 Intro to Data Science for Managers
Intro to Data Science for Managers
 Intro to Data Science for Managers
Intro to Data Science for ManagersThis mindmap contains a condensed introduction to the key data science concepts and techniques that have revolutionized the business landscape and became essential for making beneficial data-driven decisions

Data science has become an integral part of many modern projects and businesses, with an increasing number of decisions now based on data analysis. The data science industry is experiencing an acute shortage of talents, not only of data scientists but also of managers, having some understanding of analytics and data science. As a manager, you can ultimately become the company's expert in data usage, creating opportunities for the evolution of your organization. Whether you are working with a team of data scientists, as a part of a data-driven business, or you are interested in implementing data science solutions — you shall have some data knowledge and understand its organizational capabilities.
Data science is incredibly broad and complex discipline, an interception of computer science, math and statistics, and a domain of knowledge requiring the understanding the source of data: medical, financial, web, and other domains.
The mindmap below contains a condensed introduction to the key data science concepts and techniques that have revolutionized the business landscape and became essential for making beneficial data-driven decisions. We are confident that it will be useful and informative for both the data science managers and for those facing this rapidly developing field as a client or user.
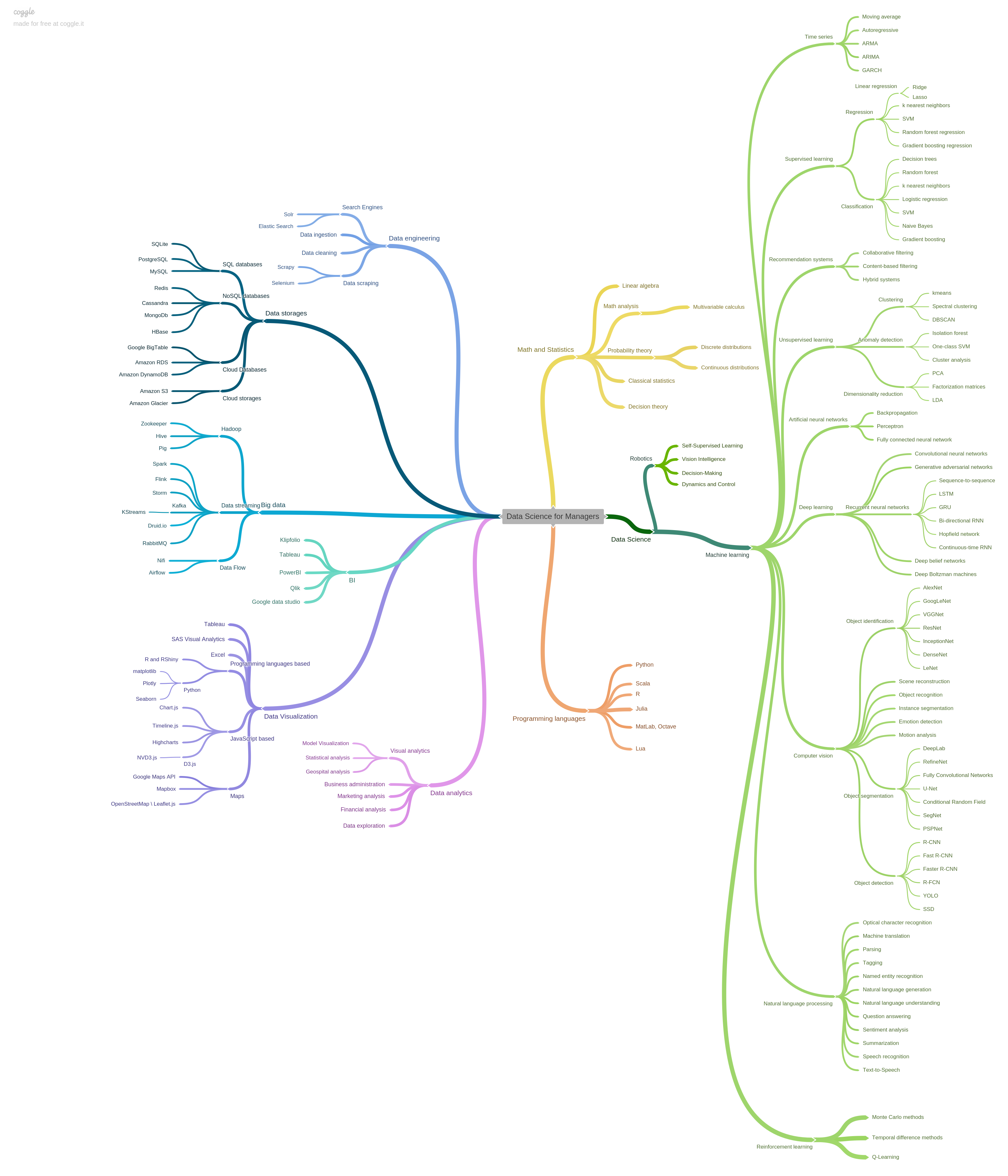
The original mindmap can be found here.
Let’s take a closer look. The branches of our mindmap are grouped in a particular way. In the middle, there are two sections of asic knowledge on which any data science projects are built, namely mathematics and statistics and programming languages.
As we are talking about the science that is based on the data, it's evident that one of the fundamental knowledges here is math. Each algorithm in machine learning is based on mathematical grounds, and it is necessary to understand the basics of linear algebra, probability theory, and classical statistics.
Moving forward, all those huge calculations and implementation of different algorithms and solutions of data science tasks are realized exactly using various programming languages. As a manager, you do not need to know how to craft an algorithm or understand all the peculiarities of each language, but you must comprehend, which languages can implement specific tasks, how well they fit, and their pros and cons.
The entire right-hand side of the mindmap is directly related to the data science sphere. It is a broad concept, which combines three very large areas: robotics, machine learning, and reinforcement learning with a further branching of these areas. The main task of the manager at this point is to know what are the general algorithms of machine learning, in which industries they can be applied, and which use cases can they solve.
The left-hand side of the mindmap covers the supporting areas of data science: data storages, data engineering, big data, data analysis, visualization, and BI (Business Intelligence). They help to clean, process, transform and represent data and analyze it from different aspects, in such a way complementing different machine learning tasks.
Data science relies on creating and consuming data, which must be available when and where it is needed. This is the exact purpose of data storages. Data storage is a technology of archiving data in a convenient form. You should be aware of the fundamental difference between SQL and NoSQL databases, why you need the cloud services, what services provide a more convenient and understandable interface, what exactly do you need for particular tasks and other details.
The main purpose of data engineering is to transform data into an easy and useful format for analysis. Any data manipulation requires some pre-processing of data, and often the qualitative transformation and processing of data play a key role in the success of a project. Roughly, the main operations that compose data engineering are data scraping, data ingestion, and data cleaning.
Moreover, working on a data science task, you often have to deal with large and voluminous datasets that traditional data-processing tools and instruments cannot handle. This is where big data solutions come in. In addition to processing large volumes of data, big data has some other specific characteristics. Namely, it’s the ability to work with data that quickly arrives in constantly increasing volumes and abilities to work with structured and unstructured data in various aspects in parallel.
Data analytics is a process of obtaining information about the datasets and finding the particular insights. It is aimed at searching various dependencies between input parameters. Data analytics is an integral part of your company’s marketing, finance, business administration, etc.
Finally, the data requires understanding, interpreting, and explaining. Everyone who works with data acknowledges the importance of the BI and visualization tools for showing what is hidden in the code and making it visible. Every person perceives visual information much better and faster, that’s why it is an integral part of every analysis as well as data science project. With benefits for both clients and developers, it should definitely be in the arsenal of a data manager.
Conclusion
Of course, every branch can be further expanded and divided, and this is not an ultimate truth, but rather our attempt to show our vision which reflects the current state of data science development.
There is no way to highlight the single most important branch for the manager as data science is a complex and vast field. But now you will hopefully have a general understanding of the main components of modern data science field and how they are interrelated, and this could be a good start to expand your knowledge in this area.
If you have some additional thoughts and ideas regarding this topic, please share them in the comment section below.
Also, if there are some specific areas, which you would like to get covered in more details, please let us know.
ActiveWizards is a team of data scientists and engineers, focused exclusively on data projects (big data, data science, machine learning, data visualizations). Areas of core expertise include data science (research, machine learning algorithms, visualizations and engineering), data visualizations ( d3.js, Tableau and other), big data engineering (Hadoop, Spark, Kafka, Cassandra, HBase, MongoDB and other), and data intensive web applications development (RESTful APIs, Flask, Django, Meteor).
Original. Reposted with permission.
Related:
- Top 20 Python Libraries for Data Science in 2018
- Top 20 R Libraries for Data Science in 2018
- Comparison of Top 6 Python NLP Libraries