a synapse to take one of 256 different values, you could define that each enhancing spike pair would increase the weight by 1/256th. It might take 256 spike pairs (to the source and target) to set the weight. At the leisurely speed of biological neurons, this would take a full second.
Imagine building a computer where a single memory write of one byte takes about a second. Further, imagine the support circuitry needed to set a value of x, arranging for exactly x spikes to the source and target neurons. This is assuming it started at a weight of 0 which is yet another issue because there is no way to know the current weight of any synapse. Finally, imagine how any use of the network containing this synapse would modify the synapse weight so such a system couldn’t store accurate values anyway. The whole concept of storing specific values in specific synapses is completely implausible.
There’s another way to look at it which makes a great deal more sense. Consider a synapse to be a binary device with a value of 0 or 1 (or -1 in the case of an inhibitory synapse). Now, the specific weight of the synapse represents the importance of that synapse and the likelihood of forgetting the data bit it represents. If we think in terms of neurons firing bursts of spikes (perhaps 5), then any weight over .2 represents a 1 and any weight below represents a 0. Such a system can learn in a single burst and is immune to random changes in memory content. This is a completely plausible scenario, but it is also completely at odds with modern Machine Learning Approaches.
Having thusfar focused on things the ML and perceptrons can do which neurons cannot, I’ll turn the tables in Part 7 of this series and describe a few things at which neurons are particularly good.
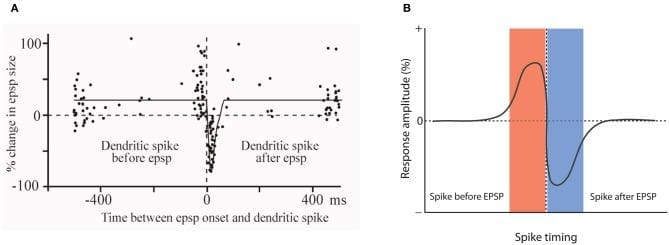
Figure A: Showing how the relative spike timings of source and target neurons influence a synapse weight. Figure B: An idealized representation of Hebbian learning useable in simulation. From: Piochon, Claire & Kruskal, Peter & Maclean, Jason & Hansel, Christian. (2012). Non-Hebbian Spike-Timing Dependent Plasticity in Cerebellar Circuits. Frontiers in neural circuits. 6. 124. 10.3389/fncir.2012.00124.
For more information, visit https://www.youtube.com/watch?v=jdaAKy-XkA0
Charles Simon is a nationally recognized entrepreneur and software developer, and the CEO of FutureAI. Simon is the author of Will the Computers Revolt?: Preparing for the Future of Artificial Intelligence, and the developer of Brain Simulator II, an AGI research software platform. For more information, visit here.