Approaches to Text Summarization: An Overview
This article will present the main approaches to text summarization currently employed, as well as discuss some of their characteristics.

Image By Editor
The bona fide semantic understanding of human language text, exhibited by its effective summarization, may well be the holy grail of natural language processing (NLP). That statement isn't as hyperbolic as it sounds: as true human language understanding definitely is the holy grail of NLP, and genuine effective summarization of said human language would necessarily entail true understanding, transitivity would back me up on this.
Unfortunately — or perhaps not, depending on your outlook — honest to goodness "understanding" of human language is not something we can currently count on for text summarization. However, the show must go on, and there currently exist an array of actual techniques for summarizing text, some of which stretch back decades. These techniques take different approaches to reach the same goal, and can be classified into a fairly narrow set of categories for pursuing their shared goal.
This article will present the main approaches to text summarization currently employed, as well as discuss some of their characteristics.
Automated Text Summarization Techniques
To be clear, when we say "automated text summarization," we are talking about employing machines to perform the summarization of a document or document using some form of heuristics or statistical methods. A summary in this case is a shortened piece of text which accurately captures and conveys the most important and relevant information contained in the document or documents we want to be summarized. As hinted at above, there are a number of these different tried and truly automated text summarization techniques that are currently in use.
There are a few ways of going about classifying automated text summarization techniques, as can be seen in Figure 1. This article will explore these techniques from the point of view of summarization output type. In this regard, there are 2 categories of techniques: extractive and abstraction.
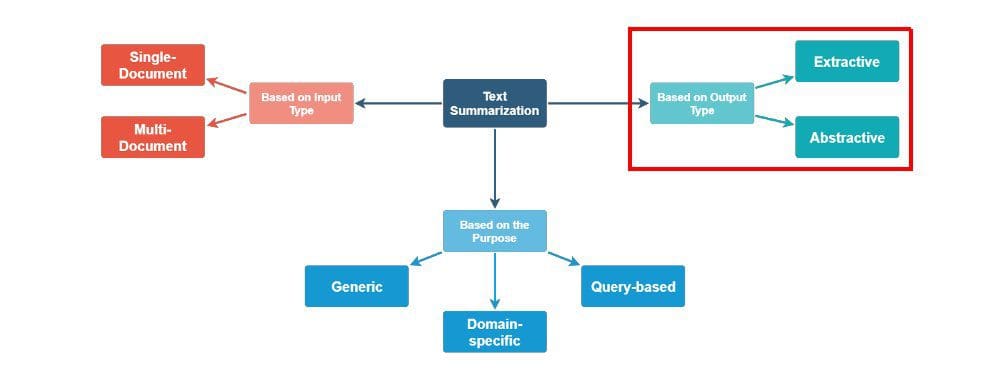
Figure 1. Automated text summarization approaches (source: Kushal Chauhan, Jutana, modified).
Extractive text summarization methods function by identifying the important sentences or excerpts from the text and reproducing them verbatim as part of the summary. No new text is generated; only existing text is used in the summarization process.
Abstractive text summarization methods employ more powerful natural language processing techniques to interpret text and generate new summary text, as opposed to selecting the most representative existing excerpts to perform the summarization.
While both are valid approaches to text summarization, it should not be difficult to convince you that abstractive techniques are far more difficult to implement. In fact, the majority of summarization processes today are extraction-based. This doesn't mean that abstractive methods should be discounted or ignored; on the contrary, research into their implementation — and true semantic understanding of human language in general — is a worthy pursuit, and much work is needed before we can confidently say that we have gained a true foothold in this endeavor.
For this reason, the rest of this article will focus on the specifics of extractive text summarization, and its differing implementation techniques.
Extractive Summarization
Extractive summarization techniques vary, yet they all share the same basic tasks:
- Construct an intermediate representation of the input text (text to be summarized)
- Score the sentences based on the constructed intermediate representation
- Select a summary consisting of the top k most important sentences
Tasks 2 and 3 are straightforward enough; in sentence scoring, we want to determine how well each sentence relays important aspects of the text being summarized, while sentence selection is performed using some specific optimization approach. Algorithms for each of these 2 steps can vary, but they are conceptually quite simple: assign a score to each sentence using some metric, and then select from the best-scored sentences via some well-defined sentence selection method.
The first task, intermediate representation, could use further elaboration.
Intermediate Representation
Some sense needs to be made of natural language prior to its sentence scoring and selection, and creating some intermediate representation of each sentence serves this purpose. The 2 major categories of intermediate representation, topic representation and indicator representation, are briefly defined below, as are their sub-categories.
Topic Representation - transformation of the text with a focus on text topic identification; major sub-categories of this approach are:
- frequency-driven approaches
- topic word approaches
- latent semantic analysis (LSA)
- Bayesian topic models — latent Dirichlet allocation (LDA), for example
The 2 most popular word frequency approaches are word probability and TF-IDF.
In topic words approaches, there are 2 ways to compute a sentence's importance: by the number of topic signatures it contains (the number of topics the sentence discusses), or by the proportion of topics the sentence contains versus the number of topics contained in the text. As such, the first of these tends to reward longer sentences, while the second measures topic word density.
Explanations of latent semantic analysis and Bayesian topic model approaches, such as LDA, are beyond the scope of this article, but can be read about in the links above.

Figure 2. Constructing bag of words feature vectors (source: Dipanjan Sarkar).
Indicator Representation - transformation of each sentence in the text into a list of features of importance; possible features include:
- sentence length
- sentence position
- whether sentence contains a particular word (see Figure 2 for an example of such a feature extraction method, bag of words)
- whether sentence contains a particular phrase
Using a set of features to represent and rank the text data can be performed using one of 2 overarching indicator representation methods: graph methods and machine learning methods.
Using graph representations:
- we find that sub-graphs end up representing topics covered in the text
- we are able to isolate important sentences in the text, given that these are the ones which would be connected to a greater number of other sentences (if you consider sentences as vertices and sentence similarity represented by edges)
- we do not need to consider language-specific processing, and the same methods can be applied to a variety of languages
- we can often find that the semantic information gained via graph-exposed sentence similarity enhances summarization performance beyond more simple frequency approaches
With machine learning representations:
- the summarization problem is modeled as a classification problem
- we require labeled training data to build a classifier to classify sentences as summary or non-summary sentences
- to combat the labeled data conundrum, alternatives such as semi-supervised learning show promise
- we find that certain methods which assume dependency between sentences often outperform other techniques
Text summarization is an exciting sub-discipline of natural language processing. While a variety of approaches to extractive summarization are in use and are being researched daily, an understanding of the basis of the concepts above should allow you to have some understanding of how any of these operate, at least at a 30,000 foot level. You should also be able to pick up recent papers or read recent implementation blog posts with some confidence you have the basic level of understanding necessary for such an undertaking.
Much of this information owes a debt of gratitude to the paper, Text Summarization Techniques: A Brief Survey, by Mehdi Allahyari, Seyedamin Pouriyeh, Mehdi Assefi, Saeid Safaei, Elizabeth D. Trippe, Juan B. Gutierrez, and Krys Kochut.
References & further reading:
- Text Summarization Techniques: A Brief Survey, Mehdi Allahyari, Seyedamin Pouriyeh, Mehdi Assefi, Saeid Safaei, Elizabeth D. Trippe, Juan B. Gutierrez, Krys Kochut, 2017.
- Unsupervised Text Summarization using Sentence Embeddings, Kushal Chauhan, 2018.
Also, this article focused on extractive summarization, but you can find more about abstractive summarization in the following:
- Abstractive and Extractive Text Summarization using Document Context Vector and Recurrent Neural Networks, Chandra Khatri, Gyanit Singh, Nish Parikh, 2018.
- Neural Abstractive Text Summarization with Sequence-to-Sequence Models, Tian Shi, Yaser Keneshloo, Naren Ramakrishnan, Chandan K. Reddy, 2018.
Matthew Mayo (@mattmayo13) is a Data Scientist and the Editor-in-Chief of KDnuggets, the seminal online Data Science and Machine Learning resource. His interests lie in natural language processing, algorithm design and optimization, unsupervised learning, neural networks, and automated approaches to machine learning. Matthew holds a Master's degree in computer science and a graduate diploma in data mining. He can be reached at editor1 at kdnuggets[dot]com.