7 Useful Suggestions from Andrew Ng “Machine Learning Yearning”
Machine Learning Yearning is a book by AI and Deep Learning guru Andrew Ng, focusing on how to make machine learning algorithms work and how to structure machine learning projects. Here we present 7 very useful suggestions from the book.

AI, Machine Learning, and Deep Learning are rapidly evolving and transforming many industries. Andrew Y. Ng is one of the leading minds in the field - he is a co-Founder of Coursera, former head of Baidu AI Group, and a former head of Google Brain. He is writing a book, "Machine Learning Yearning" (you can get a free draft copy), to teach you how to structure Machine Learning projects.
Andrew writes
This book is focused not on teaching you ML algorithms, but on how to make ML algorithms work. Some technical AI classes will give you a hammer; this book teaches you how to use the hammer. If you aspire to be a technical leader in AI and want to learn how to set direction for your team, this book will help.
We have read the draft, and selected 7 most interesting and useful suggestions from the book:
- Optimizing and satisficing metrics
Rather than use a single formula or metric to evaluate an algorithm, you should consider utilising multiple evaluation metrics. One way of doing this is by having an “optimizing” and “satisfying” metric.
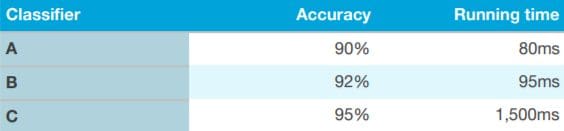
Using the above example, we can first define what is an acceptable running time – say anything less than 100ms – and this can be our “satisfying” metric. Your classifier just has to be ‘good enough’ by having a running time below this and nothing more. Accuracy here is the “optimizing” metric. This can be an extremely efficient and easy way of evaluating your algorithm.
- Choose dev/test sets quickly—don’t be afraid to change them if needed
When starting out a new project, Ng explains that he tries to quickly choose dev/test sets, thus giving his team a well-defined target to aim for. An initial one-week target is set; it is better to come up with something not perfect and get going quickly, rather than overthink this stage.
With that being said, if you suddenly realize that your initial dev/test set isn’t right, don’t be afraid to change. Three possible causes for an incorrect dev/test set being chosen are:
- The actual distribution you need to do well on is different from the dev/test sets
- You have overfit the dev/test set
- The metric is measuring something other than what the project needs to optimize
Remember, changing this isn’t a big deal. Just do it and let your team know the new direction you are heading in.
- Machine Learning is an iterative process: Don’t expect it to work first time
Ng states that his approach to building machine learning software is threefold:
- Start off with an idea
- Implement the idea in code
- Carry out an experiment to conclude how well the idea worked
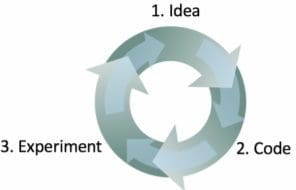
The faster you can go around this loop, the quicker progress will be made. This is also why having test/dev sets chosen beforehand is important as it can save valuable time during the iterative process. Measuring performance against this set can enable you to quickly see if you’re heading in the right direction.
- Build your first system quickly and then iterate
As mentioned in point 3, building a machine learning algorithm is an iterative process. Ng dedicates a chapter to explaining the benefits of building a first system quickly and going from there: “Don’t start off trying to design and build the perfect system. Instead, build and train a basic system quickly—perhaps in just a few days. Even if the basic system is far from the “best” system you can build, it is valuable to examine how the basic system functions: you will quickly find clues that show you the most promising directions in which to invest your time.”
- Evaluate multiple ideas in parallel
When your team has numerous ideas on how an algorithm can be improved, you can efficiently evaluate these ideas in parallel. Using an example of a creating an algorithm that can detect pictures of cats, Ng explains how he would create a spreadsheet and fill it out while looking through ~ 100 misclassified dev/test set images.

Included is an analysis of each image, why it failed and any additional comments that may help upon future reflection. On completion you can see which idea(s) will eliminate more errors and therefore which should be pursued.
- Consider if cleaning up mislabeled dev/test sets is worthwhile
During your error analysis, you may notice that some examples in your dev/test set have been mislabeled. I.e. the images have already been incorrectly labeled by a human. If you suspect that a fraction of the errors are due to this, add an additional category in your spreadsheet:
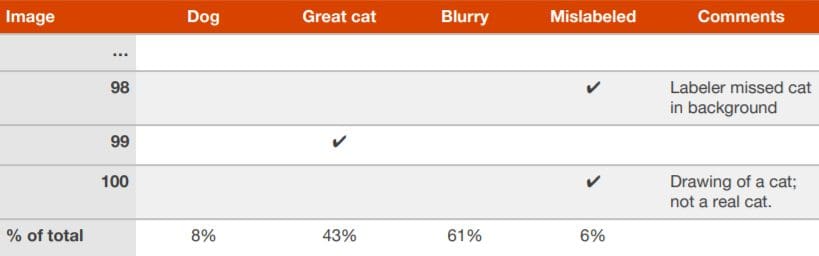
Upon completion you can then consider if it is worth the time to fix these. Ng gives two possible scenarios to judge if it is worth fixing these:
Example 1:
Overall accuracy on dev set.………………. 90% (10% overall error)
Errors due to mislabeled examples……. 0.6% (6% of dev set errors)
Errors due to other causes………………… 9.4% (94% of dev set errors)
“Here, the 0.6% inaccuracy due to mislabeling might not be significant enough relative to the 9.4% of errors you could be improving. There is no harm in manually fixing the mislabeled images in the dev set, but it is not crucial to do so: It might be fine not knowing whether your system has 10% or 9.4% overall error”
Example 2:
Overall accuracy on dev set.………………. 98.0% (2.0% overall error)
Errors due to mislabeled examples……. 0.6%. (30% of dev set errors)
Errors due to other causes………………… 1.4% (70% of dev set errors)
“30% of your errors are due to the mislabeled dev set images, adding significant error to your estimates of accuracy. It is now worthwhile to improve the quality of the labels in the dev set. Tackling the mislabeled examples will help you figure out if a classifier’s error is closer to 1.4% or 2%—a significant relative difference.”
- Contemplate splitting dev sets into separate subsets
Ng explains that if you have a large dev set in which 20% have an error rate, that it may be worth splitting these out into two separate subsets:
“Using the example in which the algorithm is misclassifying 1,000 out of 5,000 dev set examples. Suppose we want to manually examine about 100 errors for error analysis (10% of the errors). You should randomly select 10% of the dev set and place that into what we’ll call an Eyeball dev set to remind ourselves that we are looking at it with our eyes. (For a project on speech recognition, in which you would be listening to audio clips, perhaps you would call this set an Ear dev set instead). The Eyeball dev set therefore has 500 examples, of which we would expect our algorithm to misclassify about 100.
The second subset of the dev set, called the Blackbox dev set, will have the remaining 4500 examples. You can use the Blackbox dev set to evaluate classifiers automatically by measuring their error rates. You can also use it to select among algorithms or tune hyperparameters. However, you should avoid looking at it with your eyes. We use the term “Blackbox” because we will only use this subset of the data to obtain “Blackbox” evaluations of classifiers.”
Related: