Getting Started with PyTorch Lightning
Introduction to PyTorch Lightning and how it can be used for the model building process. It also provides a brief overview of the PyTorch characteristics and how they are different from TensorFlow.

Image by Editor
What is PyTorch Lightning?
PyTorch Lightning is a powerful deep learning framework that supports scalable state-of-the-art AI research work. It keeps your code structured for the research work and saves it from the growing complexity of your project.
But before we proceed to understand what code complexity entails, let's first explore in detail how structured code in PyTorch Lightning (referred to as Lightning throughout the post) helps us in our endeavor to expedite the model-building process. As you gear up to code your machine learning model, you typically design the model architecture along with choosing the right optimizer for the given dataset. With all these aspects given, you are now ready to get hands-on writing python code that would involve steps like iterating through batches of data for training and validation. Not to forget the periodic debugging measures that are inevitable in any machine learning project.
Further, the code complexity involves multiple factors such as the utilization of multiple GPUs, early stopping criteria, the need for checkpointing, 16-bit precision, training on TPU accelerators, etc. Lightning allows training models on CPUs, GPUs, or TPUs without changing the Pytorch code and assists in building reproducible models.
Quoting the benefits directly from the Lightning creator – “PyTorch Lightning was created for professional researchers and Ph.D. students working on AI research. It is designed to be extremely extensible while making state-of-the-art AI research techniques (like TPU training) trivial”
How is it Different from PyTorch?
It is important to understand the PyTorch characteristics to appreciate the offerings and benefits that come with Lightning.
PyTorch is a python based open-sourced library popularly used to build neural network models. It enjoys a vast community base and predominantly finds use in research environments as compared to TensorFlow which is its most common alternative for building production models. If you are interested in learning the basics of PyTorch, then this documentation serves as an excellent reference.
Though PyTorch is intended for researchers, it soon becomes engineering and code-driven concerning efforts related to training and tuning the model.
Lightning builds upon the flexibility that PyTorch offers for model training and facilitates the quick iteration of multiple cutting-edge experiments. It improves code readability by structuring it further enhancing reproducibility.
Largely the code remains similar, except for the following:
- The training and validation loop have been abstracted away by the Trainer.
- Further, some of the code blocks namely data loader, forward pass, optimizer, etc. are restructured that require minimum details from the developer
For example, Lightning automatically saves the model checkpoint by default as compared to Pytorch which expects the developer to insert that logic for checkpointing. Lightning also provides the logs of weights summary, checkpointing, early stopping, and tensorboard logs.
How to Install PyTorch Lightning
You can run the below command in your terminal (for MAC/Linux) or command line (for Windows):
pip install pytorch-lightning
Welcome to the “Hello-World” of Lightning
Let’s build an image classification model to recognize digits using the MNIST dataset. You can learn about how to import multiple datasets through the torchvision module on Pytorch's official documentation page.

Source: MLM
The four core components of building any neural network model involve the model, data, loss, and optimizer.
Let’s start with the neural network architecture.
- For this demo, we will be building a 4-layer (3-layer if input layer is not explicitly counted) fully connected deep neural network architecture including the input and the output layers.
- However, the square image (size 28 * 28) needs to be vectorized or flattened to be consumed by the neural network as input. Hence, the number of neurons in the input layer is equal to the width * height of the images i.e. 784 (28*28). The flattening process places the values of each row in a vector, as demonstrated below.
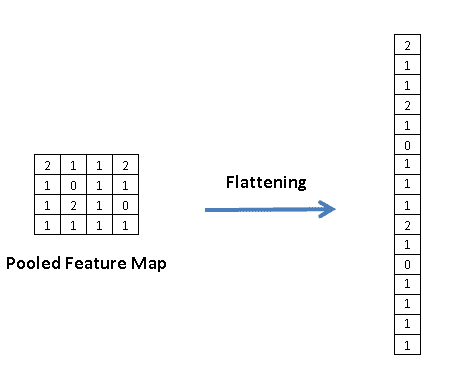
Source: A Practical Guide to Convolutional Neural Networks (CNNs) with Keras
- On the other hand, the number of neurons in the output layer is equal to the number of labels i.e. 10 (digits from 0 to 9).
- You have the option to choose the number of neurons in the hidden layers. Generally speaking, a smaller number of neurons might risk losing the information from the input layer while a larger number leads to information duplication from the neurons. Let’s pick 128 neurons for the first hidden layer and 256 neurons for the second hidden layer.
- The neural network architecture looks like the image below.
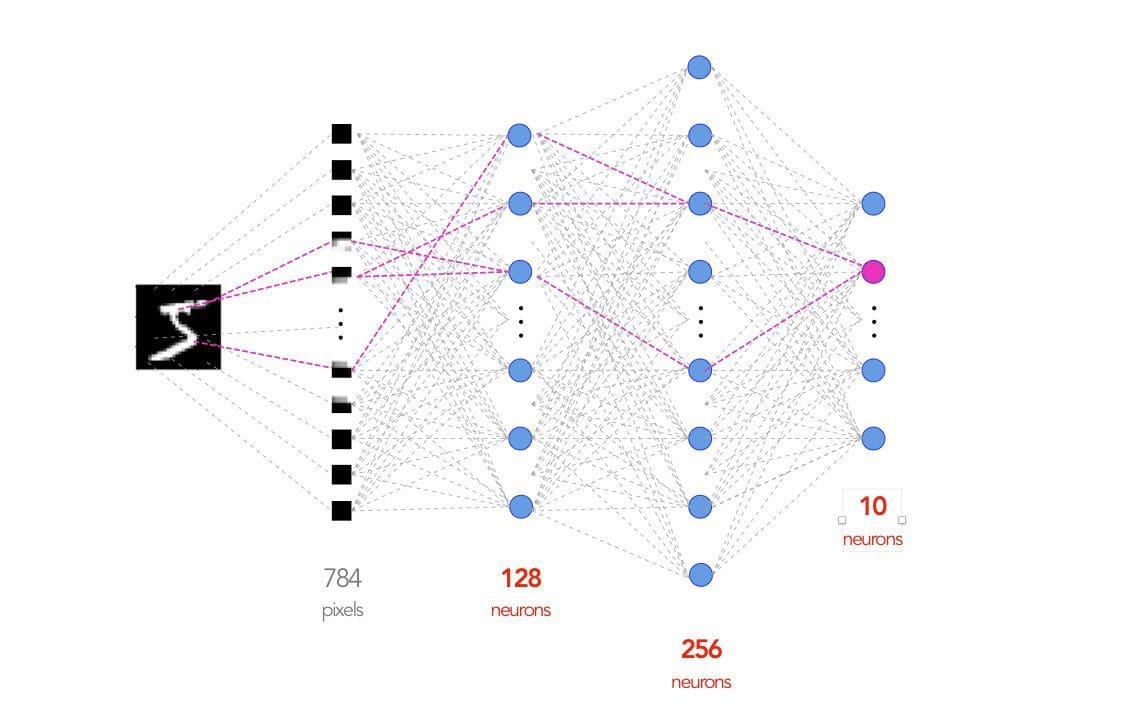
Source: PyTorch Lightning Introduction
- You also need to specify a forward propagation function let’s pick a ReLu activation function for hidden layers and a Softmax activation function for the output layer.
- The training or validation runs on the network involve forward propagation to compute the output probabilities followed by loss computation to adjust network parameters using the Adam optimizer.
The neural network architecture, loss, and optimizer selection as detailed above is shown in the code (sourced and modified from “From PyTorch to PyTorch Lightning - An Introduction”) below:
import torch
from torch import nn
import pytorch_lightning as pl
from torch.utils.data import DataLoader, random_split
from torch.nn import functional as F
from torchvision.datasets import MNIST
from torchvision import datasets, transforms
import os
class PLClassifier(pl.LightningModule):
def __init__(self):
super(PLClassifier, self).__init__()
self.input = torch.nn.Linear(28 * 28, 128)
self.hidden1 = torch.nn.Linear(128, 256)
self.hidden2 = torch.nn.Linear(256, 10)
def forward(self, x):
batch, channels, width, height = x.size()
x = x.view(batch, -1)
x = self.input(x)
x = torch.relu(x)
x = self.hidden1(x)
x = torch.relu(x)
x = self.hidden2(x)
x = torch.log_softmax(x, dim=1)
return x
def training_step(self, batch, batch_idx):
x, y = train_batch
logits = self.forward(x)
loss = F.nll_loss(logits, y)
self.log('train_loss', loss)
return loss
def validation_step(self, batch, batch_idx):
x, y = train_batch
logits = self.forward(x)
loss = F.nll_loss(logits, y)
self.log('val_loss', loss)
def configure_optimizers(self):
opt = torch.optim.Adam(self.parameters(), lr=1e-3)
return opt
# initialize and train
model = PLClassifier()
trainer = pl.Trainer()
trainer.fit(model)
You can download the train and test data by following the code below.
train = MNIST(os.getcwd(), train=True, download=True)
test = MNIST(os.getcwd(), train=False, download=True)
Note that the train argument is set to True when pulling in training data and set to False for test data.
The training data can further be split into train and validation.
train, val = random_split(train, [50000, 10000])
Bonus
The post explained the benefits of Lightning and demonstrated how to build your first model with the help of python code. Further, if you prefer learning from video lessons, then you can refer to the bonus resource listing byte-sized video tutorials.
References
- https://towardsdatascience.com/from-pytorch-to-pytorch-lightning-a-gentle-introduction-b371b7caaf09
- https://learnopencv.com/getting-started-with-pytorch-lightning/
- https://colab.research.google.com/drive/1F_RNcHzTfFuQf-LeKvSlud6x7jXYkG31#scrollTo=HOk9c4_35FKg
Vidhi Chugh is an AI strategist and a digital transformation leader working at the intersection of product, sciences, and engineering to build scalable machine learning systems. She is an award-winning innovation leader, an author, and an international speaker. She is on a mission to democratize machine learning and break the jargon for everyone to be a part of this transformation.