Machine Learning – it’s all about assumptions
Just as with most things in life, assumptions can directly lead to success or failure. Similarly in machine learning, appreciating the assumed logic behind machine learning techniques will guide you toward applying the best tool for the data.
By Vishal Mendekar, Skilled in Python, Machine Learning and Deep learning.
This blog is all about the assumptions made by the popular ML Algorithms, and their pros and cons.

Getting started with this blog, let me first tell the reason for coming up with this blog.
There are tons of Data Science enthusiasts who are either looking for a job in Data Science or switching jobs for better opportunities. Every one of these individuals must to go through some strict hiring process containing several rounds of interviews.
There are several basic questions which a recruiter/interviewer expects to be answered. Knowing about the assumptions of the popular Machine Learning Algorithms along with their Pros & Cons is one of them.
Going ahead in the blog, I will first introduce you to the assumptions made by a specific algorithm, followed by its pros & cons. So it will only take about 5 minutes of your time, and at the end of the blog, you will surely have learned something.
I am going to follow the below sequence to introduce assumption, pros & cons.
- K-NN (K-Nearest Neighbours)
- Logistic Regression
- Linear Regression
- Support Vector Machines
- Decision Trees
- Naive Bayes
- Random Forest (Bagging Algorithm)
- XGBoost (Boosting Algorithm)
1. K-NN
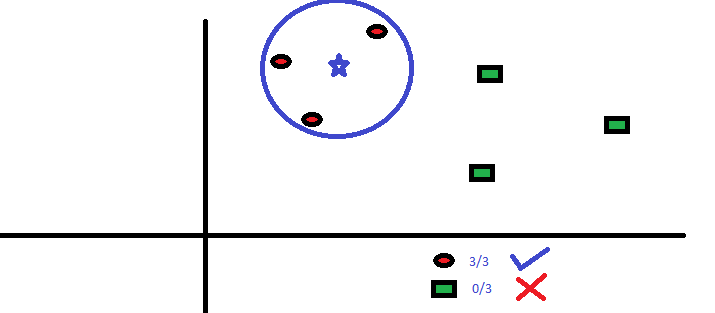
Assumptions:
- The data is in feature space, which means data in feature space can be measured by distance metrics such as Manhattan, Euclidean, etc.
- Each of the training data points consists of a set of vectors and a class label associated with each vector.
- Desired to have ‘K’ as an odd number in case of 2 class classification.
Pros:
- Easy to understand, implement, and explain.
- Is a non-parametric algorithm, so does not have strict assumptions.
- No training steps are required. It uses training data at run time to make predictions making it faster than all those algorithms that need to be trained.
- Since it doesn’t need training on the train data, data points can be easily added.
Cons:
- Inefficient and slow when the dataset is large. As for the cost of the calculation, the distance between the new point and train points is high.
- Doesn’t work well with high dimensional data because it becomes harder to find the distance in higher dimensions.
- Sensitive to outliers, as it is easily affected by outliers.
- Cannot work when data is missing. So data needs to be manually imputed to make it work.
- Needs feature scaling/normalization.
2. Logistic Regression
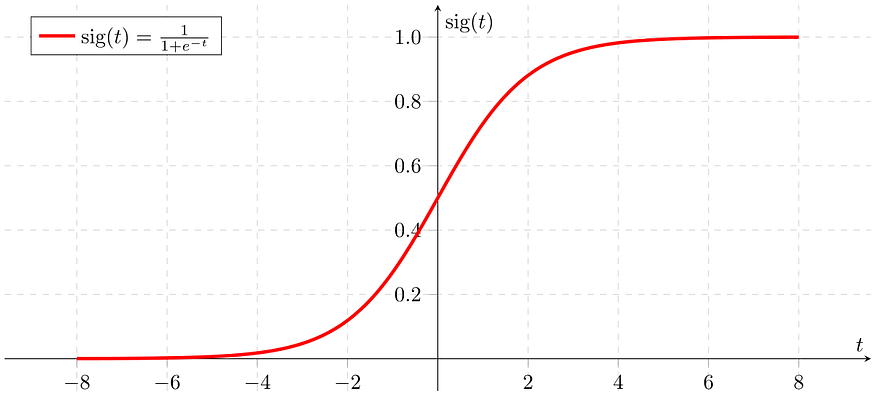
Assumptions:
- It assumes that there is minimal or no multicollinearity among the independent variables.
- It usually requires a large sample size to predict properly.
- It assumes the observations to be independent of each other.
Pros:
- Easy to interpret, implement and train. Doesn’t require too much computational power.
- Makes no assumption of the class distribution.
- Fast in classifying unknown records.
- Can easily accommodate new data points.
- Is very efficient when features are linearly separable.
Cons:
- Tries to predict precise probabilistic outcomes, which leads to overfitting in high dimensions.
- Since it has a linear decision surface, it can’t solve non-linear problems.
- Tough to obtain complex relations other than linear relations.
- Requires very little or no multicollinearity.
- Needs a large dataset and sufficient training examples for all the categories to make correct predictions.
3. Linear Regression
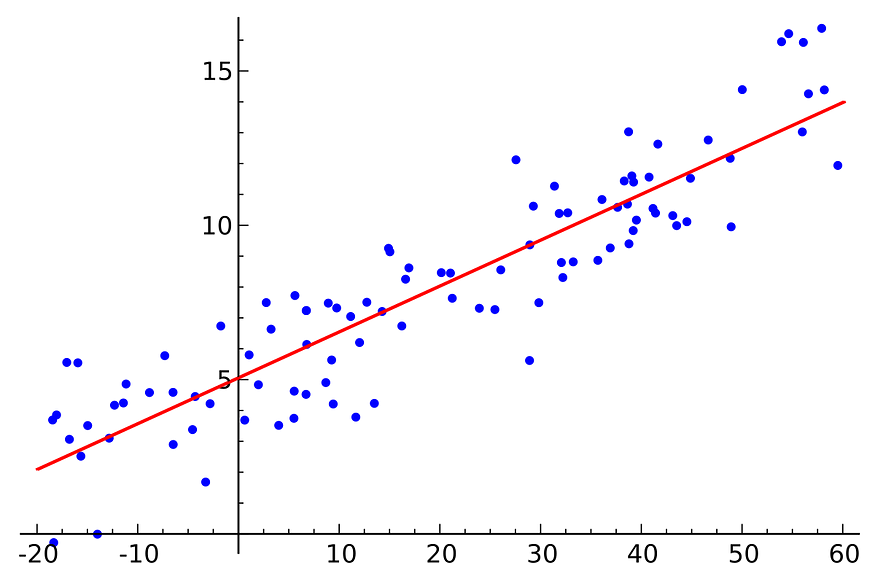
Assumptions:
- There should be a linear relationship.
- There should be no or little multicollinearity.
- Homoscedasticity: The variance of residual should be the same for any value of X.
Pros:
- Performs very well when there is a linear relationship between the independent and dependent variables.
- If overfits, overfitting can be reduced easily by L1 or L2 Norms.
Cons:
- Its assumption of data independence.
- Assumption of linear separability.
- Sensitive to outliers.
4. Support Vector Machines
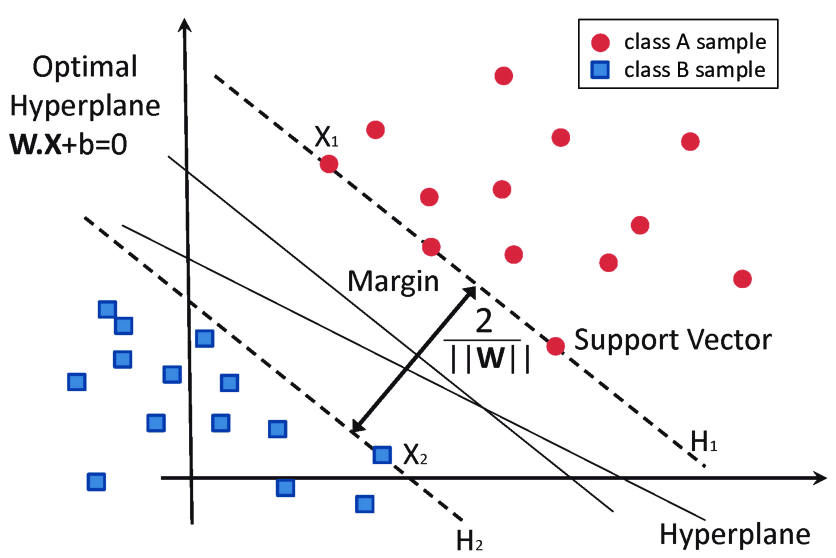
Assumptions:
- It assumes data is independent and identically distributed.
Pros:
- Works really well on high dimensional data.
- Memory efficient.
- Effective in cases where the number of dimensions is greater than the number of samples.
Cons:
- Not suitable for large datasets.
- Doesn’t work well when the dataset has noise, i.e., the target classes are overlapping.
- Slow to train.
- No probabilistic explanation for classification.
5. Decision Trees
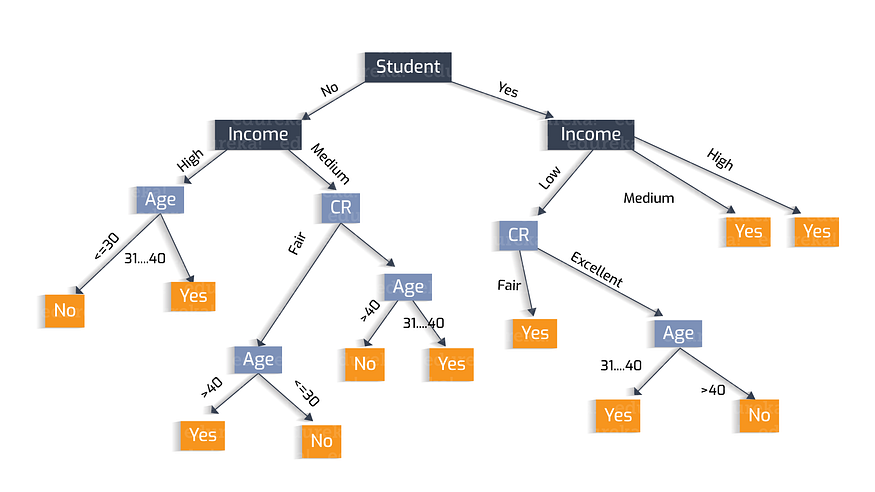
Assumptions:
- Initially, whole training data is considered as root.
- Records are distributed recursively on the basis of the attribute value.
Pros:
- Compared to other algorithms, data preparation requires less time.
- Doesn’t require data to be normalized.
- Missing values, to an extent, don’t affect its performance much.
- Is very intuitive as can be explained as if-else conditions.
Cons:
- Needs a lot of time to train the model.
- A small change in data can cause a considerably large change in the Decision Tree structure.
- Comparatively expensive to train.
- Not good for regression tasks.
6. Naive Bayes
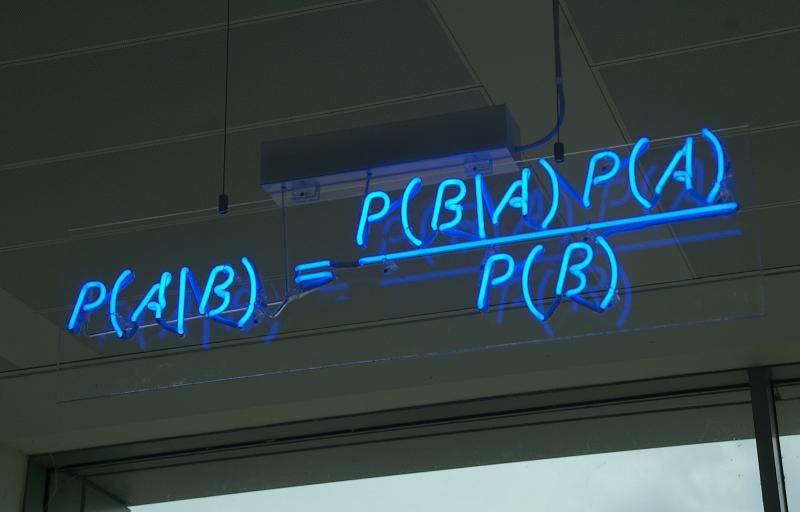
Assumptions:
- The biggest and only assumption is the assumption of conditional independence.
Pros:
- Gives high performance when the conditional independence assumption is satisfied.
- Easy to implement because only probabilities need to be calculated.
- Works well with high-dimensional data, such as text.
- Fast for real-time predictions.
Cons:
- If conditional independence does not hold, then is performs poorly.
- Has the problem of Numerical Stability or Numerical Underflow because of the multiplication of several small digits.
7. Random Forest
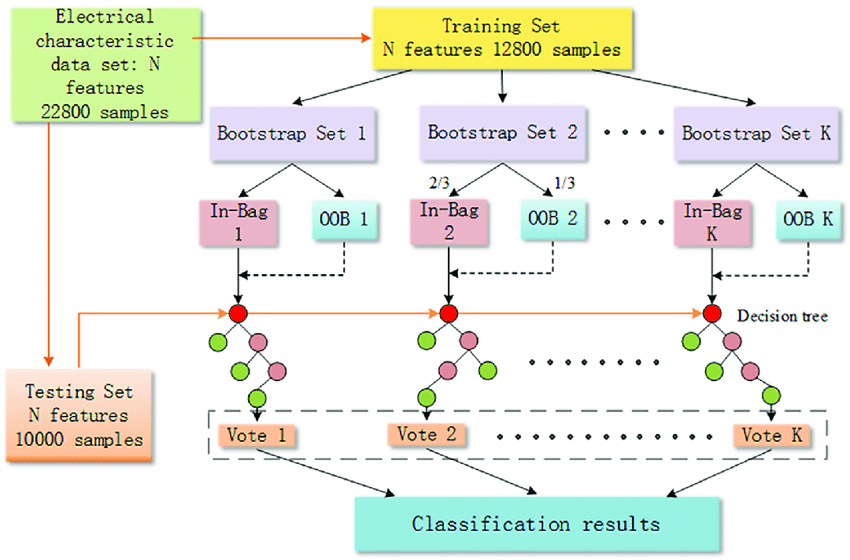
Assumptions:
- Assumption of no formal distributions. Being a non-parametric model, it can handle skewed and multi-modal data.
Pros:
- Robust to outliers.
- Works well for non-linear data.
- Low risk of overfitting.
- Runs efficiently on large datasets.
Cons:
- Slow training.
- Biased when dealing with categorical variables.
8. XGBoost
Assumptions:
- It may have an assumption that encoded integer value for each variable has ordinal relation.
Pros:
- Can work in parallell.
- Can handle missing values.
- No need for scaling or normalizing data.
- Fast to interpret.
- Great execution speed.
Cons:
- Can easily overfit if parameters are not tuned properly.
- Hard to tune.
Original. Reposted with permission.
Related: