RAPIDS cuDF to Speed up Your Next Data Science Workflow
This article will explain how RAPIDS can help you speed up your next data science workflow. RAPIDS cuDF is a GPU DataFrame library that allows you to produce your end-to-end data science pipeline development all on GPU.

Image by Author
Over the years there has been exponential growth in data science applications, fueled by data collected from a wide variety of sources. In the last 10 years alone we have seen the implementation of data science, machine learning and deep learning. Although we hear a lot more about machine learning and deep learning, it is the core data science technique that a lot of companies focus on as this is where they make money and save a lot of money.
However, studies show that 68% of data studies go unused and 90% of data is left unstructured. This is due to companies failing to focus on the data analytical processing phase, as it can take a lot of time, money and resources.
The data analysis phase consists of aggregating the data, exploring the data, and preparing the mode, consisting of 40% of a data scientist's time in the pipeline. Current CPU solutions can make this process much longer, slowing down the model development. In order to overcome this problem, there is a GPU-isolated solution called RAPIDS.
What is RAPIDS?
RAPIDS is a GPU data science isolated platform, where you can produce your end-to-end data science pipeline development all on GPU. As mentioned prior, the data analysis phase takes up to 40% of a data scientist's time. However, using RAPIDS can significantly reduce your data analysis time.
Looking at the image below, you can see the difference in workflow time between using a CPU and GPU during the data analysis phase.

Image by Nvidia
Shifting from CPU to GPU allows you to:
- Leverages NVIDIA CUDA for faster workflows
- Reduces training time and delivers faster deployment
- Accelerates the entire data science pipeline on GPUs
- Accelerates with a single line of code change to familiar data science libraries
- Simplifies data science work on NVIDIA GPUs
- Improves productivity for existing Python users
- GPU-accelerated computing for in-memory data preparation
- Optimized for analysis on a large dataset
- Delivers real-time insights from large datasets
In the image below, you can see the difference between a typical data science workflow using CPU and GPU:
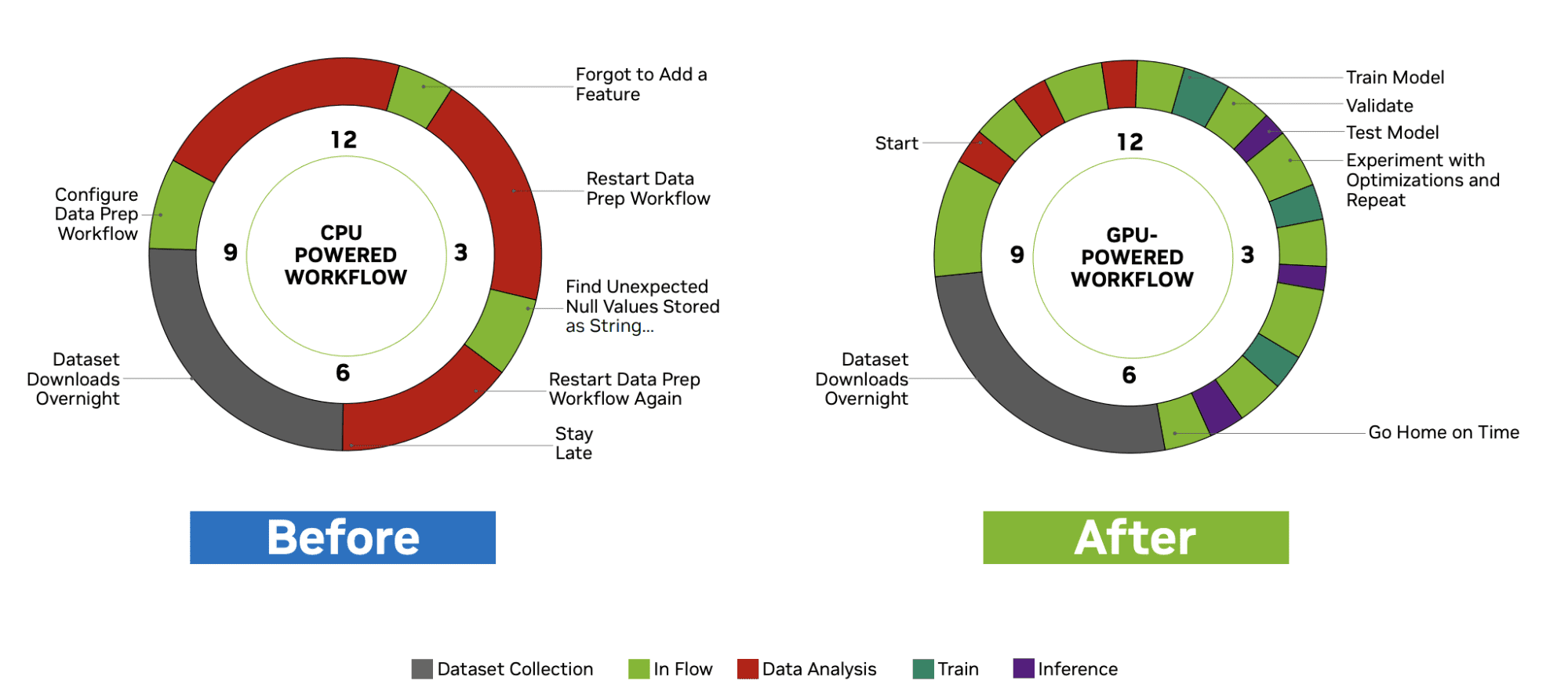
Image by Nvidia
RAPIDS cuDF
RAPIDS cuDF is a GPU DataFrame library in Python with a pandas-like API built into the PyData ecosystem. Users have the ability to create GPU DataFrames from files, NumPy arrays, and pandas DataFrames, along with utilizing other GPU-accelerated libraries from RAPIDS to easily create machine learning pipelines.
cuDF closely matches the Pandas API, but it does not fully replace Pandas. There are some similarities and differences between cuDF and Pandas. cuDF supports similar data structures and operations as Pandas for example, indexing, filtering, concatenating, joining, groupby, and more. The best way to check if cuDF supports a particular Pandas API, have a look at the API docs.
Exploratory Data Analysis
Exploratory Data Analysis is the process of analyzing and summarizing a dataset in order to gain more insights about the data and a better understanding of the patterns. You can do this by quantifying the data with summary statistics in order to understand the distribution as well as be able to detect outliers, anomalies, and missing data.
Exploratory data analysis comes across challenges such as:
- Handling large and complex datasets
- Understanding relationships between multiple variables
- Executing computationally expensive, long runtime queries
- Identifying and imputing missing data points with appropriate methods
- Handling the curse of dimensionality
- , and more.
You can naturally improve the time it takes to explore your data with cuDF, using similar operations to Pandas, but works significantly faster.

Time-Series Data Processing
Time-Series Data Processing is when data points are collected at regular intervals over time, such as stock prices, weather data, and sensor readings. This helps to identify trends, forecast future events, and detect anomalies.
Time-Series data come across challenges such as:
- Data coming from a range of sources in many different formats
- Data quality can be impacted by numerous real-world events
- Missing data, outliers, and spurious recordings make for complicated processing
- Patterns and relationships may change over time
- Models and forecasts become stale quickly
- High dimensionality requires large computational power and memory
- , and more.
Again, cuDF enables complex data manipulation, with near-identical pandas endpoints.
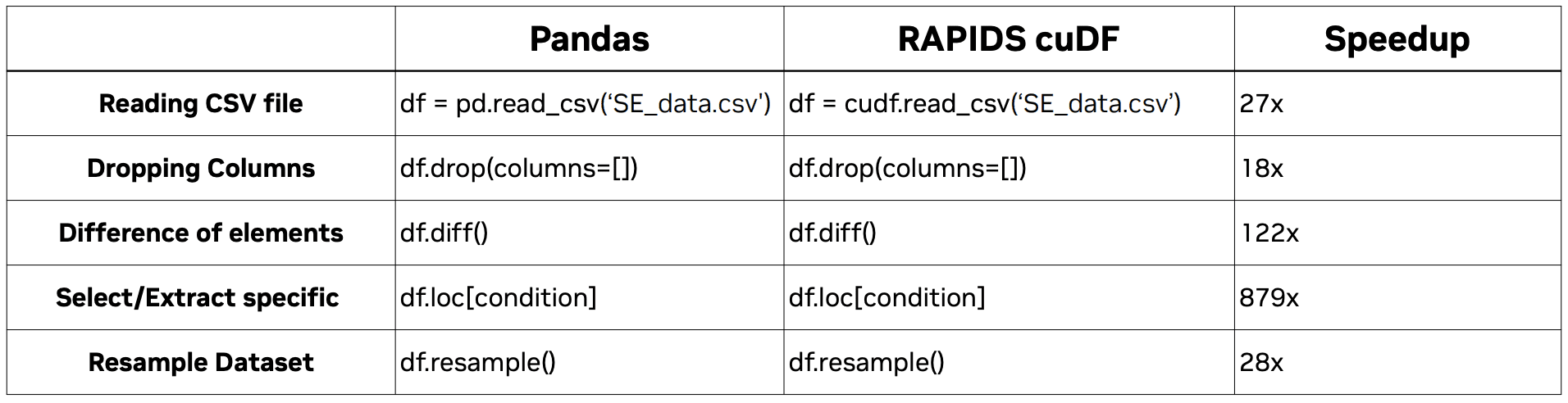
So as you can see, there's not much difference between Pandas and cuDF in terms of code. However, there is a major difference in speed.
Conclusion
Killing days and weeks of your data science pipeline is something that every data scientist wants. Why not change the amount of time wasted by upgrading to RAPIDS cuDF?
To add, RAPIDS cuDF is now on Google Colab. Check it out here: RAPIDS cuDF Google Colab
If you would like to know more about the difference between cuDF and Pandas, or just learn more about cuDF and how you can use it for your next data science pipeline, have a read of:
Nisha Arya is a Data Scientist, Freelance Technical Writer and Community Manager at KDnuggets. She is particularly interested in providing Data Science career advice or tutorials and theory based knowledge around Data Science. She also wishes to explore the different ways Artificial Intelligence is/can benefit the longevity of human life. A keen learner, seeking to broaden her tech knowledge and writing skills, whilst helping guide others.