Taming LSTMs: Variable-sized mini-batches and why PyTorch is good for your health
After reading this, you’ll be back to fantasies of you + PyTorch eloping into the sunset while your Recurrent Networks achieve new accuracies you’ve only read about on Arxiv.
By William Falcon, PhD Candidate, AI, Neuroscience (NYU)

If you’ve used PyTorch you have likely experienced euphoria, increased energy and may have even felt like walking in the sun for a bit. Your life feels complete again. That is, until you tried to have variable-sized mini-batches using RNNs.
All hope is not lost. After reading this, you’ll be back to fantasies of you + PyTorch eloping into the sunset while your Recurrent Networks achieve new accuracies you’ve only read about on Arxiv.
Ninja skills we’ll develop:
- How to implement an LSTM in PyTorch with variable-sized sequences in each mini-batch.
- What pack_padded_sequence and pad_packed_sequence do in PyTorch.
- Masking padded tokens for back-propagation through time.
TL;DR version: Pad sentences, make all the same length, pack_padded_sequence, run through LSTM, use pad_packed_sequence, flatten all outputs and label, mask out padded outputs, calculate cross-entropy.
Why is this so hard and why do I care?
Speed and Performance.
Feeding variable length elements at ONCE into an LSTM has been a huge technical challenge which frameworks like PyTorch have largely solved (Tensorflow also has a nice abstraction but it’s very very very involved).
Furthermore, the documentation is unclear and examples are too old. Properly doing this will speed up training AND increase the accuracy of gradient descent by having a better estimator for the gradients from multiple examples instead of just ONE.
Although RNNs are hard to parallelize because each step depends on the previous step, we can get a huge boost by using mini-batches.
Sequence Tagging
While I can’t help you with your Justin Bieber obsession (I won’t tell), I can help you do part of speech tagging on your favorite JB song, Sorry.
Here’s an example of the model with the song sentence: “is it too late now to say sorry?” (removed ‘to’ and ‘?’ ).
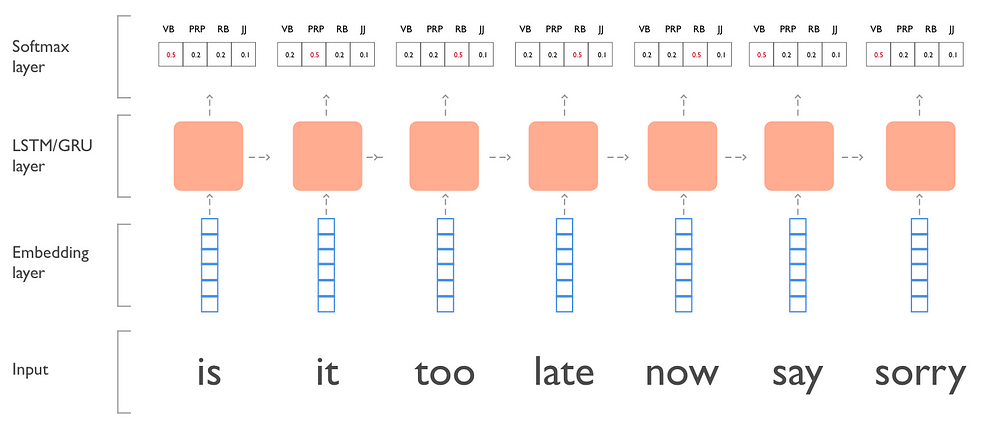
LSTM/GRU model we’re building
Data Formatting
While you can do a ton of formatting, we won’t... For simplicity, let’s make this contrived batch of data with different sized sequences.
sent_1_x = ['is', 'it', 'too', 'late', 'now', 'say', 'sorry'] sent_1_y = ['VB', 'PRP', 'RB', 'RB', 'RB', 'VB', 'JJ'] sent_2_x = ['ooh', 'ooh'] sent_2_y = ['NNP', 'NNP'] sent_3_x = ['sorry', 'yeah'] sent_3_y = ['JJ', 'NNP'] X = [sent_1_x, sent_2_x, sent_3_x] Y = [sent_1_y, sent_2_y, sent_3_y]
When we feed each sentence to the embedding layer, each word will map to an index, so we need to convert them to list of integers.
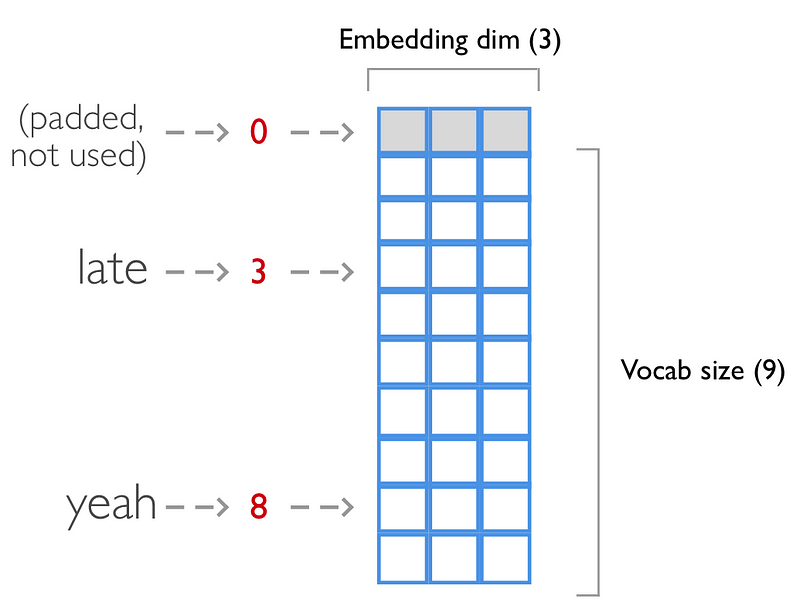
Here we map these sentences to their corresponding vocabulary index
# map sentences to vocab
vocab = {'': 0, 'is': 1, 'it': 2, 'too': 3, 'late': 4, 'now': 5, 'say': 6, 'sorry': 7, 'ooh': 8, 'yeah': 9}
# fancy nested list comprehension
X = [[vocab[word] for word in sentence] for sentence in X]
# X now looks like:
# [[1, 2, 3, 4, 5, 6, 7], [8, 8], [7, 9]]
Same for the classification labels (in our case POS tags). These won’t be embedded.
tags = {'': 0, 'VB': 1, 'PRP': 2, 'RB': 3, 'JJ': 4, 'NNP': 5}
# fancy nested list comprehension
Y = [[tags[tag] for tag in sentence] for sentence in Y]
# Y now looks like:
# [[1, 2, 3, 3, 3, 1, 4], [5, 5], [4, 5]]
Trick 1: Make all sequences in the mini-batch have the same length by padding.
What is in a box and has all different lengths? Not our mini-batch!
For PyTorch to do its thing, we need to save the lengths of each sequence before we pad. We’ll use this information to mask out the loss function.
import numpy as np
X = [[0, 1, 2, 3, 4, 5, 6],
[7, 7],
[6, 8]]
# get the length of each sentence
X_lengths = [len(sentence) for sentence in X]
# create an empty matrix with padding tokens
pad_token = vocab['']
longest_sent = max(X_lengths)
batch_size = len(X)
padded_X = np.ones((batch_size, longest_sent)) * pad_token
# copy over the actual sequences
for i, x_len in enumerate(X_lengths):
sequence = X[i]
padded_X[i, 0:x_len] = sequence[:x_len]
# padded_X looks like:
array([[ 1., 2., 3., 4., 5., 6., 7.],
[ 8., 8., 0., 0., 0., 0., 0.],
[ 7., 9., 0., 0., 0., 0., 0.]])
We do the same for the tags:
import numpy as np
Y = [[1, 2, 3, 3, 3, 1, 4],
[5, 5],
[4, 5]]
# get the length of each sentence
Y_lengths = [len(sentence) for sentence in Y]
# create an empty matrix with padding tokens
pad_token = tags['']
longest_sent = max(Y_lengths)
batch_size = len(Y)
padded_Y = np.ones((batch_size, longest_sent)) * pad_token
# copy over the actual sequences
for i, y_len in enumerate(Y_lengths):
sequence = Y[i]
padded_Y[i, 0:y_len] = sequence[:y_len]
# padded_Y looks like:
array([[ 1., 2., 3., 3., 3., 1., 4.],
[ 5., 5., 0., 0., 0., 0., 0.],
[ 4., 5., 0., 0., 0., 0., 0.]])
Data processing summary:
We turned words into sequences of indexes and padded each sequence with a zero so the batch could all be the same size. Our data now look like:
# X
array([[ 1., 2., 3., 4., 5., 6., 7.],
[ 8., 8., 0., 0., 0., 0., 0.],
[ 7., 9., 0., 0., 0., 0., 0.]])
# Y
array([[ 1., 2., 3., 3., 3., 1., 4.],
[ 5., 5., 0., 0., 0., 0., 0.],
[ 4., 5., 0., 0., 0., 0., 0.]])
The model
We’ll make a very simple LSTM network using PyTorch. The layers will be:
- Embedding
- LSTM
- Linear
- Softmax
Trick 2: How to use PyTorch pack_padded_sequence and pad_packed_sequence
To recap, we are now feeding a batch where each element HAS BEEN PADDED already. In the forward pass we’ll:
- Embed the sequences
- Use pack_padded_sequence to make sure the LSTM won’t see the padded items
- Run the packed_batch into the LSTM
- Undo the packing by using pad_packed_sequence
- Transform the lstm output so we can feed to linear layer
- Run through log_softmax
- Convert shape back so we finish with (batch_size, seq_len, nb_tags)
Trick 3: Mask out network outputs we don’t want to consider in our loss function

Mask out those padded activations
Finally, we’re ready to calculate the loss function. The main point here is that we don’t want to take into account the network output for padded elements.
Intuition alert: Best way to think about doing this is to FLATTEN ALL network outputs AND labels. Then calculate the loss on that ONE sequence.
Waaaaaaaa… It’s that easy. Now you can train your model MUCH faster with mini-batches and get back to obsessing over JB (still won’t tell, don’t worry).
I know how you’re feeling now…

This is of course a very barebones LSTM. Things you can do to fancy up your model (not comprehensive):
- Initialize with Glove embeddings.
- Use GRU cell.
- Use Bidirectional mechanism (don’t forget to modify init_hidden).
- Use character level features by creating an encoding vector with a Convolutional network and appending to the word vector.
- Add dropout.
- Increase number of layers
- … soooo much more
- And of course, a very thorough hyper-parameter search using the best hyperparemeter optimization library for Python: test-tube (disclaimer: I wrote test-tube).
In Summary:
This is how you get your sanity back in PyTorch with variable length batched inputs to an LSTM
- Sort inputs by largest sequence first
- Make all the same length by padding to largest sequence in the batch
- Use pack_padded_sequence to make sure LSTM doesn’t see padded items (Facebook team, you really should rename this API).
- Undo step 3 with pad_packed_sequence.
- Flatten outputs and labels into ONE LONG VECTOR.
- Mask out outputs you don’t want
- Calculate cross-entropy on that.
Full Code:
Bio: William Falcon is a PhD Candidate, AI, Neuroscience (NYU), and Co-Founder @Nextgenvest. He is a former Product Manager and iOS Eng. Prior at Goldman Sachs, Bonobos, Columbia.
Original. Reposted with permission.
Related:
- PyTorch Tensor Basics
- Getting Started with PyTorch Part 1: Understanding How Automatic Differentiation Works
- A Guide For Time Series Prediction Using Recurrent Neural Networks (LSTMs)