Mastering Fast Gradient Boosting on Google Colaboratory with free GPU
CatBoost is a fast implementation of GBDT with GPU support out-of-the-box. Google Colaboratory is a very useful tool with free GPU support.
By Anna Veronika Dorogush, CatBoost Team Lead

NVIDIA K80 GPU, https://www.nvidia.com/ru-ru/data-center/tesla-k80/
Gradient Boosting on Decision Trees (GBDT) is a state-of-the-art Machine Learning tool for working with heterogeneous or structured data. When working with data, the ideal algorithm depends highly on the type of data. For homogeneous data, like images, sound or text, the best solution is neural networks. And for structured data, for example for credit scoring, recommendations or any other tabled data the best solution is GBDT.
For this reason, a large number of winning solutions for Kaggle competitions are based on GBDT. GBDT is also heavily used in the production of different recommendation systems, in search engines, and in many financial structures.
Many people think that GBDT cannot be efficiently accelerated by a GPU, but this is actually not the case. In this post, I explain how a GPU can be used to speed up GBDT.
For the GBDT implementation, I’ll use CatBoost, a library well known for its categorical features support and efficient GPU implementation. It not only works with categorical data, but with any data, and in many cases, it outperforms other GBDT libraries.
The library was developed for production needs at the leading Russian tech company, Yandex, and was later open sourced under the Apache 2 license about a year and a half ago.

The test environment for my demonstration will be Google Colaboratory. This is a research tool for machine learning with free access to GPU runtime. It’s a Jupyter notebook environment that requires no setup to use.
Google Colaboratory offers pretty old GPUs for free - a Tesla K80 GPU with about 11GB memory. With newer GPUs, the speed increase will be much more significant. But even with this old GPU, you will see an impressive speed difference. If we are talking about CPU, it’s 2x Intel Xeon E5-2600v3 per instance.
Below you will find several simple steps to set up CatBoost inside Colab, download a dataset, train the model on a CPU and a GPU, and compare execution times.
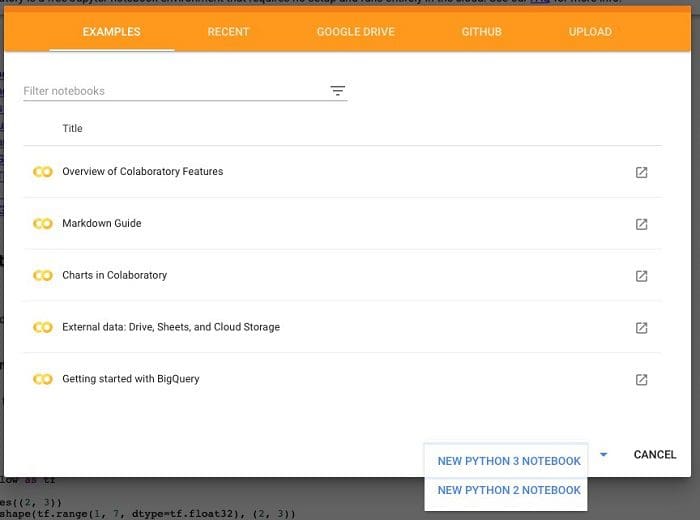
Create notebook
Navigate to Colaboratory and create a new Python 3 notebook.
Set GPU as hardware accelerator
There are two simple steps to select GPU as the hardware accelerator:
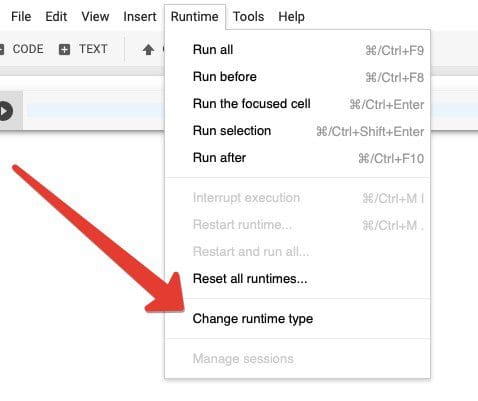
Step 1. Navigate to the 'Runtime' menu and select 'Change runtime type'
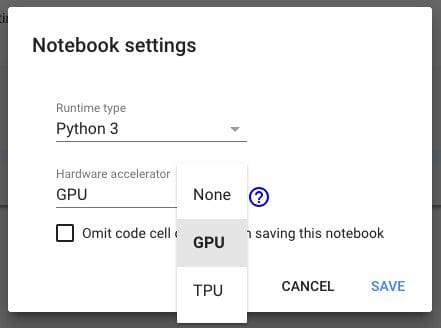
Step 2. Select “GPU” as the hardware accelerator.
Importing CatBoost
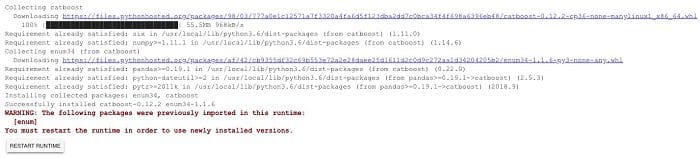
The next step is to import CatBoost inside the environment. Colaboratory has built in libraries installed and most libraries can be installed quickly with a simple !pip install command.
Please ignore the warning message about already imported enum package. Furthermore take note that you need to re-import the library every time you start a new session of Colab.
!pip install catboost
The CatBoost library that you install from pypi has GPU support, so you can use it straight away. You only need to have a NVIDIA driver installed on your machine, and everything else will work out-of-the-box. This is also true for Windows, making it easier for Windows users who want to train their models on GPUs.
Download and prepare dataset
It’s time to code! Once we’ve configured our environment, the next step is to download and prepare the dataset. For GPU training, the bigger the dataset is, the bigger the speedup will be. It doesn’t make a lot of sense to use GPU training for objects of one thousand or less, but starting from around 10,000 you will get a good acceleration.
We require a large dataset to demonstrate the power of GPUs for GBDT tasks. We will use Epsilon, which has 500,000 documents and 2,000 features, and is included in catboost.datasets.
The code below does this task in approximately 10-15 minutes. Please be patient.
Training on CPU
To the myth about GBDT not showing large speed gains on GPU, I would like to compare GBDT training time on CPU and GPU. Let’s start with CPU. The code below creates a model, trains it, and measures the execution time of the training. It uses default parameters as they provide a fairly good baseline in many cases.
We will first train all our models for 100 iterations (because it takes a really long time to train it on CPUs).
After you run this code, you can change it to a default of 1000 or more iterations to get better quality results.
CatBoost will require around 15 minutes to train on CPUs for 100 iterations.
you want to show there can be feed speed ups, correct?
if feed = training, yes.
Time to fit model on CPU: 862 sec
Training on GPUs
All previous code execution has been done on a CPU. It's time to use a GPU now!
To enable the GPU training you need to use task_type='GPU' parameter.
Let’s rerun the experiment on GPU and see what will be the resulting time.
If Colab will show you the warning “GPU memory usage is close to the limit”, just press “Ignore”.

Time to fit model on GPU: 195 sec
GPU speedup over CPU: 4x
As you can see, the GPU is 4x times faster than the CPU. It takes just 3-4 minutes vs 14-15 with a CPU to fit the model. Moreover, the learning process is complete in just 30 seconds vs 12 minutes.
When we train 100 iterations, the bottleneck is preprocessing and not the training itself. But for thousands of iterations that are necessary to get the best quality on huge datasets, this bottleneck will be invisible. You can try training for 5,000 iterations on a CPU and a GPU and compare once again.
Code
All the code above you can find as a tutorial for Google Colaboratory at CatBoost repository.
Alternative GBDT libraries
To be fair there are at least two more popular open source GBDT libraries:
Both are available as pre-installed libraries on Colaboratory. Let’s train both of them on CPU / GPU and compare times. Spoiler: We had no luck at receiving results from them. Details are below.
XGBoost
For the start let’s try the CPU version of XGBoost. Need to stress that training parameters is the same as for CatBoost library.
The code is quite simple, but once we’ve run it with Epsilon dataset Colaboratory session has crashed.

Unfortunately the same error occurs with the GPU version. Kernel dies after you start the simple code above.
LightGBM
CPU version of LightGBM results in the same error message “Your session crashed after using all available RAM.” error.
Colaboratory pre-installed version of LightGBM doesn’t contain GPU out of the box. And the installation guide for GPU version unfortunately doesn’t work. See details below.
!pip install -U lightgbm --install-option=--gpu

It’s a pity, but we couldn’t compare CPU vs GPU execution times for other libraries, except CatBoost’s. Possibly it’ll work with smaller dataset.
Summary
- GBDT algorithm works efficiently on a GPU.
- CatBoost is a fast implementation of GBDT with GPU support out-of-the-box.
- XGBoost and LightGBM don’t always work on Colaboratory with large datasets.
- Google Colaboratory is useful tool with free GPU support.
Further reading
[1] V. Ershov, CatBoost Enables Fast Gradient Boosting on Decision Trees Using GPUs, NVIDIA blog post
[2] R. Mitchell, Gradient Boosting, Decision Trees and XGBoost with CUDA, NVIDIA blog post
[4] CatBoost GitHub
Bio: Anna Veronika Dorogush is the Head of Machine Learning Systems at Yandex.
Resources:
- On-line and web-based: Analytics, Data Mining, Data Science, Machine Learning education
- Software for Analytics, Data Science, Data Mining, and Machine Learning
Related: