Beyond Data Lakes and Data Warehousing
We give a comprehensive review of data lakes and data warehouses, and look at what the future holds for total data integration.
By dataWerks.

Perhaps you can remember the debate over VHS versus Betamax. It raged in the 1980s as consumers desperately advocated the type of machine they had just purchased. And the winner was: digital! First, the DVD and now Netflix! The point being: revolutionary new technologies always win out in the end and render debate over evolutionary technology moot.
Today, I think there’s a strong argument to be made that Data Lakes may be the Betamax of our time. Of course, this makes Data Warehouses the VHS. Don’t get me wrong. Betamax and VHS were both great technologies for their time. They allowed us to watch movies at home where and when we chose. But you had to rewind the tapes! You had to run to the video store in the middle of winter to rent a new movie! Ugh! If anybody thinks those times were better then I have some stock in Blockbuster Video stores I’d like to sell you.
I will argue that Data Warehouses and Data Lakes have seen their best days as evolutionary technologies and that a revolutionary technology is looming that could replace them altogether. Controversial territory where clear answers are not easy to find. There is a lot of media noise, vendor propaganda and, as always, a lot of money to be made selling IT technology so it’s a bit of a mystery where the truth lies. To solve the mystery, I’ll use classic crime detective techniques like ‘follow the money’ and ‘read between the lines’ to help solve the mystery and then look beyond Data Lakes to see what’s next. But first, some background.
A VERY BRIEF HISTORY OF DATA WAREHOUSES AND DATA LAKES
The story begins with Decision Support which was the old trendy term which is being replaced by the new trendy term Business Intelligence (BI) and the even newer and trendier Analytics. Regardless of the term, the idea was that companies needed to make better decisions based on the data stored in their various operational systems and databases. So two guys from IBM came up with the idea of the Data Warehouse in the late 1980s. Their concept was to consolidate data from the various systems and databases into a single database, that is, a Data Warehouse, to serve as the source for creating analytics and reporting, that is, delivering decision support.
It was a great idea and it worked! It was the first real step towards data integration because it solved the problem of isolated and heterogenous data stores, commonly referred to as data silos, by providing a single database for reporting and analysis. Some work was involved though. You had to understand the data, then architect a new data model for the Data Warehouse and then you had to Extract, Transform and Load the data, as illustrated below:
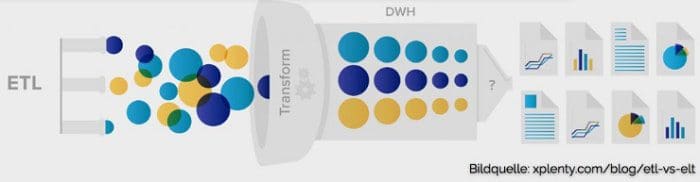
I’ve used a barb wire fence to illustrate the process of creating a Data Warehouse because it really was (and still is) quite cumbersome, costly and time-consuming — often stretching out for months, or even years. Duplicating data, staging data, integration layers, replication layers, temporary databases… Argh. This may have been cool at IBM back in the 1980s but it’s not so cool anymore because all of this costs big bucks to implement.
Not to mention the biggest bucks of all which are spent architecting the new data model required for a Data Warehouse. Data Lake vendors have pegged the cost at about $250,000 per terabyte for building a Data Warehouse. Of course, they are trying to vend you some Data Lakes so this may be a bit high, but whatever the exact cost, it is undeniably very significant, and grows almost exponentially with the avalanche of big data from the Internet of Things and other sources. Rigid Data Warehouses and their brittle data models simply can’t keep up. Enter the Data Lake.
DATA LAKE ARCHITECTURE
The concept of a Data Lake has emerged in the last several years, primarily as an antidote to the fundamental flaw of Data Warehouses – their rigidity and inability to deal with the onslaught of big data. The basic idea with a Data Lake is: forget about all the extracting and transforming, architecting, layers, etc. — for now — and just dump all your data down into a great big lake and let the Data Scientists and SQL gurus figure it out, as illustrated below:
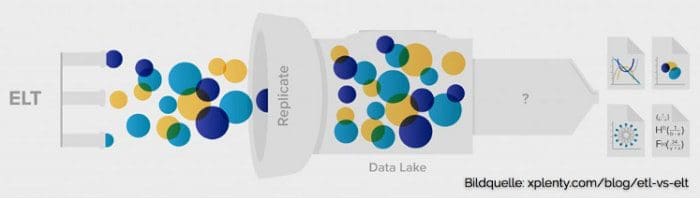
Yes, Data Lakes are largely Hadoop-based which is super-trendy right now, and yes, it does solve the problem of heterogeneous data, in that Data Lakes can handle structured, semi-structured and unstructured data, which is all important these days. But, is it just me, or does this sound a lot like procrastination? Why all the hype? Let’s follow the money to find out.
Data Lake vendors boast a 20X, to 50X to 100X reduction in cost. From $250,000 per terabyte down to as little as $2,500 per terabyte they say. Brilliant! Big data problem solved. Just store it all and figure it out later. Phew!
Not so quick. There’s a reason why the Internet is now rife with articles about fixing and figuring out your Data Swamp or your Data Graveyard. Swamp and graveyard being two of the more printable names that I can use in this article. I’m not joking here. Witness #1: Daniel Newman writing in Forbes: 6 Steps to Clean up your Data Swamp. Witness #2: Samantha Custer et al writing on AIDDATA: Avoiding Data Graveyards.
DATA LAKE ANALYTICS? OR DATA SWAMPS
So Data Lakes are a suspect. To find more proof that something is amiss here, let’s read between the lines of PriceWaterhouseCoopers’s piece entitled: The Enterprise Data Lake: Better integration and deeper analytics. Sounds rosy doesn’t it?
They write that Data Lakes have “nearly unlimited potential for operational insight and data discovery”. Cool! Potential is good. But then a caveat: “Analytics drawn from the lake become increasingly valuable as the metadata describing different views of the data accumulates.” Okay maybe my metadata will accumulate like the mold in my pond. I can live with that.
But then there’s trouble: “for those accustomed to SQL, this shift opens a whole new world”. Okay so that rules out 99.9% of people ever using the data lake, especially most business users who are just happy when their report comes out on the printer (no offence intended – I’m talking about myself here). Conclusion from PWC: “Some data lake initiatives have not succeeded, producing instead more silos or empty sandboxes”. Early adopter anxiety right? No reason not to dive in: “Given the risk, everyone is proceeding cautiously”. Okay maybe I’ll just tip my toe in the water first.
All joking aside, if you think that PWC is giving a ringing endorsement for Data Lakes then I would like to sell you some swampland in Florida. Okay I’m not putting the joking aside. It’s more fun this way.
Need more proof. With Uli Bethke of Sonra, you don’t even have to read between the lines. He puts it on the lines: “Are data lakes fake news? The quick answer is yes…”. It is worth quoting him at length:
Vendors and analysts often combine the concept of the raw data reservoir with the idea of self-service analytics. In this data fairy tale business users tap into the central “data lake” to generate insights without involvement of IT or the new bad boy ETL. Throw in a bit of data governance and a tool (data discovery/preparation) and you are good to go. Sounds too good to be true? Well it is.
Suffice to say, there are some issues here. Data Lakes can easily turn into data swamps. Of course, you can always go with a Data Lake today and ‘drain the swamp’ later on, but just ask Donald Trump how easy that is to do.
WHAT LIES BEYOND?
Swamps and graveyards. Sounds like a horror movie. Is there hope on the horizon? Of course, but understanding it requires a bit of a paradigmatic shift in thinking. The answer lies at the scene of the crime, of course, and if you look closely at the two illustrations shown above they hint at a solution.
First of all, why all the extracting, loading, architecting, moving, replicating and duplicating of data? Why not just use the original source data? Any child who has played the broken telephone game knows that with every additional person that is involved the original message gets more and more garbled. “Let’s play football today” can easily become “Lots of plans afoot to get Dave”. The only message that is ever clear is the one at the source. The same is true of data storage. Every generation further away from the source introduces garble.
Second, what do all of these attempts at total data integration have in common? Understand. In technical terms, this involves understanding the data, the metadata, the relationships, the correlations, the operational procedures around the data and so forth. Any attempt to deliver valuable BI must begin with understanding the data. This is where the true value really is.
And this is the starting point for total data integration solutions like the one from dataWerks, an emerging leader in the field of data integration. We discard all of the unnecessary extracting, transforming, loading, architecting: rather than ‘move’ all of the data out of the source we connect directly to the source with our over 200 pre-defined data connectors. So what we’re left with is to Understand the data. And to build understanding, we focus on the source data because it is always the most accurate. This is illustrated below:
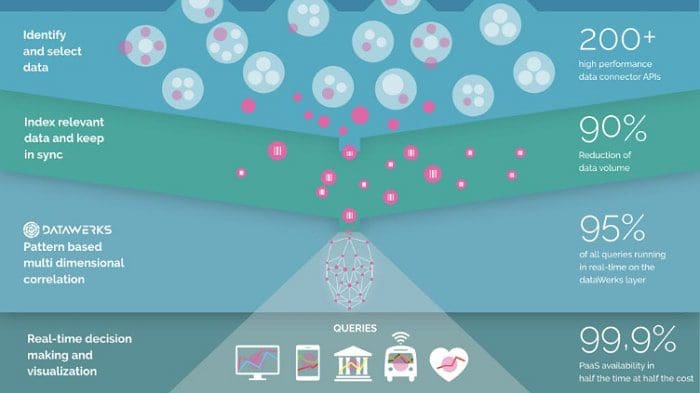
Put another way, Data Warehouses and Data Lakes are attempts to build a ‘single source of truth’. They both advocate a ‘central repository’ or a ‘single source of truth’. But the only real source of truth lies at the origin. Detectives talk to witnesses not the witness’s best friend who got the story second hand.
Once we understand the original data, we focus on ‘picking the data’ that business users really want and and ensure that it can be delivered in real-time. Typically, only 10% of a company’s data yields valuable BI so we focus on that. That is, we ‘slim down’ your data rather than ‘bulking it up’ and we put the most crucial data at the fingertips of your business users. On the frontend, we have pre-defined connectors to all the most popular Analytics tools, such as Tableau, Qlik and Power BI.
Bottom line: real time BI available in your favourite Analytics tool. No new architecture. No new data model. No extract. No transform. No load. This sounds like Data Nirvana. It sounds like a revolution. Indeed it is! At long last, this is a realisation of the dream of every CEO, manager, in fact anyone who is on the line to deliver business results: actionable BI available immediately that is based on the full spectrum of data available in your company.
The applications of this technology are almost unlimited. One of the most exciting for customer-focused businesses (and who can’t be these days) is achieving the ever-elusive 360 degree customer view. It’s possible now and one of our early adopters has proven it. A total and complete understanding of your customer is no longer science fiction. We helped make it happen for one of the largest corporations in the world!
DATA NIRVANA: TOTAL DATA INTEGRATION AND REAL TIME BI
A Fortune 100 media company that operates theme parks worldwide was searching for not just a big data solution, but the very biggest of big data solutions: 150,000 customers daily with wearable RFID devices, creating billions of data records, stored in 40 different data stores, with half a billion of those records requiring analysis each day, in order to deliver real-time BI which, in turn, would be used to enhance the customer experience.
Dinner ready, and hot, and on your table when you show up at the theme park restaurant! Big line at the roller coaster? Here’s a discount coupon to buy merchandise while you wait. This was their vision. So even a few hours delay of the data delivery would mean the data would be rendered useless because the customer would have already returned home. Prior to our involvement, it sometimes took 36 hours to deliver the data they needed.
On top of all this, the customer envisioned an ambitious half a billion dollars of additional revenue based largely on delivering real-time BI which could, in turn, be used to enhance the customer experience and increase customer revenues accordingly (e.g., buying merchandise instead of standing in long lineups getting angrier by the minute).
So if you still think a Data Lake or Data Warehouse would be the best solution here then I have a shiny new VHS player I would like to sell you. Indeed, the usual suspects were brought in and some attempts were made to apply traditional solutions, but you don’t have to be a mathematician to know that replicating even a few of the 40 data sources would have led to big trouble. The only solution is to go straight to the sources and understand the data and then ‘data pick’ only the most critical data and that is exactly what dataWerks did for this customer.
Today, the customer has reached their target of an additional half a billion revenue annually growing largely out of a project that involved five of our consultants for less than a year and a negligible investment in hardware.
That’s a revolution!
THE REVOLUTION WILL BE INTEGRATED
The Internet of Things and wearable devices have brought a whole new world of opportunities. The future is now, but as with any revolution, a paradigm shift is required. For 40 years we’ve been moving data around, but this simply does not make sense any more. Data Warehouses and Data Lakes have served us well, but newer and better technology is now available.
Most companies today are inundated with data on a daily basis. Why double it or triple it? Understand your data. Connect to the source. Connect to your favourite frontend tool and you are off to the races. No significant hardware investment required. No architecting required. No extracting. No transforming. No loading. A total data integration solution in weeks, not months or years.
The revolution is here. Talk to us at datawerks to find out more!
Related: