How to Speed up Scikit-Learn Model Training
Scikit-Learn is an easy to use a Python library for machine learning. However, sometimes scikit-learn models can take a long time to train. The question becomes, how do you create the best scikit-learn model in the least amount of time?
By Michael Galarnyk, Developer Relations at Anyscale
Scikit-Learn is an easy to use a Python library for machine learning. However, sometimes scikit-learn models can take a long time to train. The question becomes, how do you create the best scikit-learn model in the least amount of time? There are quite a few approaches to solving this problem like:
- Changing your optimization function (solver)
- Using different hyperparameter optimization techniques (grid search, random search, early stopping)
- Parallelize or distribute your training with joblib and Ray
This post gives an overview of each approach, discusses some limitations, and offers resources to speed up your machine learning workflow!
Changing your optimization algorithm (solver)
Better algorithms allow you to make better use of the same hardware. With a more efficient algorithm, you can produce an optimal model faster. One way to do this is to change your optimization algorithm (solver). For example, scikit-learn’s logistic regression, allows you to choose between solvers like ‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, and ‘saga’.
To understand how different solvers work, I encourage you to watch a talk by scikit-learn core contributor Gaël Varoquaux. To paraphrase part of his talk, a full gradient algorithm (liblinear) converges rapidly, but each iteration (shown as a white +) can be prohibitively costly because it requires you to use all of the data. In a sub-sampled approach, each iteration is cheap to compute, but it can converge much more slowly. Some algorithms like ‘saga’ achieve the best of both worlds. Each iteration is cheap to compute, and the algorithm converges rapidly because of a variance reduction technique. It is important to note that quick convergence doesn’t always matter in practice and different solvers suit different problems.
To determine which solver is right for your problem, you can check out the documentation to learn more!
Different hyperparameter optimization techniques (grid search, random search, early stopping)
To achieve high performance for most scikit-learn algorithms, you need to tune a model’s hyperparameters. Hyperparameters are the parameters of a model which are not updated during training. They can be used to configure the model or training function. Scikit-Learn natively contains a couple techniques for hyperparameter tuning like grid search (GridSearchCV) which exhaustively considers all parameter combinations and randomized search (RandomizedSearchCV) which samples a given number of candidates from a parameter space with a specified distribution. Recently, scikit-learn added the experimental hyperparameter search estimators halving grid search (HalvingGridSearchCV) and halving random search (HalvingRandomSearch).

These techniques can be used to search the parameter space using successive halving. The image above shows that all hyperparameter candidates are evaluated with a small number of resources at the first iteration and the more promising candidates are selected and given more resources during each successive iteration.
While these new techniques are exciting, there is a library called Tune-sklearn that provides cutting edge hyperparameter tuning techniques (bayesian optimization, early stopping, and distributed execution) that can provide significant speedups over grid search and random search.
Features of Tune-sklearn include:
- Consistency with the scikit-learn API: You usually only need to change a couple lines of code to use Tune-sklearn (example).
- Accessibility to modern hyperparameter tuning techniques: It is easy to change your code to utilize techniques like bayesian optimization, early stopping, and distributed execution
- Framework support: There is not only support for scikit-learn models, but other scikit-learn wrappers such as Skorch (PyTorch), KerasClassifiers (Keras), and XGBoostClassifiers (XGBoost).
- Scalability: The library leverages Ray Tune, a library for distributed hyperparameter tuning, to efficiently and transparently parallelize cross validation on multiple cores and even multiple machines.
Perhaps most importantly, tune-sklearn is fast as you can see in the image below.
If you would like to learn more about tune-sklearn, you should check out this blog post.
Parallelize or distribute your training with joblib and Ray
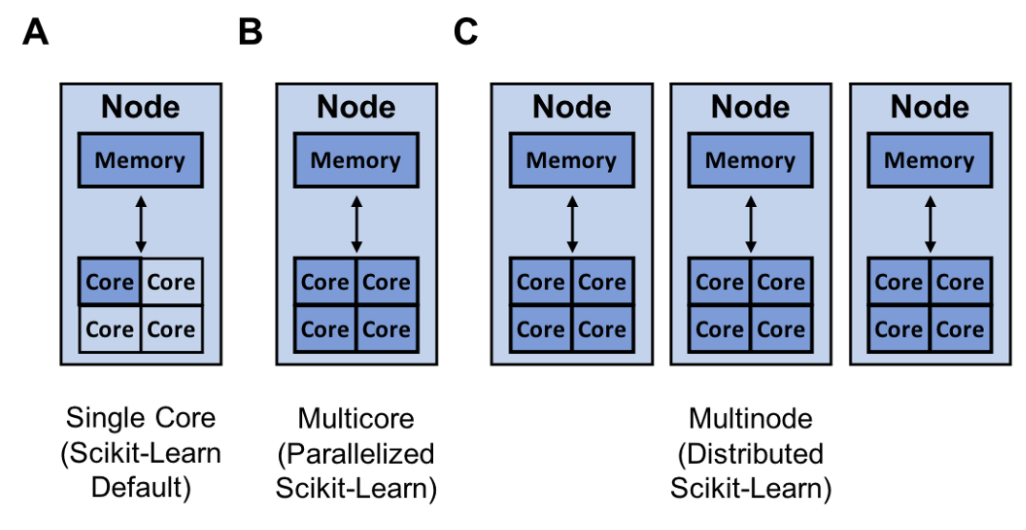
Another way to increase your model building speed is to parallelize or distribute your training with joblib and Ray. By default, scikit-learn trains a model using a single core. It is important to note that virtually all computers today have multiple cores.
Consequently, there is a lot of opportunity to speed up the training of your model by utilizing all the cores on your computer. This is especially true if your model has a high degree of high degree of parallelism like a random forest®.
Scikit-Learn can parallelize training on a single node with joblib which by default uses the ‘loky’ backend. Joblib allows you to choose between backends like ‘loky’, ‘multiprocessing’, ‘dask’, and ‘ray’. This is a great feature as the ‘loky’ backend is optimized for a single node and not for running distributed (multinode) applications. Running distributed applications can introduce a host of complexities like:
- Scheduling tasks across multiple machines
- Transferring data efficiently
- Recovering from machine failures
Fortunately, the ‘ray’ backend can handle these details for you, keep things simple, and give you better performance. The image below shows the normalized speedup in terms of execution time of Ray, Multiprocessing, and Dask relative to the default ‘loky’ backend.
If you would like to learn about how to quickly parallelize or distribute your scikit-learn training, you can check out this blog post.
Conclusion
This post went over a couple ways you can build the best scikit-learn model possible in the least amount of time. There are some ways that are native to scikit-learn like changing your optimization function (solver) or by utilizing experimental hyperparameter optimization techniques like HalvingGridSearchCV or HalvingRandomSearch. There are also libraries that you can use as plugins like Tune-sklearn and Ray to further speed up your model building. If you have any questions or thoughts about Tune-sklearn and Ray, please feel free to join our community through Discourse or Slack.
Bio: Michael Galarnyk works in Developer Relations at Anyscale, the company behind the Ray Project. You can find him on Twitter, Medium, and GitHub.
Original. Reposted with permission.
Related:
- The Ultimate Scikit-Learn Machine Learning Cheatsheet
- Python Lists and List Manipulation
- K-Means 8x faster, 27x lower error than Scikit-learn in 25 lines