15 common mistakes data scientists make in Python (and how to fix them)
Writing Python code that works for your data science project and performs the task you expect is one thing. Ensuring your code is readable by others (including your future self), reproducible, and efficient are entirely different challenges that can be addressed by minimizing common bad practices in your development.
By Gerold Csendes, Data Scientist at EPAM Systems.

Photo by Joshua Aragon on Unsplash.
I gradually realized in my data science career that by applying software engineering best practices, you could deliver better quality projects. Better quality might be fewer bugs, reliable results, and higher productivity in coding. This article is not intended to introduce you to these best practices in detail. Instead, it summarizes the most common mistakes I encountered (and made myself too), and offers methods, ideas, and resources on how to best tackle them.
When reading my article, you might be tempted to think, “Well, when I work on my own, I don’t really need to follow this advice because I know my code.” The chances are that at least one other person will read your code: your future self. What you find self-evident at the moment will be total nonsense months later. Let’s make her life easier by avoiding the following mistakes.
1. You don’t work in an isolated environment
Okay, this may not be a coding issue per se, but I still consider isolated environments as an important feature for my code. Why would you consider using a dedicated environment for each of your projects? You want to make your code reproducible: on your computer in the future, on your coworker’s machine, and in production too. Ever faced the issue that your peer could not run your code? It is quite likely that she doesn’t have the same dependencies as you. (Or maybe after running hundreds of cells, you forgot to check whether your notebook breaks when using a clear kernel). If you have no idea what dependency management means, then it is best to start with Anaconda Virtual Environment or Pipenv. I personally use Anaconda, and there is a great tutorial that you can access by clicking the link. If you want to go deeper, then Docker is your go-to.
2. (Overuse of) Jupyter Notebooks
Notebooks are really good for educational purposes and to do some quick and dirty job, but it fails to act as a good IDE. A good IDE is your real weapon when fighting data science tasks and can enhance your productivity immensely. There are lots of smart people shedding light on the shortcomings of notebooks. I consider Joel Grus’s talk to be the best and most hilarious.
Don’t get me wrong, notebooks are fine for experimentation, and it is great that you can show your results to your peers with ease. However, they are really prone to errors, and when it comes to doing longer-term, collaborative and deployable projects, then you better look for a real IDE e.g., VScode, Pycharm, Spyder etc. I do use notebooks every now and then, but I made a mental model: I only use notebooks if the project doesn’t exceed one day.
3. You don’t organize your code
Data scientists have a track record of stockpiling all their project files in a single directory. It is a bad practice. Take a look at the figure below and imagine that you are to take over a project of your colleague. Which project structure would put you into an existential crisis after hours of trying to figure out what is going on? Of course, the structure on the left is your go-to. Cookiecutter is a brilliant initiative promoting a standardized project structure for data science. Make sure to check this out.

Good and bad project structure — Screenshot by Author.
4. Absolute instead of relative paths
Ever faced a comment in code “pls fix your path”? Such a comment suggests bad code design. Fixing this consists of 2 steps. 1) share the project structure with your peer (maybe the one suggested above) 2) set your IDE root/working directory to your project root that is usually the outmost directory in your project. The latter one is sometimes not that trivial to do, but it is definitely worth the effort because your peer will be able to run your code without changing it.
5. Magic numbers
Magic numbers are numerics without context in code. By using magic numbers, you may end up with really hard-to-track errors. The gist below clearly shows that by simply using an unassigned number in a multiplication, you lose context of why this is happening, and if you later have to change this, it is rather stressful. It is thus desired to use named constants in capitals in Python. You don’t actually have to use capitalization, it is only a convention, but it is a good idea to distinguish your “constants ” from your “regular” variables.
6. Not dealing with warnings
We have all been there when our code ran but generated weird warning messages. You are happy that you finally got your code running and received a meaningful output. So why deal with the warning? Well, warnings themselves are not errors, but they call attention to potential bugs or issues. They appear when there is something dubious in your code that though it ran successful but maybe not the way it was intended. The most common warnings I faced were Pandas’ SettingwithCopyWarning and DeprecationWarning. DataSchool explains in a neat way how SettingwithCopyWarning is triggered. DeprecationWarning usually points out that Pandas deprecated some functionality, and your code will break when using a later release. Of course, there are a handful of other warning types, and my experience is that they arise when using something in a way it was not designed. Understanding the source code of that function always helps. With that, you can get rid of those warnings 99% of the time.
7. You don’t use type annotation
I need to admit, this is a practice that I picked up recently, but I can already see its benefits. Type annotation (or type hint) is a method to assign types to your variables. You basically extend your code with hints that are really extensions to your code, indicating the type of variables/parameters. This makes your code easier to read because the intentions of the coder are explicit. To demonstrate this, I have taken an example from Daniel Starner at dev.to. Without type hints, mystery_combine() runs with both integer and string inputs and outputs either an integer or string. This might be ambiguous for a fellow developer. By using type annotation, you can be explicit with your intentions and make your peer's life easier.
Additionally, code with type annotation can be statically (without actually running the code) checked for bugs. The screenshot below shows that the first two arguments are not well specified. Statically checking your code is a nice and useful way for a pre-check before running it.
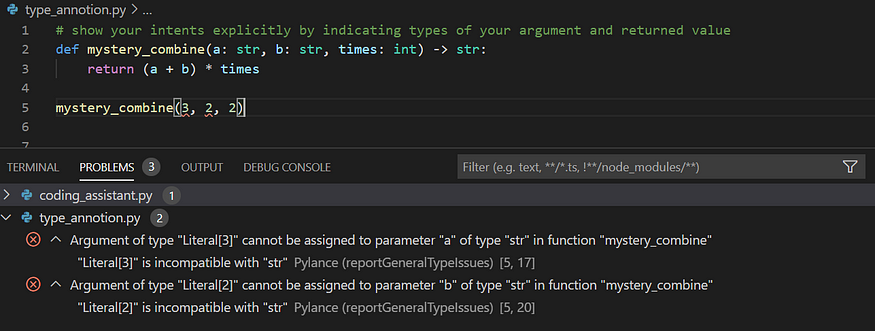
Screenshot by Author.
8. You don’t use (enough) list comprehensions
List comprehension is a really powerful feature of python. Many for loops may be substituted with list comprehension that is more readable, pythonic, and also faster. Below you can see an example code that intends to read a CSV file in a directory. You might say that using a for loop is not a sin in this case but try checking only for CSV files (there may be other formatted files like JSON). You can sense that adding such a feature is easy to maintain when using list comprehension.
9. Your pandas code is not readable
Method chaining is a great feature in pandas, but your code can get unreadable if you express everything in a single line. There is a trick that enables you to break the expression up. If you put your expression into parentheses, then you are able to use a single line for each component of the expression. Isn’t that a lot cleaner?
10. You are afraid to use dates
Dates can be intimidating in Python. The syntax is weird, and it is hard to wrap your head around it. A common mistake I see is that people handle dates like numerics. You can always do a workaround and hack code together, but it is really error-prone, hard to read and maintain. See an example below where the task is to list all months between two dates in a %Y%m format. You can see that your code becomes much more readable and maintainable if you follow the datetime implementation. In my case, dealing with dates still requires lots of googling, but I have learned not to be intimidated if I don’t find a solution on the first try.
11. You don’t use good variable names
Naming your dataframes df and i, j, k for your loop indexes are just non-descriptive and make your code less readable. An effort for keeping your variable names too short is a guarantee for confusing the coders on your project. Don’t be afraid to use long(er) names for your variables. There is nothing stopping you from using more ‘_’-s. Make sure to check out Will Koehrsen’s great article on this topic to get further insights.
12. You don’t modularize your code
Modularization means breaking up long and complex code into simpler modules that perform smaller, specific tasks. Don’t just create a long script for your project. Defining your classes or functions at the top of your code is bad practice. It is hard to maintain and read. Instead, create modules (packages) and structure them based on their functionality. Again, you can visit realpython.org Python Modules and Packages tutorial for an in-depth introduction.
13. You don’t follow PEP conventions
When I started with programming in Python, I ended up writing ugly, unreadable code and started making my own design rules on how to make my code look better. It took quite a lot of time to come up with them, and I did break these rules often. Then, I found out about PEP, which is the official styling guideline for Python. I am really fond of PEP because it makes collaboration easier by enabling you to standardize the appearance of your code. By the way, I do ignore some PEP rules, but I would say I use them in 90% of my code.
Any good Python IDE can be extended with a linter. The picture below demonstrates how a linter works in practice. They point out code quality issues, and if it is still vague for you, you can check out the specific PEP index, which is indicated in parentheses. If you want to see what linters are available out there, then, as always, realpythong.org is a good source for python stuff.
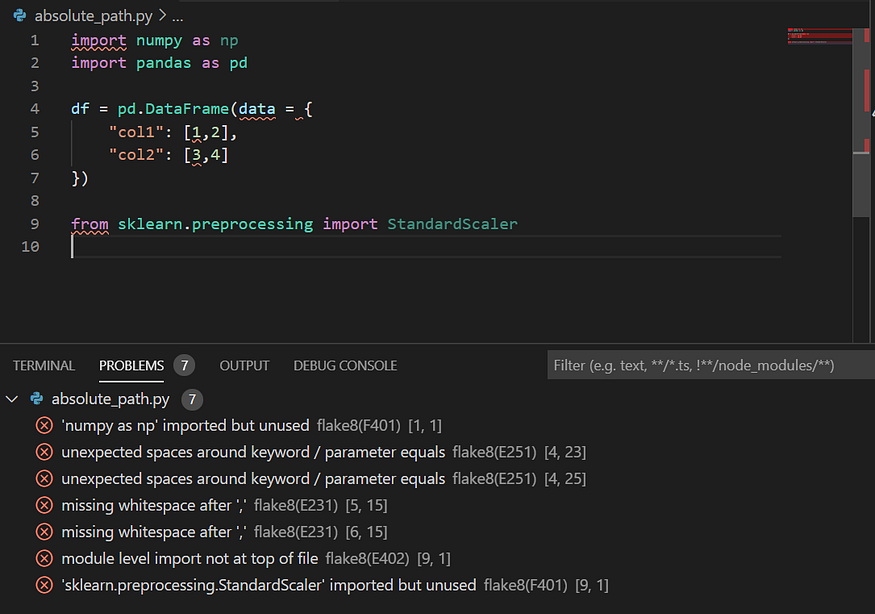
Screenshot by Author.
14. You don’t use a coding assistant
Do you want to have big productivity gains in coding? Start using a coding assistant that helps by clever autocomplete, opening up documentation, and giving suggestions to improve your code. I like using pylance, which is a new tool developed by Microsoft and is available in VScode. Kite is an alternative that is also really nice and available in a number of editors.
Check out this video by the author.
15. You don’t hide secrets in your code
Pushing secrets (passwords, keys) to public GitHub repositories is a widespread security flaw. If you want to get a sense of the seriousness of this issue, check out this qz article. There are bots crawling the internet waiting for you to make such a mistake. As far as I am concerned, security is a topic that is hardly ever part of any data science curriculum. So, you need to fill in the gap yourself. I suggest you first start with using OS environment variables. This dev.to article might be a good start.
Original. Reposted with permission.
Related: