Prioritizing Data Science Models for Production
Statistical performance metrics aren’t enough to pick the right models to bring to market.

Photo by airfocus on unsplash.com
Very few businesses have unconstrained budgets for data science. The dollars for people, technology, analytic environments, and platforms are often much smaller than the corporate appetite for knowledge. In one company where I worked, the wish list for new analytic models would have required doubling our research staff, something that was clearly impossible.
Therese Gorski, the leader of several prioritization efforts, told me that the prioritization requirement is common in many product management organizations. It is often part of a larger process of vetting many ideas for offerings to bring to market. She said it is therefore useful to manage the prioritization process like any other investment in product development.
In this post I propose several criteria for companies to consider as they allocate scarce resources for data science work. My advice is to discuss these with people in every department involved in producing, marketing, selling, financing, supporting, or maintaining corporate offerings. Insights from company staff should come from all levels, not just leadership. This should be supplemented by insights from external stakeholders who would be affected by each model. Broad input will help maximize client utility, increasing sales and profits for them and your firm. Broad input will also increase the social value of your offerings.
A Dozen Criteria for Consideration
The criteria included in the following table have been inspired by Therese and colleagues at several companies, and by recent literature about attributes that make models useful and which pitfalls to avoid. Some of these criteria can be weighed prior to production; others address models that have already been produced.
Model attributes should be weighed before and after production because it may not become clear until late in the training process, or even afterward, whether any model is likely to be or remain useful. Moreover, new models typically compete for limited funding with models that have been sold for a long time, but which require periodic yet significant investments to maintain or update. Thus, it is important to consider how much every model is likely to contribute to business success. This requires weighing a variety of criteria and perspectives when ranking the utility of investing or continuing to invest in data science models.
With all this in mind, the following table lists twelve criteria for consideration. A file like this can be circulated to stakeholders and staff, so ratings on each criterion can be gathered from many people and then tallied for discussion.
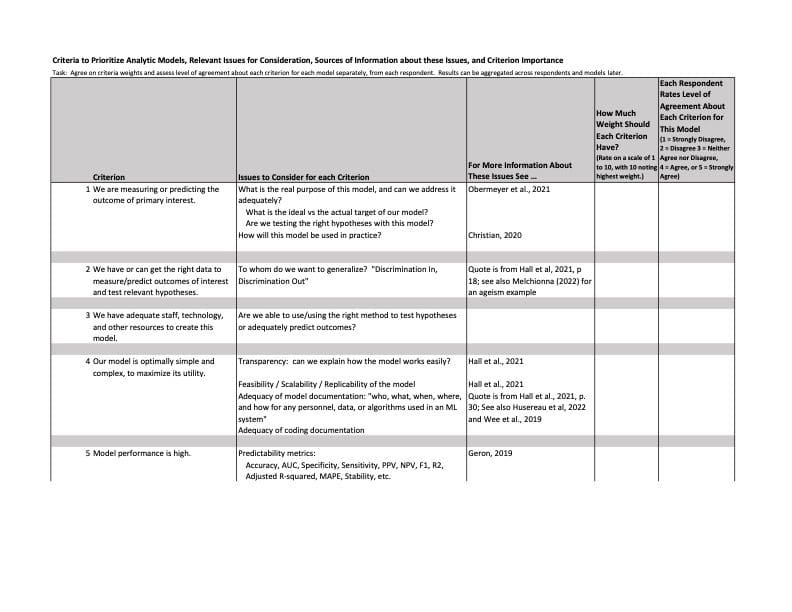
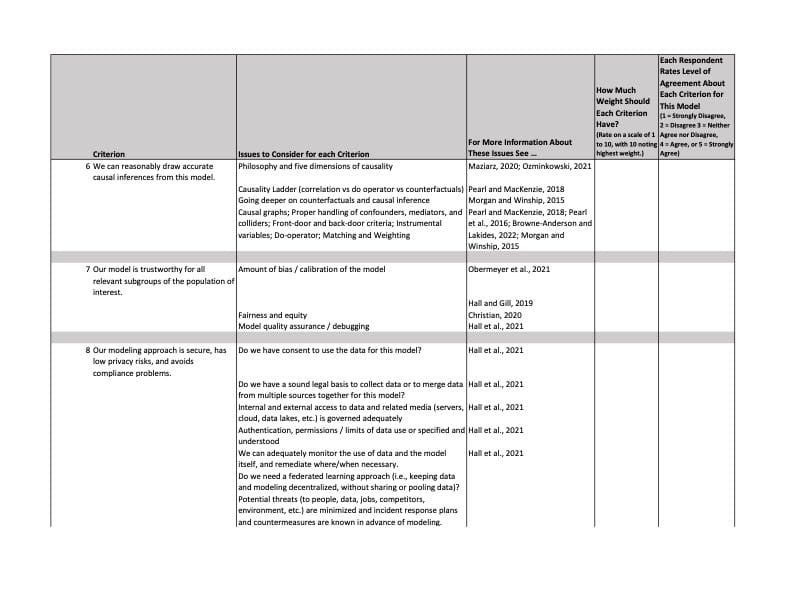
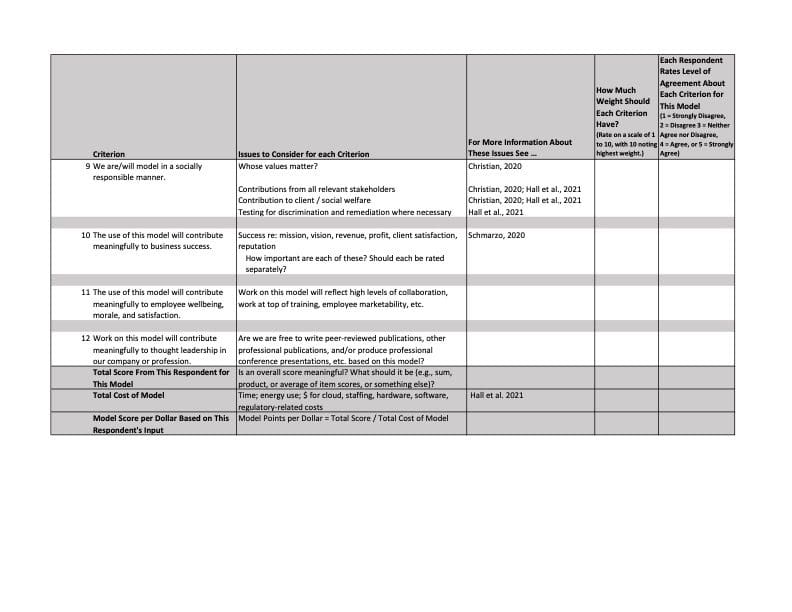
As you can see in the table, these dozen criteria take the form of declarative statements, and the task for each respondent is to note his or her level of agreement with each statement about each model presented to them. To keep things simple, I assume levels of agreement range from 1 (strongly disagree) to 5 (strongly agree). Using the same range increases the reliability of the results by reducing the variance in the responses; it also makes each statement easier to interpret.
Another important task is to weigh the importance of each criterion. Here the focus is on the criteria, not the models, and the excel file includes a column to specify the weight of each criterion. Do your business stakeholders want to assign equal importance to each one, or do they think some criteria are more important than others, requiring higher weights? This discussion is likely to be illuminating and controversial, and there are three options worth considering. Some may think weighting should be discussed after the level of agreement data are collected. This would promote independence between criteria weight and levels of agreement, meaning that one is less likely to influence the other. Others may disagree and reverse the order, first rating the importance of each criterion and then assessing the level of agreement about each criterion for each model. A third option, as implied by the table, is to query stakeholders about the weights to give to each criterion at the same time level of agreement is assessed, then use the results from all respondents to collectively decide how much weight to provide to each criterion. Use whatever option works better for your organization. If you are not sure which approach is better, experiment with different approaches for different independent, random subsets of raters, or try different approaches over time, to help decide which one is better for you.
Scoring Models
Once these activities have been completed and ratings for each model are available from all respondents, it is time to score each model. The score for each model can be calculated from each respondent, based on the product of the criterion weights agreed to by everyone and the respondent’s levels of agreement with each criterion:
Total Score from Respondent A =  criterion weight * level of agreement
criterion weight * level of agreement
The summation goes from 1 to 12 because there are twelve criteria for each model. As an example, assume Respondent A strongly agrees with each criterion and that each criterion is equally weighted with a value of 1.0. Then his or her score would be equal to 60 (i.e., as 12 criteria multiplied by a value of 5, indicating strong agreement for each one). Most respondents will vary their scores from 1 to 5, making the criteria weights really important to consider.
Once the scores from each respondent are obtained for each model, an overall model score can be obtained, simply by adding or averaging the scores from all the respondents. These data can be presented and compared in another table. Means, medians, variances, and box plots for model criteria and model scores can be generated, with and without outliers. This will facilitate discussions about which criteria are most important and which models to adopt or keep in production.
Criteria Validity
The validity of the criteria proposed here is important to consider. I tried to address content validity by covering several issues about the quality of analytic models that have been discussed in my work with colleagues and described in recent literature. Thus, one criterion relates to whether models under consideration are likely to measure or predict the outcome of true interest, rather than a proxy for that outcome. Commenting on this issue when reviewing this manuscript, Brian Hochrein, another noted analytics leader, mentioned that no data set can perfectly capture the complexity of human behavior or mother nature, so the question is whether or how to continue the modeling exercise when imperfect data are available. Some thoughts about how to proceed when this is the case is offered by Christian (2020), Hall, et al. (2021), and Obermeyer et al. (2021).
Model complexity and performance are noted as important criteria in the table as well. According to Brian, we need models that are easy to understand yet complex enough to adequately predict or understand outcomes of interest. Others agree (e.g., Christian, 2020; Hall and Gill (2019)). Such models should perform well on statistical measures and yield high sensitivity and low false discovery rates. They should also offer insights that are better or more useful than models produced by competitors.
The ability to draw causal inferences is also reflected in the criteria, given a growing interest among data scientists and policymakers in this area. Causality is predicated on measuring the outcome of real interest, which, as noted earlier, is predicated upon having the right data and other resources available for the job. When human nature is not adequately captured by the data, resources, or modeling processes we use, causal inference will be limited.
Model transparency, trustworthiness, fairness, bias, and security are also suggested for consideration, as are efforts to protect data and research subjects in the modeling process.
In places where I worked, models were developed, maintained, and updated so they can be used as components in the offerings companies were selling or wanted to sell. Thus, the eventual contributions of each model to corporate and client revenues and profits were very important. Likely contributions to their reputations were important as well. These are all hard to estimate for any given analytic model because they must be considered over the useful life of the model, which is hard to forecast. Spirited discussions of the contribution of data science efforts to the magnitude and timing of revenues, profits, and reputation are likely. These discussions will air controversies; dealing with those openly and professionally will engender trust and a broader understanding of and respect for different opinions.
The last two criteria mentioned in the table reflect the contribution of each model to employee wellbeing, morale, and satisfaction, and to professional thought leadership. We should be building models that engage and motivate staff across the company. Giving staff opportunities to contribute to thought leadership and allowing them to influence model production will engender loyalty and produce opportunities for professional growth.
In addition to listing criteria and suggestions for how to rate the importance of each criterion, the table also mentions several issues to consider about each one. I also provided citations or links to where much more information about these issues can be found in the literature.
Photo by Stephen Dawson on unsplash.com
Limitations and Discussion
There is a lot of uncovered ground in this short guide to model prioritization. My focus has been on models that are externally facing, though similar criteria can be used for internal work as well.
You may believe that a dozen criteria are way too many, or too few – find out what works for your firm. You may identify other important criteria not mentioned, or other issues to address for your criteria of interest. While I provided some thoughts about issues to consider in the table, I did not say anything about how to address those issues or about how to resolve controversies about them. The references listed below, and in the table, can help with that. I encourage you to review that material. These authors are prominent in their fields and have produced many insights worth consideration.
What happens next, after models are scored? The scoring process and results should be discussed among internal and external contributors. Refinements can be made, if necessary, perhaps by using an approach where comments are collected, collated, and distributed for subsequent discussion. This can be repeated multiple times if necessary to produce agreement.
Be careful, though, about the loudest-voice and most-senior-voice syndromes. Expect some emotional appeals or thoughts that may purposefully or inadvertently bias the criteria in favor of some models over others, or which stifle debate. These should be aired and discussed broadly. Perhaps in a group, perhaps individually, but everyone should be made aware of varying opinions so pros and cons can be addressed professionally.
Hall et al. (2021) and Obermeyer et al. (2021) provide advice about what to do when models perform poorly or are judged as less useful. They also provide ideas about how to use people, process, and technology to improve models. They and others (e.g., Christian, 2020; Melchionna 2022) strongly recommend guidance by human experts and non-experts alike, especially those who represent the populations covered by our models. Guidance about model accountability and audit processes are mentioned in their work as well.
Extensions and Final Thoughts
Data scientists may suggest other ways to undertake the prioritization exercise. Large companies often track the performance of their offerings over time. If so, it may be possible to collect enough data on attributes of their offerings, or the models that underlie each offering, and then use clustering and regression models, or other machine learning techniques, to help set the weights for each criterion of interest.
To facilitate data collection and analysis, some companies commoditize their offerings by labeling every input into each one. These inputs should include every data science model adopted for the offering. Companies may then assign something akin to a part number to each model and other input into each offering. Since models and other features can be used across multiple offerings over many years, this helps identify the breadth of contributions made by the data science team and other teams to company offerings. Considering the level of effort and resources to create each input then helps assign revenue or profit credit across the teams who contributed to product development and management. Tracking these credits over time can also help staff make inferences about the weights to assign to the criteria and the market value of modeling efforts when prioritizing future work.
Ideally a consensus, or at least a strong majority, would be produced about which criteria to use, how to weigh each one, and how to prioritize models in your firm. Experience suggests this will take some time, so data science roadmaps should be drafted with enough leeway to complete a thoughtful model prioritization process. This can easily take three or four months the first time it is used. Expect it to go much faster in later applications. I have done this multiple times now and would be happy to help. I hope you find this process useful.
Acknowledgments
I would like to thank Therese Gorski and Brian Hochrein for their helpful comments on this paper. Their insights made it much better. Any remaining errors are mine.
References
- A. Christian, The Alignment Problem: Machine Learning and Human Values (2020), New York, NY: W.W. Norton & Company
- A. Géron, Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems, 2nd Edition (2019), Sebostopal, CA: O’Reilly Media, Inc.
- P. Hall and N. Gill, An Introduction to Machine Learning Interpretability: An Applied Perspective on Fairness, Accountability, Transparency, and Explainable AI, 2nd Edition (2019), Sebostopal, CA: O’Reilly Media, Inc.
- P. Hall, N. Gill, and B. Cox, Responsible Machine Learning (2021), Sebostopal, CA: O’Reilly Media, Inc.
- D. Husereau, M. Drummond, F. Augustovski, et al., Consolidated Health Economic Evaluation Reporting Standards (CHEERS) 2022 Explanation and Elaboration: A report of the ISPOR CHEERS II Good Practices Task Force (2022), Value in Health 25:1:10-31.
- M. Maziarz, The Philosophy of Causality in Economics: Causal Inferences and Policy Proposals (2020), New York, NY: Routledge
- M. Melchionna, WHO: It’s time to eliminate ageism in artificial intelligence, (February 10, 2022), Health IT Analytics, on https://healthitanalytics.com/news/who-its-time-to-eliminate-ageism-in-artificial-intelligence
- S.L. Morgan and C. Winship, Counterfactuals and Causal Inference: Methods and Principals for Social Research, 2nd Edition (2015), Cambridge, United Kingdom: Cambridge University Press
- Z. Obermeyer, R. Nissan, M. Stern, et al., Algorithmic Bias Playbook (June, 2021), Chicago, IL: Center for Applied AI at Chicago Booth
- R. Ozminkowski, What Causes What, and how Would we Know? (September 14, 2021), Toward Data Science, on https://towardsdatascience.com/what-causes-what-and-how-would-we-know-b736a3d0eefb
- J. Pearl, M. Glymour, and N.P. Jewell, Causal Inference in Statistics: A Primer (2016), Chichester, West Sussex, United Kingdom: John Wiley & Sons
- J. Pearl and D. Mackenzie, The Book of Why: The New Science of Cause and Effect (2018), New York, NY: Basic Books
- B. Schmarzo, The Economics of Data, Analytics, and Digital Transformation: The Theorems, Laws, and Empowerments to Guide Your Organization’s Digital Transformation (2020), Birmingham, UK: Packt Publishing
- L. Wee, M.J. Sander, F.J.van Kujik, et al., Reporting Standards and Critical Appraisal of Prediction Models, Chapter 10 in Fundamentals of Clinical Data Science, edited by A. Dekker, M. Dumontier, and P. Kubben (2019), available via open access on https://doi.org/10.1007/978-3-319-99713-1
Ron Ozminkowski, PhD is an internationally recognized consultant, writer, and executive leader, focused on healthcare analytics and machine learning, whose published work has been viewed by people in over 90 countries around the world.