Why the Data Lake Matters
This post outlines why the data lake matters, outlining the complexity of a data lake and taking a look at its evolution over time.
By Yoni Iny, CTO of Upsolver
In an article published on this site, Uli Bethke claims that the term “Data Lake” has become overloaded, ill-defined and blurry, and is no longer useful from a conceptual and practical standpoint.
While the article presents several convincing, well-reasoned arguments, I would like to dispute its conclusion. From there I will proceed to make the case for the Data Lake, as a concept and as a highly relevant approach to modern big data architectures.
Getting our Definitions in Order
One of Mr. Bethke’s main grievances with the Data Lake is how fuzzy the term itself has become, which he says is being used to describe “anything that does not fit into the traditional data warehouse architecture”, resulting in poorly defined terminology that eventually leads to bad technology decisions.
To an extent, there’s some truth to this - a single, clear-cut definition of the Data Lake is difficult to come across. However, this murkiness stems from the fact that these architectures have only been gaining ‘mainstream’ popularity in recent years, and does not invalidate the core concept.
Similarly, twenty years ago very few people were talking about “data analytics”, and today the term is still vague in the sense that it is commonly used to describe everything from interactive dashboards to neural networks - but I doubt many people would go so far as to claim it’s completely meaningless on account of this.
Still, some definition has to be given - and I would suggest this one:
The Data Lake is an approach to big data architecture that focuses on storing unstructured or semi-structured data in its original form, in a single repository that serves multiple analytic use cases or services.
I will use this definition as a framework to address a few of the other points in the original article, and more importantly - to explain why this concept is useful, and why we need to keep talking about Data Lakes in technology and business.
The Case for the Data Lake
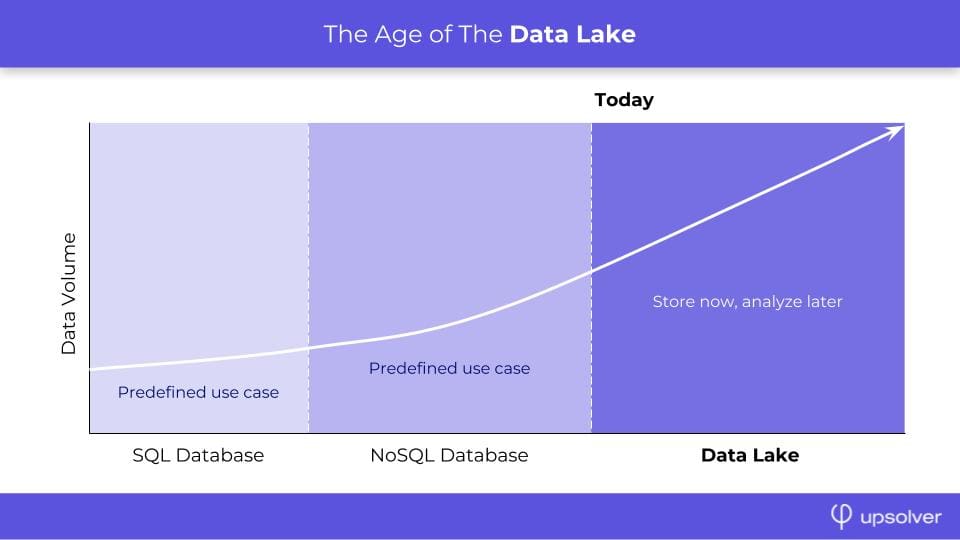
Hopefully, we have gotten the matter of the definition out of the way - but the question is not merely one of semantics. Once we understand the data lake as a means of working with certain types of data, its significance becomes clear. Data lakes are extremely relevant for event-based, streaming data, typically generated by sources such as web application logs and sensors in IoT devices.

This type of data, often created in small bursts, at high velocity and high volumes, is ill-suited for the traditional data warehouse approach, where we impose schema-on-write and a consistent data model in advance. Trying to do this with streaming data will invariably lead to data being lost, or to cumbersome engineering processes being required in order to continuously ingest the data. The size of data matters a lot as well. Data lakes will often cost one or two orders of magnitude less per GB of data than a comparable data warehouse, so as useful data size grows, the cost difference becomes more and more meaningful.
As the original article rightfully states, this does not apply to every organization and every use case. You don’t need a data lake to store payroll data. However, as cloud adoption grows, and as an increasing amount of companies offer some kind of online service or app, streaming data is rapidly becoming more commonplace. Refusing to talk about data lakes is ignoring the reality of the modern business world for many organizations.
Facilitating Self-service Sandboxes
Mr. Blethke’s article makes an excellent case for “self-service sandboxes”, where analysts and data engineers can work with specific datasets to solve specific data problems, rather than directly querying the cluster. I wholeheartedly agree with this approach - but not only does it not negate a data lake architecture, it is actually a strong supporting argument for it.
The main reasoning behind this is the fact that using a data lake ensures the accuracy of the data and the ability to replay and recover in case of errors. Facilitating several use cases and “sandboxes” is much easier when you store the raw event data and can use it as your single source of truth, versus having to transform the data in order to force it into (or out of) your data warehouse. Additionally, data warehouses are scaled to their workload, so adding a new output can be a bottleneck. Data lakes do not have hard scaling limits, so adding additional outputs is much easier.
It’s true that currently a lot of big data engineering is often required in order to move the data from the data lake into these data science and analytics environments. However, this stresses the need for data lake technologies to continue to evolve through new services and products that can simplify these processes and reduce reliance on data engineering.
Several such companies are already operating. Upsolver, which I have co-founded, offers a Data Lake platform to manage and transform streaming data in the Cloud; similar offerings meant to tackle various steps in the process of managing, integrating and analyzing data streams are offered by publicly traded companies such as Talend, as well as startups such as Databricks and Qubole.
We are bound to see this ecosystem of innovation continue to grow over time, as long as we continue to foster a strong understanding of the data lake approach and its unique challenges.
An Evolving Landscape
A few decades ago the idea that non-IT workers would work directly with relational databases seemed ludicrous; today it is common practice thanks to advancement in analytics tools. Within a few years, this could very well be the case with data lakes - but refusing to acknowledge the validity of the term will not help us get there.
Furthermore, with many enterprises and start-ups already working with some form of data lake architecture in practice, it only makes sense that we keep talking about data lakes specifically in order to better understand them and develop a more comprehensive set of best practices.
For these reasons, it’s wrong to dismiss all data lakes as “fake news”. Instead, we should keep talking about them, improving the technologies and building a future where organizations can more easily get clear business value from their streaming data.
Bio: Yoni Iny is the CTO of Upsolver, which provides a leading Data Lake Platform for AWS S3, and is a technologist specializing in big data and predictive analytics. Before co-founding Upsolver, he worked in several technology roles, including as CTO of the data science department at the IDF’s elite technology unit.
Related: