Building AI to Build AI: The Project That Won the NeurIPS AutoML Challenge
This is an overview of designing a computer program capable of developing predictive models without any manual intervention that are trained & evaluated in a lifelong machine learning setting in NeurIPS 2018 AutoML3 Challenge.
By Flytxt NeurIPS AutoML3 Challenge Team
Lifelong machine learning AutoML challenge: AI that creates AI
A challenging problem, tough competition, collaborative learning, we could experience all that and more in the recent AutoML3 challenge, held as a part of NeurIPS 2018 conference – one of the highest ranked conferences in the field of AI & ML. Around 9000 brightest minds from across AI/ML industry and academia attended the event this year. You can read some interesting facts about the conference here.
As much glad we are to win this challenge, as we are by participating in it. Our journey throughout the challenge, right from understanding the problem statement and its uniqueness, to the initial explorations, ideations, experimentations, taking up individual responsibilities along with team-coordination, taking sensible decisions at each step of the challenge, to finally coming out as the winner, was really an enriching feeling in itself.
NeurIPS 2018 had a competition track, wherein challenging and impactful AI/ML problems were posed. AutoML3 challenge was one among the 8 challenging problems posed this year. More than 300 teams from industry and academia participated in the AutoML challenge this year. Our joint team ‘autodidact.ai’, consisting of data scientists and researchers from Flytxt, IIT Delhi (Multimedia Lab) and CSIR-CEERI won the challenge. Through this blog, we have tried to capture the excitement and fulfilling experience we had in participating and winning this prestigious challenge.
AutoML Challenge: AI to build AI
Several real-world machine learning applications extensively rely on the expertise of data scientists and domain knowledge to build effective solutions.
However, due to the limited availability of experienced data scientists and limited machine learning expertise of developers, it becomes imperative to build an AI that in turn can build AI solutions for complex problems.
AutoML is an emerging AI discipline which attempts to automate the end-to-end process of applying machine learning to real-world problems. In several applications, data arrives continuously (online advertising, telcos, banking, climate modeling etc.), causing offline predictive models built and maintained manually to quickly become obsolete. This presents continuous learning, or Lifelong Machine Learning challenge for an AutoML system, and was the central theme of the NeurIPS 2018 AutoML challenge.
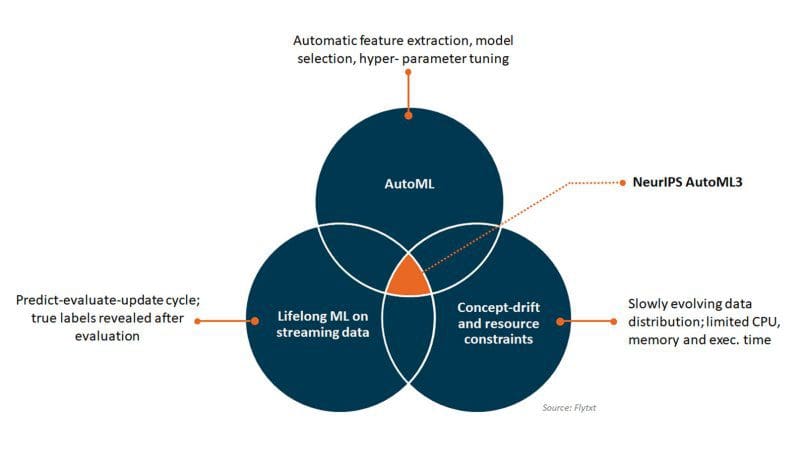
NeurIPS AutoML challenge 2018 was the 3rd such edition in the history of AutoML challenges conducted till now. In this year's challenge, participants were asked to design a computer program that could develop a predictive model autonomously (without any human intervention), using limited resources and time to conduct model training and evaluation in a lifelong machine learning environment. Unlike the previous editions of AutoML challenges, this edition presented several unique challenges as described in fig 1.

The motivation behind this challenge
Building an end-to-end machine learning (ML) pipeline for any ML problem generally requires considerable manual/human intervention, which is mostly tedious and repetitive in nature. And this often requires domain/ML experts to figure out an optimal model pipeline, which includes appropriate preprocessing methods, learning algorithms and optimal hyperparameters of the selected learning algorithm (with respect to the dataset at hand) out of several candidate choices. Moreover, in the real world, data often arrives as streams or batches, where data distribution changes/evolves over time (known as the concept drift phenomenon) making modeling and maintaining of models really challenging. Doing all these at scale even makes it more challenging. Hence, there is a need to develop autonomous systems which can not only recommend an optimal model pipeline pertaining to a specific ML problem and dataset but can also automatically adapt to concept drift without manual intervention, thereby maintaining the entire life cycle of the model. The quest for these needs has sparked interest in an innovative, yet challenging area of research, which is known as Automatic Machine Learning (AutoML).
Existing AutoML systems and how AutoGBT is unique?
Existing state-of-the-art AutoML systems include PoSH Auto-sklearn which operates based on an automatically pre-selected portfolio of ML pipelines, automatic ensemble building and a Bayesian optimization of the selected ML pipeline with successive halving. However, it doesn’t handle concept-drift and non-numeric features with a large number of unique values following specialized statistical distributions. Moreover, it is not designed for very large data volume and lifelong learning setting. Another AutoML system, LML extension for Auto-sklearn extends Auto-sklearn by adding explicit drift detection mechanism using Fast Hoeffding Drift Detection Method (FHDDM). However, similar to POSH Auto-sklearn, it also fails at handling high cardinality non-numeric features and is not designed for very large data volume. Also, the performance of this system depends on the type of drift encountered.
Our AutoML framework, AutoGBT, which stands for ‘Automatically Optimized Gradient Boosting Trees’, overcome such limitations and is inspired by several existing AutoML architectures. A high-level architecture of AutoGBT is depicted in Fig 2.
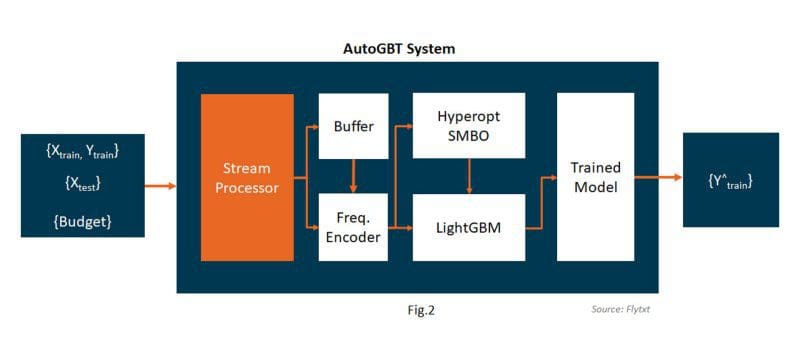
High-Level summary of AutoGBT Framework
AutoGBT essentially involves an adaptive self-optimized end-to-end machine learning pipeline consisting of a stream processor and a frequency encoder to exploit semantic similarity of categorical and multi-valued feature values across batches. This allows to counter slow concept-drift through adaptation, without explicit drift detection. It also includes normalization of DateTime features along with generation of new features from existing DateTime columns to augment the feature space. Our feature space transformation technique is as depicted in Fig 3.
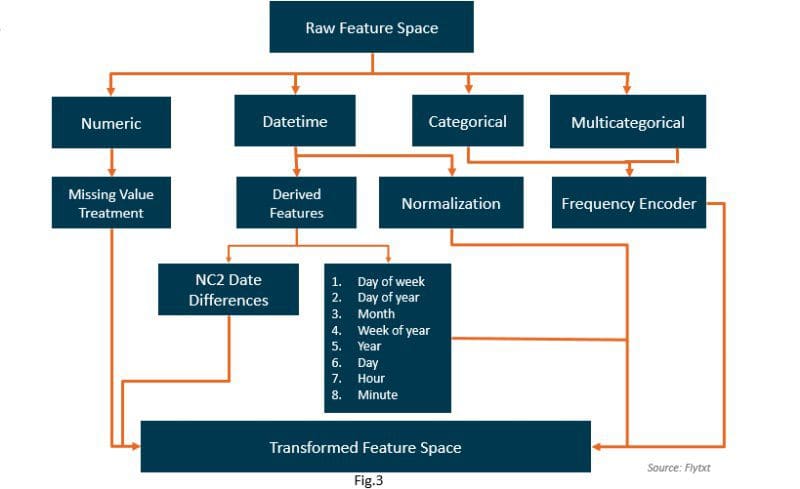
We use a multi-level sampling strategy to overcome dataset skewness for more meaningful training and to scale our model to large datasets. We use a Gradient Boosting framework utilizing tree-based learning algorithms for model training, and a Sequential model-based optimization (SMBO, a strategy based on Bayesian optimization) technique for automatic hyper-parameter tuning. Our AutoGBT framework also involves intelligent heuristic checks to automatically adapt to the budget constraints.
Results
Our joint team named autodidact.ai from Flytxt, IIT Delhi (Multimedia Lab) and CSIR-CEERI secured the first position in the NIPS 2018 AutoML challenge. Team members include Jobin Wilson, Amit Meher, Bivin Vinodkumar Bindu, Manoj Sharma, Vishakha Pareek, Prof. Santanu Chaudhury and Prof. Brejesh Lall.
The leaderboard for the Feedback phase and AutoML can be seen here and here. More details about the contest and winning teams are available here and here.
What worked for us in this challenge?
We observed that our simple adaptive model pipeline having automatic hyperparameter tuning using SMBO performed well in the AutoML phase (got almost consistent ranks across all 5 datasets), even though the model portfolio was limited. We also observed that specialized preprocessing pipeline was very effective in handling a large number of categorical/multi-valued feature values following a power law distribution without imposing scalability issues, especially for large datasets. Our save-retrain strategy & frequency encoding in a streaming setting performed reasonably well to counter slow concept-drift, even in the absence of explicit drift detection. Extensive and rigorous testing of our end-to-end pipeline on multiple open datasets suggested that it generalizes reasonably well to unseen datasets. Also, intelligent heuristic checks (for example: if only a small fraction of the allocated time budget is remaining, then skip the retraining part and reuse the latest trained model for predictions on subsequent data batches) proved to be helpful. Overall, we believe that a combination of scientific principles and clever engineering helped us to withstand the challenging test in blind phase.
The competition is over, but we are excited for a re-match soon in conjunction with PAKDD 2019 and IJCNN 2019!
AutoGBT is now open sourced and can be assessed from this GitHub repository.
Flytxt is a market leading supplier of analytics and AI-based customer value management solutions.
Related:
- Automated Machine Learning vs Automated Data Science
- Keras Hyperparameter Tuning in Google Colab Using Hyperas
- Implementing Automated Machine Learning Systems with Open Source Tools