Building a Machine Learning Model through Trial and Error
A step-by-step guide that includes suggestions on how to preprocess data and deriving features from this. This article also contains links to help you explore additional resources about machine learning methods and other examples.
Sponsored Post.
By Seth DeLand, Product Marketing Manager, Data Analytics, MathWorks
The machine learning roadmap is filled with trial and error. Engineers and scientists, who are novices at the concept, will constantly tweak and alter their algorithms and models. During this process, challenges will arise, especially with handling data and determining the right model.
When building a machine learning model, it’s important to know that real-world data is imperfect, different types of data require different approaches and tools, and there will always be tradeoffs when determining the right model.
The following systematic workflow walk through describes how to develop a trained model for a cell phone health monitoring app that tracks user activity throughout the day. The input consists of sensor data from the phone. Output will be activities performed: walking, standing, sitting, running, or dancing. Because the goal is classification, this example will involve supervised learning.
Access and load the data
The user will sit down holding the phone, log the sensor data, and store it in a text file labeled “sitting.” Then, they should stand up holding the phone, log the sensor, and store it in a text file labeled “standing.” Repeat for running, walking and dancing.
Preprocess the data
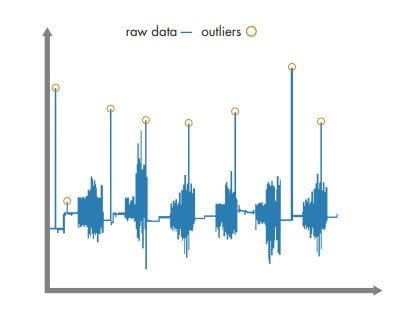
Because machine learning algorithms are not able to differentiate noise from valuable information, data must be cleaned before it is used for training. Data can be preprocessed with a data analysis tool, like MATLAB. To clean the data, users can import and plot the data, and remove outliers. In this example, an outlier can result from unintentionally moving the phone while loading data. Users must also check for missing data, which can be replaced by approximations or comparable data from another sample.
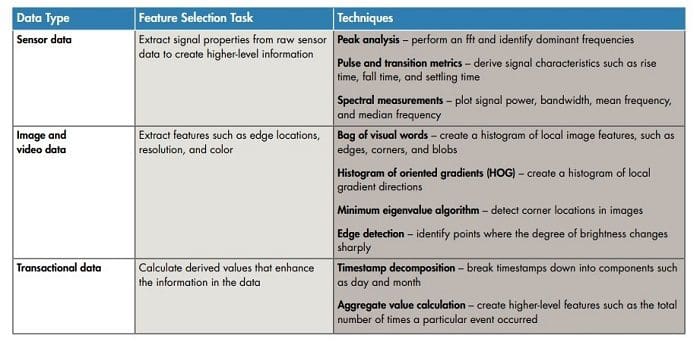
Derive features using the preprocessed data
Raw data must be turned into information a machine learning algorithm can use. To do this, users must derive features that categorize the content of the phone data.
In this example, engineers and scientists must distinguish features to help the algorithm classify between walking (low frequency) and running (high frequency).
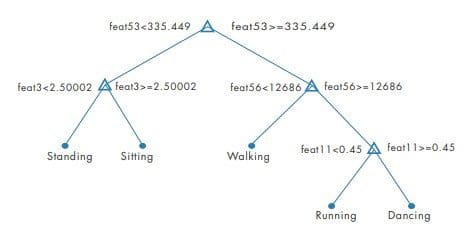
Start with a simple decision tree.
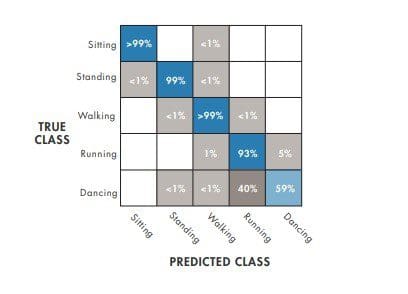
A K-nearest neighbors (KNN) algorithm stores all the training data, compares new points to the training data, and returns the most frequent class of the “K” nearest points. This shows higher accuracy.
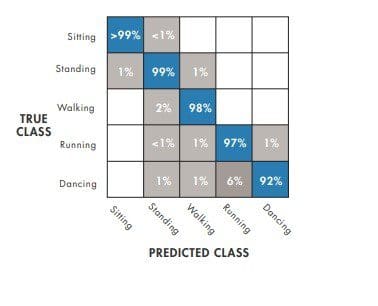
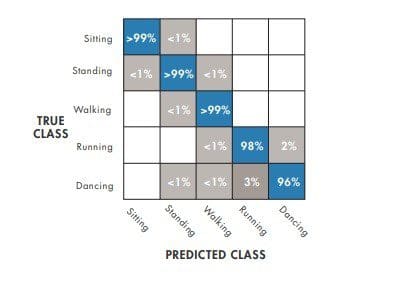
Improve the model
If the model can’t reliably classify between dancing and running, it needs to be improved. Models can be improved by either making them more complex (to better fit the data) or more simple (to reduce the chance of overfitting).
To simplify the model, the number of features can be reduced by the following means: a correlation matrix, so features not highly correlated can be removed; a principal component analysis (PCA) that eliminates redundancy; or a sequential feature reduction that reduces features repeatedly until there is no improvement. To make the model more complex, engineers and scientists can merge multiple simpler models into a larger model or add more data sources.
Once trained and adjusted, the model can be validated with the “holdout” dataset set aside during preprocessing. If the model can reliably classify activities, then it is ready for the phone application.
Engineers and scientists training machine learning models for the first time will encounter challenges but should realize that trial and error is part of the process. The workflow outlined above provides a road map to building machine learning models that can also be used in varied applications like predictive maintenance, natural language processing, and autonomous driving.
Explore these other resources to learn more about machine learning methods and examples.
- Supervised Learning Workflow and Algorithms: Learn the workflow and steps in the supervised learning process.
- MATLAB Machine Learning Examples: Get started with machine learning by exploring examples, articles, and tutorials.
- Machine Learning with MATLAB: Download this ebook for a step-by-step guide providing machine learning basics along with advanced techniques and algorithms.