 A Basic Recipe for Machine Learning
A Basic Recipe for Machine Learning
 A Basic Recipe for Machine Learning
A Basic Recipe for Machine LearningOne of the gems that I felt needed to be written down from Ng's deep learning courses is his general recipe to approaching a deep learning algorithm/model.
By Hafidz Zulkifli, Data Scientist at Seek
Ever since wrapping up the three Deep Learning courses by Andrew Ng I’ve been meaning to write down some of the gems that he’s highlighted throughout the course.
One of the nice ones that I felt needed to be written down is his general recipe to approaching a deep learning algorithm/model.
I’ve basically summarized it in a flowchart below (because everybody loves a flow chart right?)
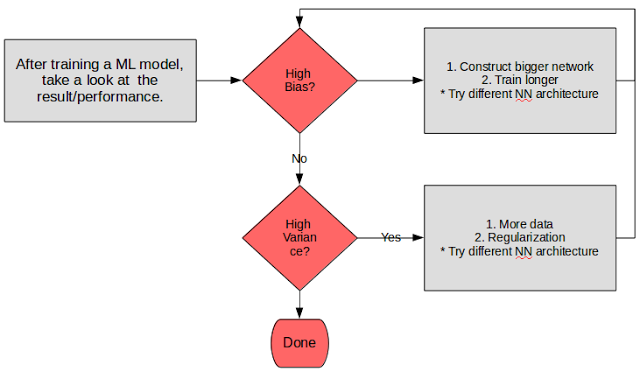
Basic deep learning recipe
What is bias and variance? The below diagram is the typical explanation that I’m sure most of us are used to.
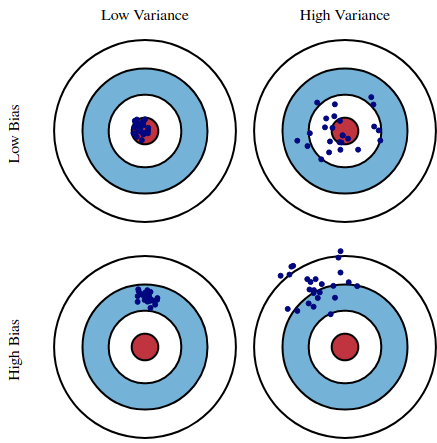
Graphical illustration of bias and variance
How can we know if we have high bias or high variance?
For high bias, we could take a look at the training set performance. A poor performance is an indicator of a poor model fit, and signals that we could try to apply a bigger network to get a better fit of the model.
For high variance, we could take a look at the validation set (or dev set — as Andrew calls it) performance. A poor performance of this set (while getting a good result for training), is an indicator that our model has high variance, and is not flexible enough to process the validation set that we have. It could signal one of 2 things — either our validation was ill-prepared (in that there could be class imbalance) or our model is not generalized enough. Hence what we could do to fix this is to add more data and apply regularization techniques to make our model more robust.
Back when I was learning machine learning, there was always this belief that bias and variance is something of a tradeoff — you can always increase one, but you need to sacrifice the other.
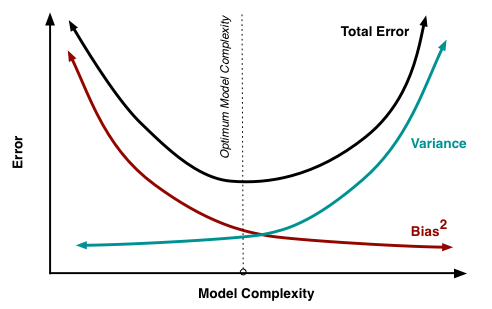
Bias and variance contributing to total error.
However in the age of big data and deep learning, Andrew proposes that the tradeoff may just be a thing in the past.
How so?
With deep learning, we now have a system to fit any kind of data, by means of building a big enough network to learn about the data. And this is where big data comes in — as we would need a big enough amount of data to be able to teach our model. In fact, such is the case in that deep learning is seen to be able to surpass any type of machine learning model out there.
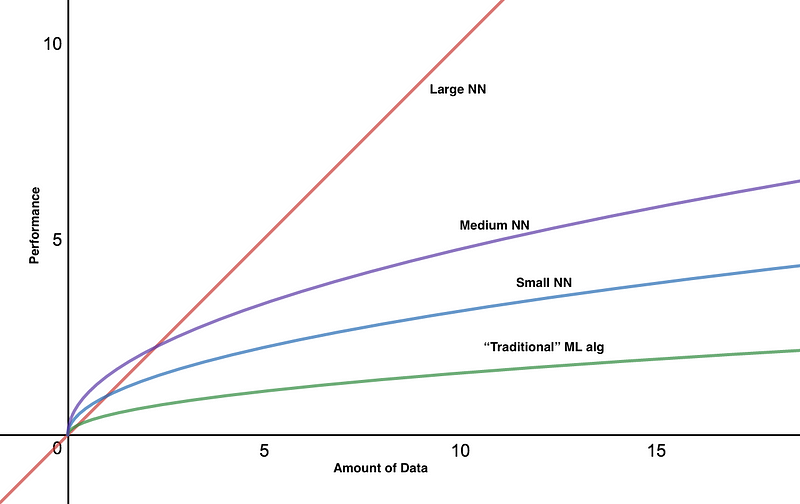
A comparison of model accuracy vs data amount
Hence if we have low accuracy in our training set — we could add more nodes to our neural network.
If our validation is not performing due to high variance — add more data.
However it has to be emphasised that our model needs to be properly regularized as well for the above assumptions to hold true.
Does this mean that deep learning is the answer to every prediction problems that we have? I’d argue — probably not.
First and foremost, let’s look at the first proposed action — building bigger networks. A big network requires high computation power, which might involve using multiple GPUs to speed up the process. To my knowledge, there’s not a lot of enterprises that are savvy enough (at the time of writing) to want to actually buy GPUs as part of their analytics solution stack (most would probably just invest in big servers with huge memory). Thus building a model then becomes an issue as it would take a long time for a model to be trained (not to mention the multiple iterations needed to fine tune it).
Secondly, let’s talk about big data.

It’s not enough to just have big data in your data lake for data scientists to do machine learning — it needs to be labelled as well.
Labelled data has become such a big problem in and on itself that it has spawned many companies to provide you the solution to do just that — manually label your data. Be that as it may, there’s only so much that they can label, and I doubt that it’ll ever reach the level of — “big data”.
So to me this is where algorithms like decision trees, SVM and others can play a role. In fact, I’m rather confident in saying that you probably don’t need to apply deep learning in most of the problems faced in most of enterprises/companies/SMEs out there (unless of course, you’re working in some niche fields that deals with an abundance of data such as image processing, advertising, and text processing).
Going back to my earlier argument on companies not buying GPUs — I suppose it’s not so much related to them not being savvy — it’s just it’s not even needed to solve their problems (now that I think about it, having more RAM makes more sense to be honest). It’s about having the right tool for the right problem (and being able to justify the cost of that tool to your finance department — but that’s a different story).
For more details on the subject mentioned in this post, do check out the references below.
References:
- Understanding the Bias Variance Tradeoff: http://scott.fortmann-roe.com/docs/BiasVariance.html
- DeepLearning.ai: Basic Recipe For Machine Learning video
Bio: Hafidz Zulkifli is a Data Scientist at Seek in Malaysia.
Original. Reposted with permission.
Related:
- Understanding Learning Rates and How It Improves Performance in Deep Learning
- An Overview of 3 Popular Courses on Deep Learning
- Using Deep Learning to Solve Real World Problems