3 Big Problems with Big Data and How to Solve Them
We discuss some of the negatives of using big data, including false equivalences and bias, vulnerability to security breaches, protecting against unauthorized access and the lack of international standards for data privacy regulations.
By Elena Yakimova, a1qa
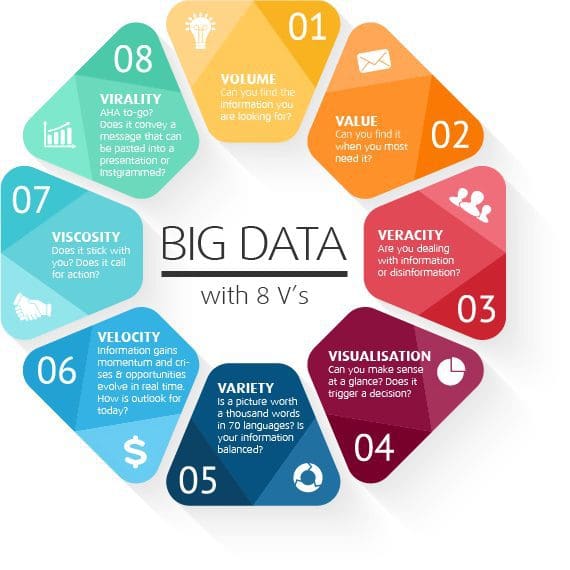
Big Data is unique in its size and scale. Add machine learning and Data Science, and this sheer volume will make it possible to reach unprecedented levels of accuracy and scope in predictions. When dealing with Big Data, there’s no need to worry about insufficient sample sizes or test group results—because the sample size is no less than everything. So it’s easy to think that with the famous 3 Vs (or 5, 6, 7 Vs) every single piece of possible input is at your service and disposal, meaning total control over complex, foolproof, endlessly scalable systems and services.
That’s the theory, at least.
However, when such vast and all-encompassing data amounts are processed automatically, numerous issues are bound to surface. Some of them are inherited from the ‘small data’ times; some are new and unique to the Big Data format. Here are three of the most prominent issues, along with the suggested solutions.
#1 False Equivalencies and Bias
With extremely large data quantities, the automated process of drawing conclusions (think black-box machine learning models) can be a bit of a gamble. What if in the process of learning, like in the often brought-up UCI study case, your AI chooses to make a shortcut and finds a link when there is none? Mistaking coincidence or causation for correlation and vice versa is a prominent problem with real-life consequences.
One of such consequences is customer dissatisfaction, when, for example, a recommendation engine fails to provide users with products they’re actually interested in. Or, in a far more alarming example, when “machine-learned” bias applies to mortgage rates calculations resulting in higher charges for minorities and the least protected groups. Credit history, court sentencing, job search, medical insurance—the more reliant on Big Data we become, the more challenging and crucial it is to avoid the false equivalencies and bias it can lead to.
How to Address It?
What are the ways to tackle this issue? According to Yael Eisenstat, ex-head of Facebook elections integrity operations, cognitive bias training is the key along with time, better Data Science and bigger, cleaner input data. Implementing algorithms and analytics without accounting for enough variables is what causes this issue. So ongoing critical evaluation, quality control and course correction (plus not over-relying on technology) go a long way in keeping Big Data on the right track here.
#2 Vulnerability to Security Breaches and Unauthorized Access
Aside from the “garbage in, garbage out” issues leading to biased and incomplete conclusions, another weakness (also, a priority) is Big Data security. A slew of big online leaks and wide-scale breaches in recent years (US Citizen Records leak and Yahoo! emails, to name a few) demonstrate that when dealing with Big Data, the usual methods of security protection aren’t enough.
Big Data and the algorithms that operate on it are very complex, and the more complex a system, the more potential weak spots that can be exploited. Here are a few examples:
-
- Distributed processing and data stores. There can be multitudes of potential entry points for fake data to be fed into the network, or for unauthorized access to the network from an unprotected system. Think about the often used Hadoop: it’s open-source and, at least originally, not boasting any significant security. NoSQL databases follow suit: security has to be provided additionally here, too.
- The process of data mining, which has to be protected from both potential external threats, and the possibility of sabotage from authorized insiders.
- Absent or insufficient security audits. The lack of oversight and/or resources for regular quality security assessments can be a common occurrence. Big data and the systems based on it prove a challenge in themselves, and adding sufficient security check-ups and standards can slide down the priority list.
How to Address It?
It’s still a long way to go before there are clear regulations on data collection and breach aftermath proceedings. Meanwhile, the experts from a1qa recommend organizations to relentlessly test all the software based on and working with Big Data.
Such testing should be aimed at finding weak spots, verifying if open-source software like Hadoop is breach-proof, employing attribute-based encryption and other measures of digital protection. Altogether, this should be par for the course on the way to ensure the cybersecurity of an enterprise’s Big Data.
#3 The Lack of International Standards for Data Privacy Regulations
One step away from potential attacks and breaches of security, the question of Big Data privacy—personal data privacy in particular—has never been more relevant. Since nobody reads terms of service, billions of users voluntarily provide app makers, device manufacturers, social networks, and various businesses around the globe with unending and uncontrolled streams of personal information. While extremely beneficial for marketing and research purposes, this also creates opportunity for intrusive, unethical use of Big Data—by those who collect and process it.
This is a serious concern for governments and general public alike. So for the past couple of years, new regulations and data privacy laws have been emerging around the globe. The trouble, however, is that these laws and initiatives are:
- Developed separately from each other, which leads to drastically different standards and requirements, depending on the region.
- Often somewhat vague or not finalized, with no established ways of enforcement and control (in their current state, at least).
- Generally in favor of rather heavy penalties and fines for those who fail to comply, which can become too heavy a burden for many businesses.
This leads to an avalanche of questions of the legal and ethical nature. Where should we draw the line between user data privacy and corporate use? Will the region-specific Data Regulations fracture and change the Internet as we know it? Will it then lead to the unprecedented dominance of region-locked content, software and hardware? Will smaller international businesses be able to keep up? These and other concerns are at the forefront of today’s Big Data legal discussions.
How to Address It?
At large, the emerging data privacy laws aim to provide a more ethical environment and much-needed transparency to user data processing. But it’s important to understand that they are a work in progress. There’s a lengthy path of trial and error ahead where businesses are concerned; and legislators are likely to miss the mark on their first few tries.
Those who collect and process Big Data should have boundaries, obviously. But these boundaries shouldn’t be restrictive nor should they leave businesses (especially SMEs) no choice but to quit a particular regional market altogether.
Creation of a global standard with internationally agreed-upon core principles would also be an immense boon. This should also go together with taking into consideration existing conditions and nuances, having clear-cut guidelines, and allowing sufficient transition periods to apply the needed changes.
Final Thoughts
When it comes to Big Data, it’s easy to get overwhelmed with its endless exciting possibilities. Nevertheless, critical assessment, the understanding of shortcomings and vulnerabilities (technological, ethical and legal), as well as strategies to address them should be at the core of any Big Data implementation.
Bio: Elena Yakimova is the Head of Web Testing Department at software testing company a1qa. She started her career in QA in 2008. Now Elena’s in-house QA team consists of 115 skilled engineers who have successfully completed more than 250 projects in telecom, retail, e-commerce, and other verticals.
Resources:
- On-line and web-based: Analytics, Data Mining, Data Science, Machine Learning education
- Software for Analytics, Data Science, Data Mining, and Machine Learning
Related:
- 7 Qualities Your Big Data Visualization Tools Absolutely Must Have and 10 Tools That Have Them
- How to Capture Data to Make Business Impact
- Overcoming distrust on the path to productive analytics