Quick Feature Engineering with Dates Using fast.ai
The fast.ai library is a collection of supplementary wrappers for a host of popular machine learning libraries, designed to remove the necessity of writing your own functions to take care of some repetitive tasks in a machine learning workflow.
As you are no doubt aware, simple date fields are potential treasure troves of data. While, at first glance, a date gives us nothing more than a specific point on a timeline, knowing where this point on the line is relative to other points can generate all sort of insights into a dataset. For instance, a whole host of simple questions can be extracted from a date field:
- Was it a weekend?
- What day of the week was it?
- Was the date the end of a quarter?
- Was the day a holiday?
- Were the Olympics taking place on said date?
What you want out of a date is dependent on what it is you are doing. Having external resources containing the answer to some of the less-intrinsic questions above ("Were the Olympics taking place on that date?" -- perhaps a perfectly valid question given your project) would certainly be necessary, but even sussing out the more elementary questions could prove immensely useful.
Simple feature engineering on dates can mindlessly take care of the latter. As I recently sat down to write a general, reusable function to do just that, I quickly came to realize that Jeremy Howard had taken care of this in his fast.ai library.
If you don't know, the fast.ai library is a collection of supplementary wrappers for a host of popular machine learning libraries, designed to remove the necessity of writing your own functions to take care of some repetitive tasks in a machine learning workflow.
Just such a function exists within fast.ai which leverages Pandas under the hood in order to automate some simple date-related feature engineering.
Let's have a look. But first, let's get some simple data to test with. To find out more about the data and how it's being collected in the below code, see Data Science Dividends – A Gentle Introduction to Financial Data Analysis. Also, it should go without saying that this assumes you have installed the fast.ai library.
import datetime
import pandas as pd
from pandas_datareader import data
from fastai.structured import add_datepart
# Set source and rate of interest
source = 'fred'
rate = 'DEXCAUS'
# Date range is 2016
start = datetime.datetime(2016, 1, 1)
end = datetime.datetime(2016, 12, 31)
cadusd = data.DataReader(rate, source, start, end)
# Write it to a CSV
cadusd.to_csv('cadusd.csv')
# Read the CSV back in (there is a peculiarity accounting for this)
cadusd = pd.read_csv('cadusd.csv')
# Set datetime precision to 'day'
cadusd['DATE'] = cadusd['DATE'].astype('datetime64[D]')
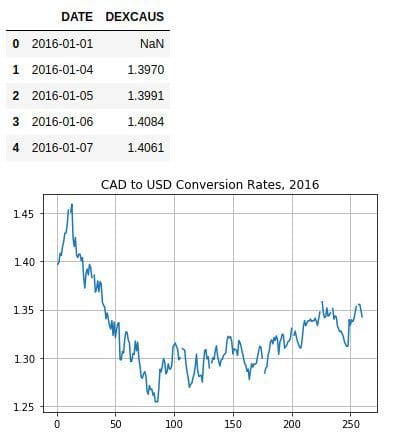
cadusd['DEXCAUS'].plot(kind='line', grid=True, title='CAD to USD Conversion Rates, 2016')
cadusd.head()
Just so we have an idea of how admittedly simple the code for fast.ai function we are going to use is, here's a look at the current version's source:
def add_datepart(df, fldname, drop=True):
fld = df[fldname]
if not np.issubdtype(fld.dtype, np.datetime64):
df[fldname] = fld = pd.to_datetime(fld, infer_datetime_format=True)
targ_pre = re.sub('[Dd]ate$', '', fldname)
for n in ('Year', 'Month', 'Week', 'Day', 'Dayofweek', 'Dayofyear',
'Is_month_end', 'Is_month_start', 'Is_quarter_end', 'Is_quarter_start', 'Is_year_end', 'Is_year_start'):
df[targ_pre+n] = getattr(fld.dt,n.lower())
df[targ_pre+'Elapsed'] = fld.astype(np.int64) // 10**9
if drop: df.drop(fldname, axis=1, inplace=True)
Howard has stated in numerous places that his goal in writing the fast.ai wrappers is to create useful functions in as few lines as possible, making them succinct, easy to read, and focused in their objectives.
A simple call to the function explodes the DATE field:
add_datepart(cadusd, 'DATE')
The only additional possible argument to the function is 'drop' which, when True, drops the original date column from the dataframe.
And here's the partial result:

A complete list of the features:
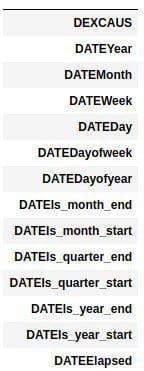
Since no machine learning algorithm would be able to look at a datetime object and automatically infer the above, a simple step like this provides the possibility for automated insight into a dataset. Without having to think about it, now all sorts of date metadata is at the algorithm's fingertips, such as whether this was the first day of the year, the first of the quarter, or the first of the month, and by further simple inferral, whether it was a weekend, whether it was in March, what year it was, etc.
This elementary feat of feature engineering should suggest 2 specific things, in my view:
- Feature engineering on time series data should not be feared
- The fast.ai library is something you might want to have a look at
Related:
- Time Series for Dummies – The 3 Step Process
- Deep Feature Synthesis: How Automated Feature Engineering Works
- Automated Feature Engineering for Time Series Data