3 Simple Ways to Speed Up Your Python Code
The post explains three popular frameworks, PySpark, Dask, and Ray, and discusses various factors to select the most appropriate one for your project.
Source: Image by Freepik
You just finished a project that used Python. The code is clean and readable, but your performance benchmark is not up to the mark. You expected to get a result in milliseconds, and instead, you got seconds. What do you do?
If you’re reading this article, you probably already know that Python is an interpreted programming language with dynamic semantics and high readability. That makes it easy to use and read — but not fast enough for many real-world use cases.
So there could be multiple ways to speed up your Python code including but not limited to the use of efficient data structures as well as fast and efficient algorithms. Some Python libraries also make use of C or C++ underneath to speed up computation.
What if you have exhausted all these options? Here comes parallel processing and a step ahead is distributed computing. In this post, you will learn about the three popular frameworks in distributed computing in a machine learning context: PySpark, Dask, and Ray.
PySpark
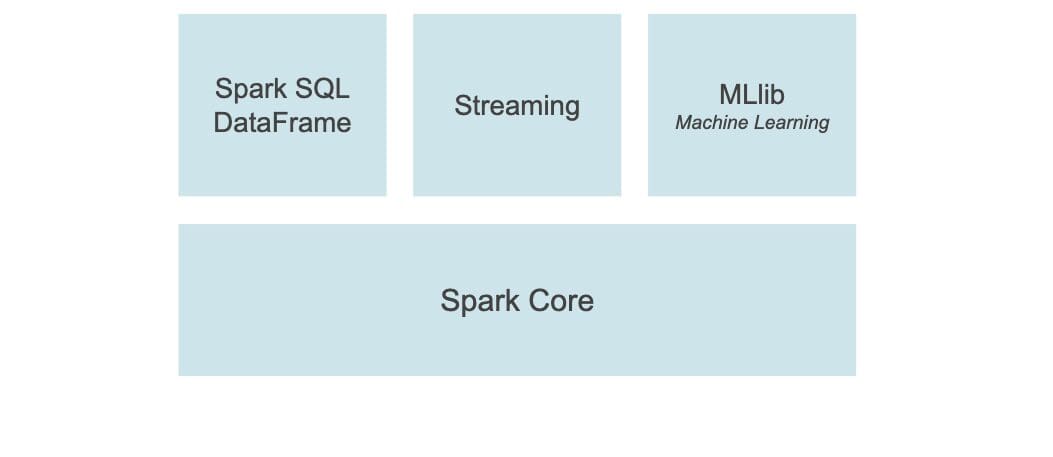
PySpark as the name suggests is an interface of Apache Spark within Python. It allows the user to write Spark programs using Python APIs and provides the PySpark shell for interactive data analysis in a distributed environment. It supports almost all of Spark’s features such as Streaming, MLlib, Spark SQL, DataFrame, and Spark Core as shown below:
Source
1. Streaming
The streaming feature in Apache Spark is easy to use and fault-resistant that runs on top of Spark. It powers intuitive and analytical systems across streaming as well as historical data.
2. MLlib
MLlib is a scalable machine learning library built on top of the Spark framework. It exposes a consistent set of high-level APIs to create and tune scalable machine learning pipelines.
3. Spark SQL and DataFrame
It is a Spark module for tabular data processing. It provides an abstraction layer above the tabular data known as DataFrame and can act as a SQL-style query engine in a distributed setup.
4. Spark Core
Spark Core is the base general execution engine on top of which all other functionality is built. It provides a Resilient Distributed Dataset (RDD) and in-memory computation.
5. Pandas API on Spark
Pandas API is a module that enables scalable processing of pandas' features and methods. Its syntax is just like pandas and does not require the user to train on a new module. It provides a seamless and integrated codebase for pandas (small/single machine datasets) and Spark (large distributed datasets).
Dask
Dask is a versatile open-source library for distributed computing that provides a familiar user interface to Pandas, Scikit-learn, and NumPy.
It exposes high-level and low-level APIs enabling users to run custom algorithms in parallel on single or distributed machines.
It has two components:
- Big data collections include High-Level collections such as Dask Array or parallelized NumPy arrays, Dask Bag or parallelized lists, Dask DataFrame or parallelized Pandas DataFrames, and Parallelized Scikit-learn. They also include Low-Level collections such as Delayed and Futures that ease parallel and real-time implementation of custom tasks.
- Dynamic task scheduling enables the execution of task graphs in parallel scaling up to clusters of thousands of nodes.
Ray
Ray is a single platform framework used in general distributed Python as well as AIML-powered applications. It constitutes a core distributed runtime and a toolkit of libraries (Ray AI Runtime) for parallelizing AIML computation as shown in the diagram below:

Source
Ray AI Runtime
Ray AIR or Ray AI Runtime is a one-stop toolkit for distributed ML applications that enables easy scaling of individual and end-to-end workflows. It builds on Ray’s libraries for a wide range of tasks such as preprocessing, scoring, training, tuning, serving, etc.
Ray Core
Ray Core provides core primitives like tasks (Stateless functions executed in the cluster), actors (Stateful worker processes created in the cluster), and objects (Immutable values accessible across the cluster) to build scalable distributed applications.
Ray scales machine learning workloads with Ray AIR and builds and deploys distributed applications with Ray Core and Ray Clusters.
Which One to Choose?
Now that you know your options, the natural question is which one to choose. The answer depends on a number of factors like the specific business need, the core strength of the development team, etc.
Let’s understand which framework is suitable for the specific requirements listed below:
- Size: PySpark is the most capable when it comes to dealing with ultra-large workloads (TBs and above) while Dask and Ray do fairly well on medium-sized workloads.
- Generic: Ray leads the front when it comes to generic solutions, followed by PySpark. While Dask is purely aimed at scaling ML pipelines.
- Speed: Ray is the best option for NLP or text normalization tasks which utilizes GPUs for speeding up computation. Dask on the other hand provides access to fast reading of structured files to DataFrame objects but falls behind when it comes to joining and merging them. This is where the Spark SQL scores well.
- Familiarity: For teams more inclined toward Pandas' way of fetching and filtering data, Dask seems to be a go-to option whereas PySpark is for those teams looking for an SQL-like querying interface.
- Ease of Use: All three tools are built over different platforms. While PySpark is mostly Java and C++ based, Dask is purely Python which means your ML team including data scientists can easily trace back error messages if something breaks. Ray on the other hand is C++ on the core but is fairly Pythonic when it comes to the AIML module (Ray AIR).
- Installation and Maintenance: Ray and Dask score equally well when it comes to maintenance overhead. Spark infrastructure on the other hand is quite complex and difficult to maintain.
- Popularity and Support: PySpark being the most mature of all enjoys developer community support while Dask comes second. Ray is promising in terms of features available in the beta testing phase.
- Compatibility: While PySpark integrates well with the Apache ecosystem, Dask gels with Python and ML libraries quite well.
Summary
This post discussed how to speed up Python code beyond the usual choice of data structures and algorithms. The post focused on three well-known frameworks and their components. The post intends to help the reader by weighing the available choices on a range of certain attributes and business contexts.
Vidhi Chugh is an award-winning AI/ML innovation leader and an AI Ethicist. She works at the intersection of data science, product, and research to deliver business value and insights. She is an advocate for data-centric science and a leading expert in data governance with a vision to build trustworthy AI solutions.