Data Science Projects That Can Help You Solve Real World Problems
The best way to learn Data Science is by solving real-world problems with the data and building your own portfolio. In this article, we will discuss three projects that you can work on to build your portfolio and impress interviewers.

Image by Author
Practical projects are the greatest way to learn about data science and machine learning. Data science assignments will expose you to all facets of this discipline and help you hone your skills with practical SQL, R, or Python experience. It will not only help you improve your data science skills and gain confidence, but it will also enable you to create compelling resumes. In this article, we will discuss various data science project ideas for beginners that will help you in building a strong data science portfolio.
With an exponential increase in the data in today’s world, data science has become the most sought-after field. All the companies in today's world get a competitive advantage if they leverage data science in an effective way. This has led to an increase in the number of job openings in all the companies for data analysts and data scientists. To get a job in this field, it's a great idea to show–off your skills by building data analytics projects to solve real-world problems. Before we start discussing the projects, let’s see why a Data Science project will help you in getting a job and why you should have an impressive data science project portfolio.
Why should you Build a Data Science Project Portfolio?
If you are really interested in the Data Science field, you should have a basic understanding of what kind of problems are solved using data science and how to approach them. If you want to get into this field, you would need an understanding of the skills required to solve specific data science problems. Online courses and books can only take you to a certain level but if you really want to get into this field, you should know how data is being used to solve real-world problems. To understand this, working on projects is the only way to help you get all the skills required for entering into Data Science.
Data Science projects will help you in understanding the various steps required to solve a problem:
- Defining the Problem and breaking it down into smaller steps
- Data Collection
- Exploratory Data Analysis
- Model Building
- Data Visualization and Storytelling
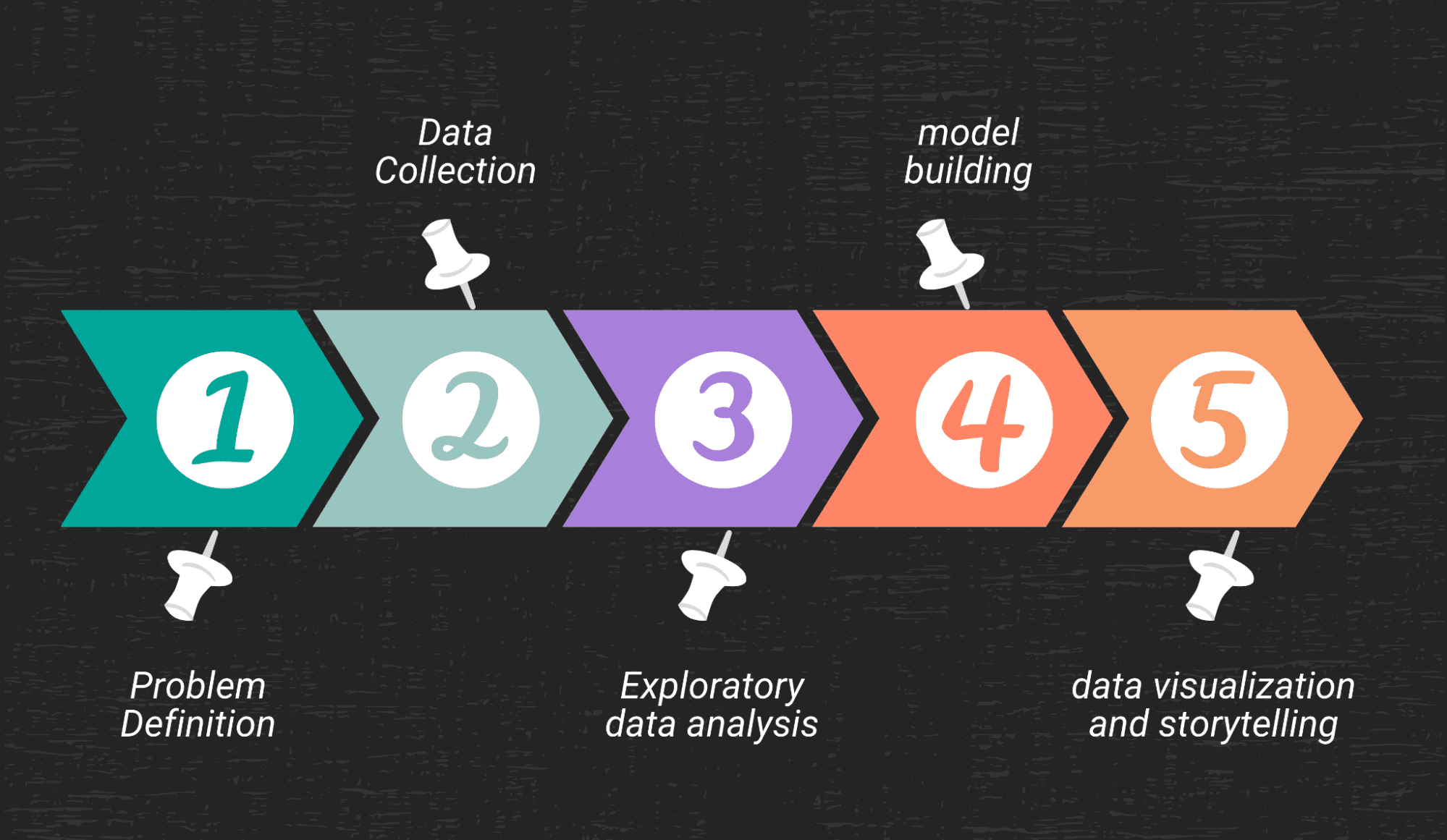
Image by Author
Problem Definition
This is the first step in any data science project. Any data science project begins with this step where you need to understand and define the problem clearly. This is one of the most important aspects of a data science project lifecycle. For example, if you want to invest your money in Tesla stock but you want to understand how retail investors are viewing the company, and what are the overall sentiments? Then you need to define this problem clearly. In this example, your problem statement would be: “Understand how Tesla is being perceived by the retail investors?”
Once you identify the problem, you need to understand what kind of data is needed to solve the problem.
Data Collection
Once you have identified the problem, the next step is data collection. You would need to identify the data sources from which you would be able to solve the problem you have defined in the first step. You may need to acquire data from one source or multiple sources using API.
For the example discussed in the first point, let’s say you are planning to invest in Tesla stock but are trying to understand the overall sentiment of retail investors toward this company. To solve this problem, you need to gather the information that will have comments about this company by retail investors. You decide to go on Twitter and see how people are reacting to different announcements by these companies. You can go through individual tweets and understand the sentiment since there will be millions of tweets available.
In such scenarios, you would need to get the data regarding tweets that talk about Tesla. To get the data, you will create a developer account on Twitter and use Python to extract the tweets using Twitter API. These will be the data collection steps required to solve any project. In most companies, there are dedicated Data Engineers who are responsible to gather data, but sometimes a Data Scientist would also need these skills to gather information using an API.
Exploratory Data Analysis
This is another important step in the Data Science project lifecycle. Exploratory data analysis is all about understanding the data, identifying the columns that are required, removing the columns that are redundant, missing value treatment, outlier detection, and identifying patterns in the data.
In the Twitter example discussed above, you will have to clean the tweets, remove the redundant information and keep only relevant tweets that are required for the analysis, understand the volume of tweets over time to find seasonality, etc. This step is used to understand and explore the data and make changes to the data if that doesn’t suit your needs.
Model Building
Once you have defined the problem, collected the data, and done the preliminary analysis using the techniques of EDA, you will be starting with the model-building phase. When you define a problem, you will realize whether that problem can be solved using supervised or unsupervised machine learning algorithms. Based on what your problem requires, you will need to understand what model to use.
This phase takes a bit of time to understand which model will be relevant to your problem. There are many models available in the market that can be used to solve the same problem and thus, you will need to evaluate these models based on their accuracy. Evaluation is a time-consuming process since there is a lot of trial and error involved in this step. Once your model is built and performs good-enough, then you can start working on data visualization and storytelling.
In the Twitter example discussed above, you can train a machine learning model using a labeled dataset (Information about each tweet that is tagged as either positive/negative/neutral). Once the model is trained, you need to input a new tweet to test the performance of that model. Once you test multiple samples, you can check the number of false positives and false negatives to understand how the model is performing. You will need to try out other models to compare the accuracy of different classification algorithms.
Data Visualization and Storytelling
If you do the analysis diligently but you are not able to convey the story properly, it's of no use. Communicating the insights that you find from the data to a non-technical audience is one of the most important skills required for a Data Scientist. There are many tools and techniques available for storytelling. You can use Tableau or Power BI to help you in building better visualizations.
Now that we have discussed the steps you need to take in a Data Science Project, let’s focus on some of the real-world data science projects that you can work on.
Data Science Project Ideas
There are many resources available on the web to get you started with data analytics and data science projects. In this section, we will discuss some of the project ideas that you can work on to solve real-world problems. The first step will be to identify the source of data and we will be discussing that as well.

Image by Author
Propensity Modeling
An approach called "propensity modeling" aims to forecast the likelihood that site users, leads, or customers will take particular actions. It is a statistical method that identifies the probability that a customer would do a certain action by taking into account all the independent as well as confounding factors that might influence customer behavior.

Image by Author
For example, a propensity model can be used by a marketing team to understand and determine the probability or likelihood that a lead might convert and become a paying customer. Or it can also be used to understand the likelihood of existing customers churning from the platform. Thus, propensity modeling can help the companies to allocate resources wisely and get better results thereby reducing costs. For example, instead of sending a marketing campaign to all 10K customers, a company can run propensity modeling to identify which customers are more likely to respond to emails and thereby send emails to only those specific customers which will result in time and resource savings. There is a good dataset on kaggle for propensity modeling to understand the propensity of customers to purchase a specific product.
Real-World Examples
There are many companies that use propensity modeling. Propensity modeling can be used in many applications such as determining propensity to purchase, propensity to churn, propensity to engage or predicting customer lifetime value.
This is majorly used by marketing teams of companies like Facebook/Meta, Google, Amazon, etc. Marketing teams rely heavily on the customers propensity scores to determine whether to invest in a specific customer cohort or not. Thus, having a propensity modeling project in your portfolio is a must. There is a great propensity modeling example on kaggle to understand which customers to target with their marketing campaigns.
Text Analytics
With technological advancement and digitization, there is an enormous amount of information available. Out of all this information, there is a lot of textual data on the internet. Companies leverage this textual data to understand what customers are saying about their companies, and what they are saying about their products and thereby make amends to their strategy. There is a good project on kaggle to perform the sentiment analysis from the movie review dataset.
Image by Author
There are many fields within text analytics and one of them is Natural Language Processing (NLP). NLP is used to break down the text data into machine readable format, tokenize the text data, extract meaning out of the data and then identify insights. There are many applications of natural language processing; understanding the sentiments of your customers, building conversational agents or chatbots, building services like Alexa or Siri, building language translation engines and many more. Thus, it is a good idea to have projects related to natural language processing in your portfolio.
Real-World Example
Almost all companies in today’s world use text analytics or natural language processing to understand their customers and build innovative products. For example, Facebook/Meta uses Text analytics heavily. Unlike Instagram which has the majority of data in the form of videos and photos, Facebook has mostly text data. They use this text data to automatically categorize posts into different categories and automatically remove the posts which are abusive. In fact, Facebook has developed an in-house tool called Deep Text which is used to analyze and extract the meaning of posts and thereby automatically identify abusive posts and remove them from the platform.
Other than Facebook, there are many companies that use Text analytics and machine learning to build innovative solutions for their customers. For example, Amazon built Alexa which is a smart virtual assistant. Alexa responds to customer queries with accuracy because it uses heavy machine learning algorithms underneath to first translate speech to text, then identify the meaning of the text using NLP, then use machine learning models to predict the next best response and then convert that response to an audio output.
Thus, Text Analytics or Natural Language Processing is being used by most of the innovative companies in today's world and it will be good to have an NLP project in your portfolio to excel in your next interview.
Recommendation Engine
Recommendation systems are an extended class of web applications which tries to identify the user response based on the user's historical data and recommends a new product or a new action that the user is most likely to take. Recommendation engines can be classified into two major groups; Content-based systems and Collaborative filtering systems.
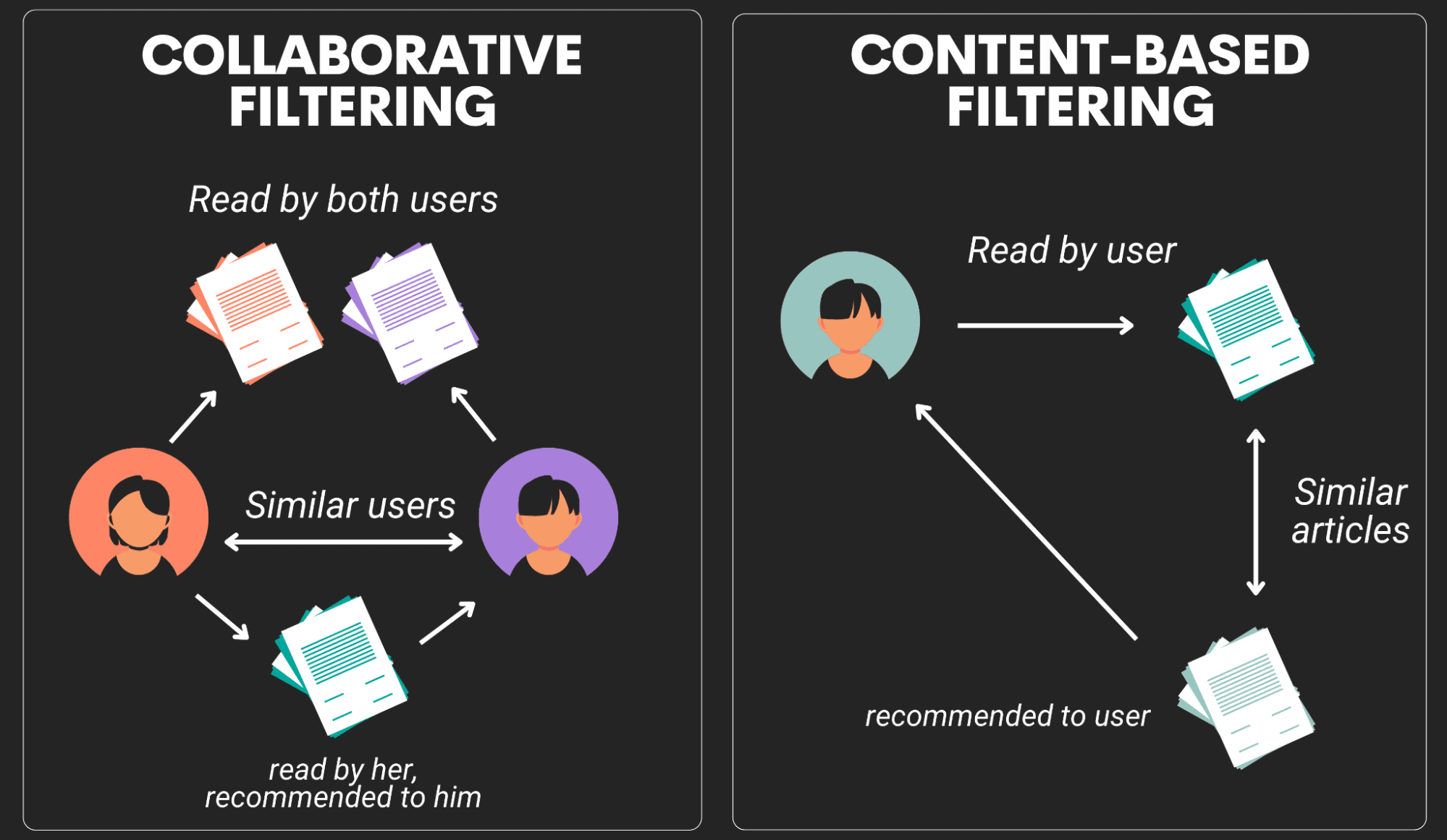
Image by Author
Content Based systems: In these engines, the recommendation is based on the content of an item. For example, if you have watched a lot of sci-fi movies on Netflix, then Netflix would recommend you new movies which are from the thriller categories and which might have similar categories.
Collaborative Filtering systems: In these engines, the recommendation is based on the similarity between the two users and if two users are similar, they might get a similar recommendation. For example, based on the historical data, if user 1 and user 2 has watched similar movies, then the recommender system will recommend a new movie to user 1 which might have been watched by user 2. Thus, the items that are recommended to a user are the ones preferred by similar users.
The best way to learn any concept is by doing a project and there is a really good one to build a fashion recommender engine in python.
Real-World Example
One of the most common examples of recommendation system is Netflix which recommends new movies, shows, documentaries based on the customers historical usage. Amazon also uses a recommender system to recommend similar products to its customers based on their buying or browsing history.
Using the vast quantity of data it collects, Netflix has created a recommendation engine for its users that operates in close to real-time. Each user's information is collected by Netflix, which then ranks users according to the kinds of content they view, search for, add to watch lists, etc. This kind of data is included in Big Data, and it is all stored in databases where machine learning algorithms can utilize it to create patterns that reveal the viewer's preferences. Since every user could have a different taste, this pattern might match another user or it might not. The recommendation system presents TV series or films that the user is likely to watch based on these ratings to each client.
Chatbots
The software programs known as chatbots, also referred to as chatter-bots or conversational agents, are frequently utilized in place of live agents to assist clients. Have you ever visited a website for customer service, chatted with a representative, and then learned that you were actually speaking with a "robot"? So you are aware of what chatbots are!

Image by Author
Chatbots are typically accessed by users through standalone apps or web-based apps. These days, customer service is where chatbots are most commonly used in the real world. Chatbots typically take over jobs that were formerly performed by actual humans, such as customer service representatives or support agents.
Chatbots are sophisticated computer programs that analyze customer text chats to determine the appropriate answer. All of these bots make use of natural language processing (NLP), which typically entails two steps: natural language understanding, which transforms and deconstructs the text provided by the client; and machine learning models, which help the bots grasp and extract the meaning of the sentence. The response to the customer's text is formed in the second step, known as natural language generation, using the meaning created in the first. The foundation for creating a chatbot is generally NLP.
Real-World Example
In recent years, artificial intelligence (AI) has sparked a wave of transformation. It has become the standard technology for every sector you can think of. Customers are willing to interact with bots if they are implemented properly, as demonstrated by some of the successful chatbot examples and case studies used by major businesses. Because of this, implementing the proper bot strategy and customizing your chatbot to suit your use case is crucial to the entire client experience.
Many companies have implemented a successful chatbots for basic queries:
- Dominos has implemented a chatbot through facebook messenger to ensure smooth order related question answering system
- HDFC bank has implemented a chatbot to answer basic questions from their customers related to finance.
There are many other companies who built chatbot and thus, its a great idea to have this project in your portfolio.
Summary
To enter into the field of Data Analytics and Data Science, it's very important to build a portfolio of projects which will help you in understanding the problem solving process and build a strong case in your next interview. In this article we discussed how building a project is critical to gain relevant skills required by a Data Scientist. We discussed the steps involved in solving a data science problem; Problem Definition, Data Collection, Exploratory Data Analysis, Model Building and Data Visualization and Storytelling.
You can get equipped with all these skills only by hands-on experience by working on projects. We also have discussed some real world project ideas that you can work on and how companies are leveraging it in today’s world. On StrataScratch, you can work on small projects which were given by many companies as take home assignments. So with that, start your practice with a bang and get your portfolio ready before your next interview.
Nate Rosidi is a data scientist and in product strategy. He's also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Connect with him on Twitter: StrataScratch or LinkedIn.