Beyond Siri, Google Assistant, and Alexa – what you need to know about AI Conversational Applications
We discuss industry trends in Artificial Intelligence with Vijay Ramakrishnan, a machine learning engineer and expert in conversational applications.
“Artificial intelligence (AI) is the new electricity”, according to Dr. Andrew Ng, the former Chief Scientist of Baidu and Adjunct Professor of AI at Stanford University. Hundreds of millions of people worldwide use conversational assistants for help accomplish daily tasks such as booking a flight or setting a kitchen timer.
Moreover, businesses that offer the smartest AI-powered conversational apps gain a strategic advantage in the marketplace as consumers increasingly expect human-like assistance from virtual avatars. Think Siri, Cortana, Google Assistant, and Alexa.
Amazon's Alexa Prize competition (NASDAQ: AMZN) incentivizes developers to create AI agents that can talk with humans about random topics. The world's richest person, Jeff Bezos, is presumably interested in acquiring promising AI innovations.
The benefits are substantial. By 2020, 25% of customer support will integrate virtual customer assistant (VCA) technology, according to 2018 study by Gartner. "Organizations report a reduction of up to 70% in call, chat and/or email inquiries after implementing a Virtual Customer Assistant (VCA) … They also report increased customer satisfaction and 33% savings per voice engagement," according to same study. By 2020, 30% of B2B companies will use AI to augment their sales function.
Vijay Ramakrishnan is machine learning (ML) engineer, researcher, and innovator in the conversational artificial intelligence (AI) field. At Cisco (NASDAQ: CSCO), Vijay develops the core machine-learning platform that supports the company's flagship voice-assistant, WebEx Meeting Assistant and is a fellow at Cisco’s AI/ML Center of Excellence (https://www.cisco-ai.com/). Vijay was ML engineer at Mindmeld Inc. where he developed intelligent agents for Fortune 500 companies. Mindmeld was acquired by Cisco in 2017.

How do you explain AI-powered conversational applications to developers?
AI-Assistants traditionally take as input some textual query, use machine learning models to understand the meaning of the text and perform some action based on it. Voice-based applications further have an Automatic Speech Recognition (ASR) component to convert analog voice signals to text.
But no matter the medium, application, or device that are used, all interfaces rely on core Machine Learning technologies like Natural Language Processing (NLP) and Information Retrieval (IR) techniques to understand language input and engage in human-like interactions.
With enterprises, it's further crucial to develop applications that can accomplish specific business-oriented tasks extremely well — such as booking a hotel reservation as compared to developing generic, chit-chat applications. A consequence of these narrow enterprise domains, along with strict data protection policies, is that Conversational AI developers have to build Machine Learning (ML) models for smaller datasets (typically less than 1000 queries per intent) which might overfit on vanilla deep-learning architectures.
Therefore, I recommend developers to start off with simpler models like support vector machines to build their Natural Language Understanding (NLU) systems. Recent research also suggest the use of unsupervised, pre-trained language models like BERT (Devlin et al., 2018) that are fine-tuned on small-domain dataset produce state-of-the-art NLU results.
What are consumers' expectations with the conversational AI apps you build?
Consumers expect quick and expert assistance when they communicate with an AI agent. And that's true whether they're at the office, at home, while driving, and everywhere in between. We are entering a world where voice and chat assistants are on 24/7 standby to help with daily tasks.
People expect their interactions with AI Assistants to be on the same par as with interacting with another human, and so when a particular conversation with the agent doesn’t go well, they tend to quickly write it off as “dumb” or “simple”. Therefore, AI agents need to solve one or two narrow use-cases really well in order to gain the trust of consumers or else people lose patience quickly.
Rest assured, virtual assistants like Siri, Cortana, Google Assistant, and Alexa receive millions of voice queries each month. And new voice-enabled devices such as Amazon Echo and Google Home are found in tens of millions of homes. These are one of fastest-growing product categories in recent time.
What conversational AI trends have you experienced over the past decade?
In my experience, there are two major trends in conversational AI that are driving a lot of value in the market: the first being the ever increasing strides in speech recognition and machine translation accuracy using data collected from mobile devices and a ML disciple called supervised learning.
Thus, virtual assistants started to see significant adoption and major tech companies began launching APIs on conversational interaction platforms. Even though there has been some consolidation in the space, the major AI platforms include Google Assistant, Cortana, and Siri, as well as, messaging platforms such as Facebook Messenger and Slack.

Image 1: Popular virtual assistants including Amazon’s Echo, Apple Siri, Google’s Assistant and Microsoft’s Cortana respectively. Photo credit: Geeksfl.com
The second trend I see is the successful application of large-scale language models to a variety of natural language processing (NLP) tasks like entity extraction and topic modelling. These models are trained on generic and massive internet corpora using unsupervised ML techniques and then applied to different and unrelated language problems.
For example, OpenAI’s GPT-2 model (Radford et al., 2018) trained on 40GB of internet data achieved state-of-the-art accuracy results on an entity recognition problem without even being trained on it. This trend significantly decreases the cost of sourcing training data for building a production quality AI model, which could be prohibitively expensive for certain use-cases.
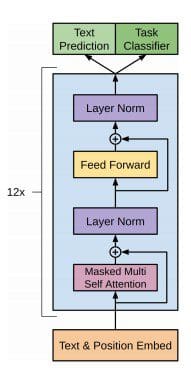
Image 2: Architecture of GPT, a language model trained unsupervised on multiple, large internet datasets. Photo credit: Radford et al., 2018
What are some challenges you face in creating useful conversational applications?
One of the major challenges of constructing great conversational experiences is working with domain-specific Automatic Speech Recognition (ASR) mistranscriptions. ASR systems are generally trained on generic word utterances like “cat” or “farm”, but when they encounter complex utterances like place names, say “Azerbaijan”, they would most often mis-transcribe it to “Azure Bajan”.
This is a perennial issue with ASR systems that affects decisions made by downstream applications like Natural Language Understanding (NLU) models. One solution is to use contextual information surrounding an user’s query to resolve the mistranscription. For example, based on past user interactions, the enterprise application can infer that a user is trying to book a flight to a country and isolates "Azure Bajan" to be matched against a list of countries. By using various textual matching techniques, we can further resolve "Azure Bajan" to "Azerbaijan".
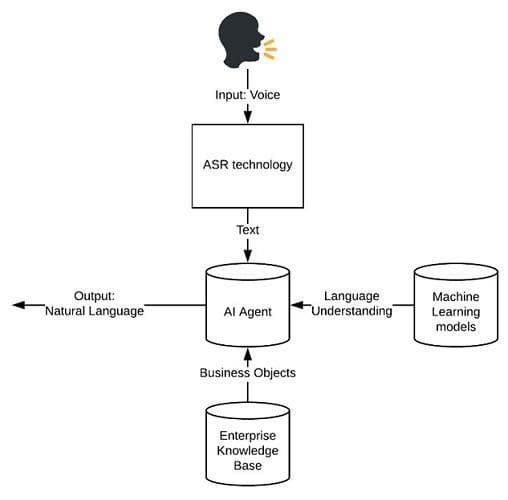
Image 3: General architecture of Enterprise Conversational AI systems. Photo credit: Vijay Ramakrishnan
Second, users like applications that impose few constraints on vocabulary: They want to speak to application as if talking with another human. Apps that understand broad-vocabulary natural language are extremely complicated due to combinatorial complexity of language. See the phenomenon called curse of dimensionality.
In my experience, AI developers have to use a combination of narrow-domain and generic training data to achieve the sweet-spot of building useful agents. Moreover, being well versed in the art of crowdsourcing queries that are semantically similar but syntactically different, think paraphrases, also helps AI models better understand the variety in human language.
Bio: Marvin Dumont covers blockchain, artificial intelligence, IoT, cloud, and cryptos for media outlets. His byline has appeared on Forbes, Bitcoin.com, HuffPost, TheStreet.com, and Entrepreneur. Marv received MPA, BBA, and BA degrees from University of Texas at Austin. Telegram @marvindumont.
Resources:
- On-line and web-based: Analytics, Data Mining, Data Science, Machine Learning education
- Software for Analytics, Data Science, Data Mining, and Machine Learning
Related:
- What is missing when AI makes a decision?
- XAI – A Data Scientist’s Mouthpiece
- The Deep Learning Toolset — An Overview