 Only Numpy: Implementing GANs and Adam Optimizer using Numpy
Only Numpy: Implementing GANs and Adam Optimizer using Numpy
 Only Numpy: Implementing GANs and Adam Optimizer using Numpy
Only Numpy: Implementing GANs and Adam Optimizer using NumpyThis post is an implementation of GANs and the Adam optimizer using only Python and Numpy, with minimal focus on the underlying maths involved.
By Jae Duk Seo, Ryerson University
So today I was inspired by this blog post, “Generative Adversarial Nets in TensorFlow” and I wanted to implement GAN myself using Numpy. Here is the original GAN paper by @goodfellow_ian. Below is a gif of all generated images from Simple GAN.
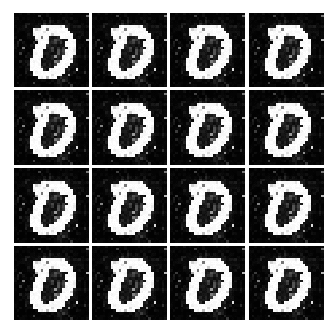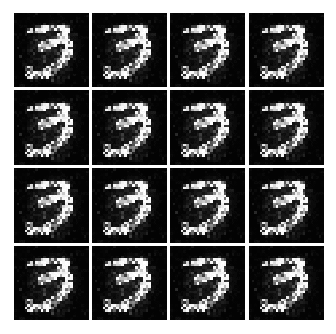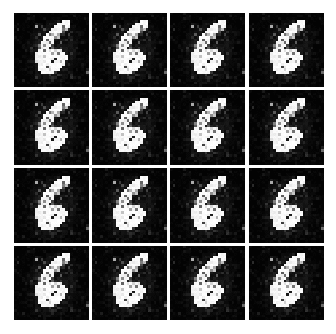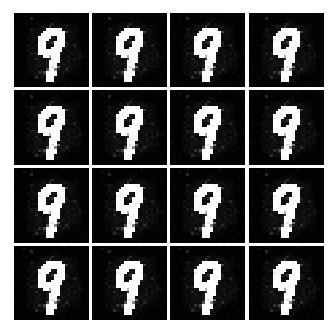
Before reading along, please note that I won’t be covering too much of math. Rather the implementation of the code and results, I will cover the math maybe later. And I am using Adam Optimizer, however, I won’t go into explaining the implementation of Adam at this post.
Forward Feed / Partial Back Propagation of Discriminator in GAN

Again, I won’t go into too much details, but please note the Red Boxed Region called Data. For the Discriminator Network in GAN, that Data either can be Real Image or Fake Image Generated by the Generator Network. Our images are (1,784) vector of MNIST data set.
One more thing to note is Red (L2A) and Blue (L2A). Red (L2A) is the final output of our Discriminator Network with Real Image as input. And Blue (L2A) is the final output of our Discriminator Network with Fake Image as input.

The way we implement this is by getting the real image, and fake data before putting them both into the network.
- Line 128 — Getting the Real Image Data
- Line 147 — Getting the Fake Image Data (Generated By Generator Network)
- Line 162 — Cost Function of our Discriminator Network.
Also, please take note of the Blue Box Region, that is our cost function. Lets compare the cost function from the original paper, shown below.
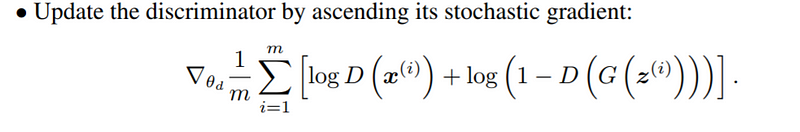
Image from original Paper
The difference is the fact that we are putting a (-) negative sign in front of the first term log(L2A).

Image from Agustinus Kristiadi
As seen above, in TensorFlow implementation we flip the signs if we want to Maximize some value, since TF auto differentiation only can Minimize.
I thought about this and I decided to implement in a similar way. Cuz I wanted to Maximize the chance of our discriminator guessing right for real image while Minimize the chance of our discriminator guessing wrong for fake images, and I wanted the sum of those values to balance out. However, I am not 100 % sure of this part as of yet, and will revisit this matter soon.
Forward Feed / Partial Back Propagation of Generator in GAN

The Back Propagation process for generator network in GAN is bit complicated.
- Blue Box — Generated Fake Data from the Generator Network
- Green Box (Left Corner) — Discriminator Takes the Generated (Blue Box) Input and perform Forward Feed process
- Orange Box — Cost Function for Generator Network (Again we want to Maximize the chance of producing a Realistic Data)
- Green Box (Right Corner) — Back Propagation Process for Generator Network, but we have to pass Gradient all the way Discriminator Network.
Below is the screen shot of implemented code.
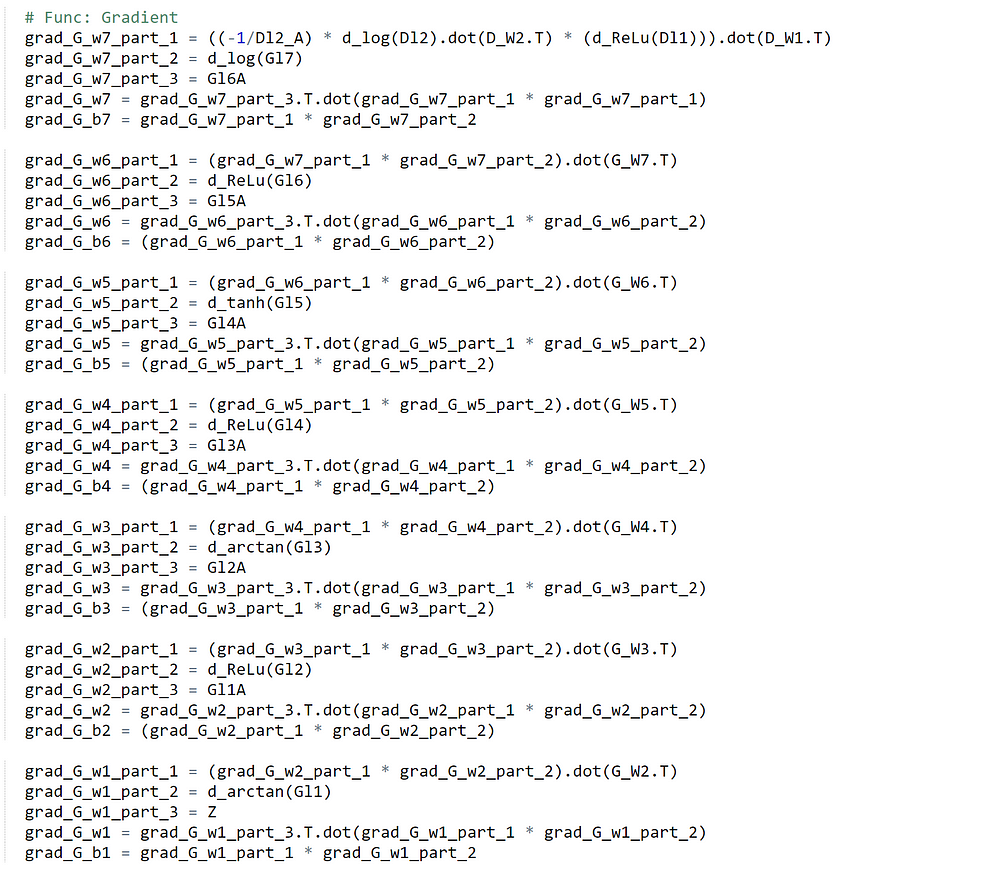
Standard Back propagation, nothing too special.
Training Results: Failed Attempts
I quickly realized that training GAN is extremely hard, even with Adam Optimizer, the network just didn’t seem to converge well. So, I will first present you all of the failed attempts and it’s network architectures.
1. Generator, 2 Layers: 200, 560 Hidden Neurons, Input Vector Size 100

2. Generator, tanh() Activation, 2 Layers: 245, 960 Hidden Neurons, IVS 100

3. Generator, 3 Layers: 326, 356,412 Hidden Neurons, Input Vector Size 326

4. Generator, 2 Layers: 420, 640 Hidden Neurons, Input Vector Size 350

5. Generator, 2 Layers: 660, 780 Hidden Neurons, Input Vector Size 600
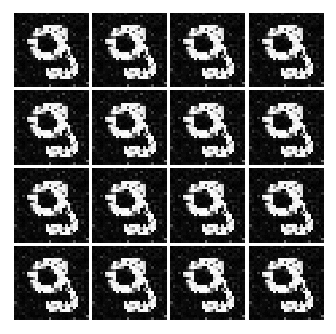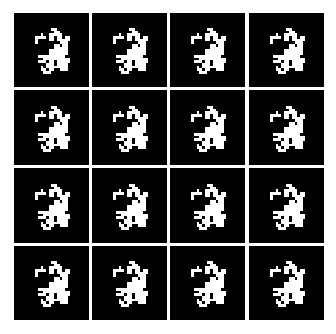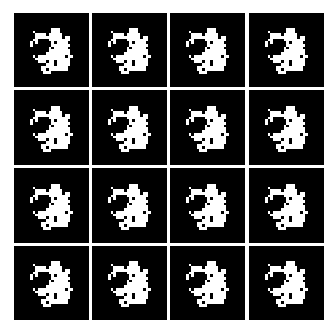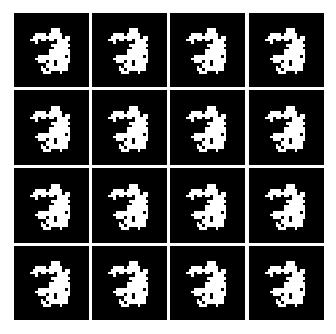
6. Generator, 2 Layers: 320, 480 Hidden Neurons, Input Vector Size 200

So as seen above, all of them seems to learn something, but not really LOL. However, I was able to use one neat trick to generate an image that kinda look like numbers.
Extreme Step Wise Gradient Decay

Above is a gif, I know the difference is subtle but trust me I ain’t Rick Rollying you. The trick is extremely simple and easy to implement. We first set the learning rate high rate for the first training, and after the first training we set the decay the learning rate by factor of 0.01. And for unknown reason (I want to investigate further more into this), this seems to work.
But with a huge cost, I think we are converging to a ‘place’ where the network is only able to generate only certain kind of data. Meaning, from the uniform distribution of numbers between -1 and 1. The Generator will only generate image that ONLY looks like a 3 or a 2 etc... But the key point here is that the network is not able to generate different set of numbers. This is evidence by the fact that, well, all of the numbers represented in the image look like 3.
However, it is some what reasonable image that looks like a number. So lets see some more results.
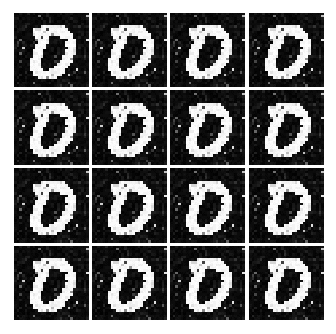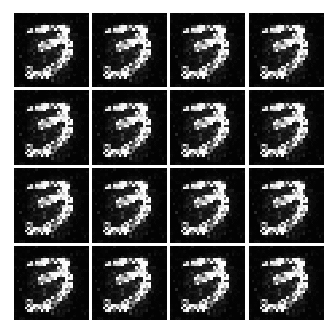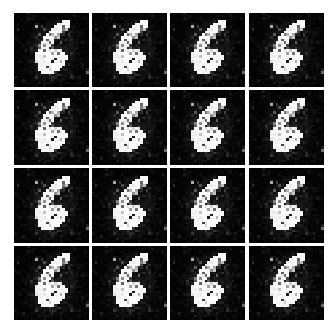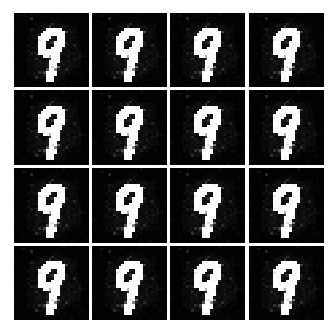
As seen above, as time goes on, the numbers become sharper. A good example is the generated image of 3 or 9.
Interactive Code
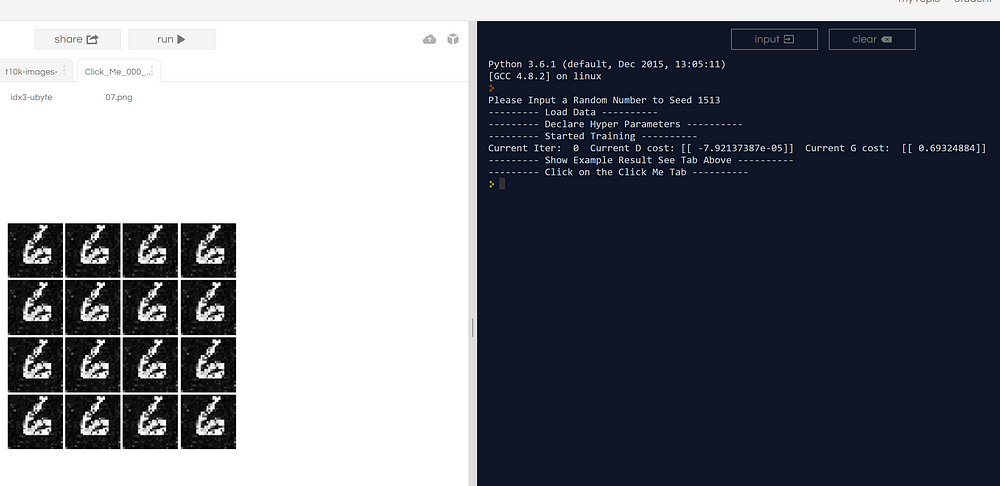
Update: I moved to Google Colab for Interactive codes! So you would need a google account to view the codes, also you can’t run read only scripts in Google Colab so make a copy on your play ground. Finally, I will never ask for permission to access your files on Google Drive, just FYI. Happy Coding!
Please click here to access the interactive code, online.

When running the code, make sure you are on the ‘main.py’ tap, as seen above in the Green Box. The program will ask you a random number for seeding, as seen in the Blue Box. After it will generate one image, to view that image please click on the click me tab above, Red Box.
Final Words
Training GAN to even partially work is a huge chunk of work, I want to investigate on more effective way of training of GAN’s. One last thing, shout out to @replit, these guys are amazing!
If any errors are found, please email me at jae.duk.seo@gmail.com.
Meanwhile follow me on my twitter here, and visit my website, or my Youtube channel for more content. I also did comparison of Decoupled Neural Network here if you are interested.
References
- Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2014). Generative adversarial nets. In Advances in neural information processing systems (pp. 2672–2680).
- Free Online Animated GIF Maker — Make GIF Images Easily. (n.d.). Retrieved January 31, 2018, from http://gifmaker.me/
- Generative Adversarial Nets in TensorFlow. (n.d.). Retrieved January 31, 2018, from https://wiseodd.github.io/techblog/2016/09/17/gan-tensorflow/
- J. (n.d.). Jrios6/Adam-vs-SGD-Numpy. Retrieved January 31, 2018, from https://github.com/jrios6/Adam-vs-SGD-Numpy/blob/master/Adam%20vs%20SGD%20-%20On%20Kaggles%20Titanic%20Dataset.ipynb
- Ruder, S. (2018, January 19). An overview of gradient descent optimization algorithms. Retrieved January 31, 2018, from http://ruder.io/optimizing-gradient-descent/index.html#adam
- E. (1970, January 01). Eric Jang. Retrieved January 31, 2018, from https://blog.evjang.com/2016/06/generative-adversarial-nets-in.html
Bio: Jae Duk Seo is a fourth year computer scientist at Ryerson University.
Original. Reposted with permission.
Related:
- Inside the Mind of a Neural Network with Interactive Code in Tensorflow
- Building Convolutional Neural Network using NumPy from Scratch
- How I Used CNNs and Tensorflow and Lost a Silver Medal in Kaggle Challenge