How to Make a Success Story of your Data Science Team
Today, data science is a crucial component for an organization's growth. Given how important data science has grown, it’s important to think about what data scientists add to an organization, how they fit in, and how to hire and build effective data science teams.
By Jan Teichmann, Senior Data Scientist at ZPG

Data science resounds throughout every industry and has reached the mainstream media. I no longer have to explain what I do for a living as long as I call it AI — we are at the peak of data science hype!
As a consequence, more and more companies are looking towards data science with big expectations, ready to invest into a team of their own. Unfortunately, the realities of data science in the enterprise are far from a success story.
NewVantage published a survey in January 2019 which found that 77% of businesses report challenges with business adaptation. This translates into ¾ of all data projects collecting dust rather than providing a return on the investment. Gartner has always been very critical of the data science success and they haven’t gotten more cheerful as of late: According to Gartner January 2019, even analytics insights will not deliver business outcomes through 2022, what’s the hope then for data science? It’s apparent that for some reasons making data science a success is really hard!

Regardless of whether you manage an existing data science team or are about to start a new greenfield project in big data or AI, it’s important to acknowledge the inevitable: the Hype Cycle.
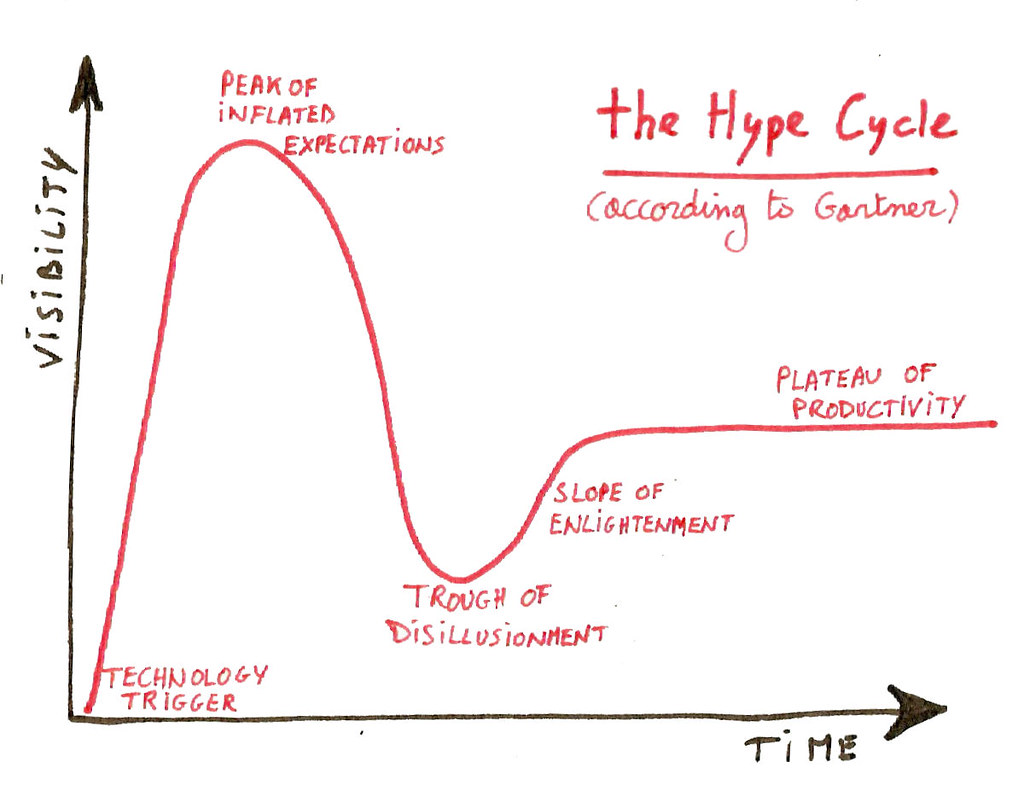
The increasing visibility of data science and AI comes hand in hand with a peak of inflated expectations. In combination with the current success rate of such projects and teams we are headed straight for the cliff edge towards the trough of disillusionment.
Christopher Conroy summarised it perfectly in a recent interview for Information Age: the renewed hype around AI simply gives a false impression of progress from where businesses were years ago with big data and data science. Did we just find an even higher cliff edge?
Thankfully, it’s not all bad news. Some teams, projects and businesses are indeed successful (around 30% according to the surveys). We simply need a new focus on the requirements for success.
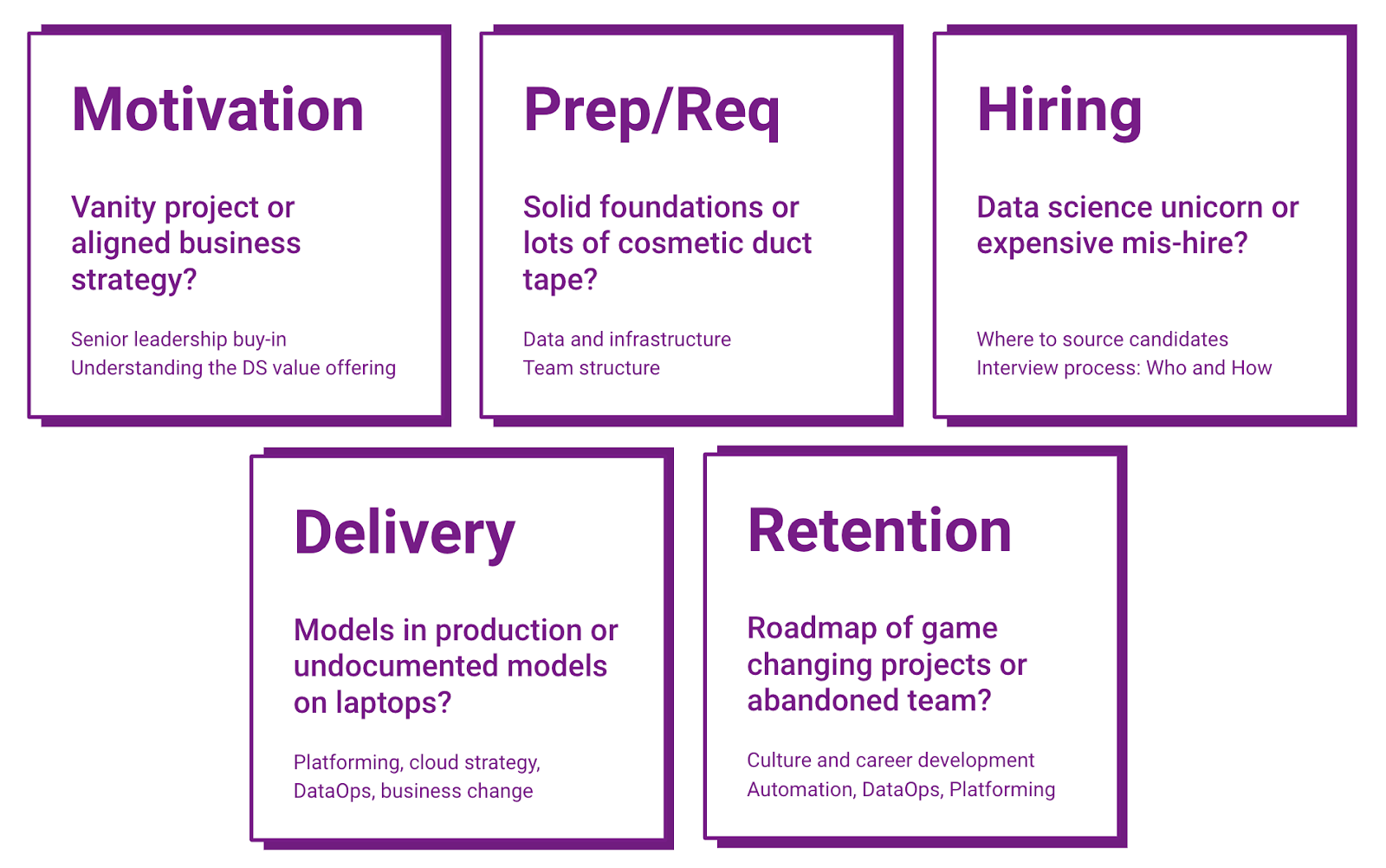
The first important fact is that there is not one priority or one thing which characterises successful companies in the data science space.
There are no silver bullets or short cuts for success!
There are generally five wider themes for data science success. Some themes are well understood and widely discussed like the importance of culture. Other themes highlight misconceptions which causes for example the underestimated importance of technology in the retention of data science teams. The importance of technology is a key factor to why most successful companies in the data science space are tech-companies. Not because only tech-companies have the means to solve the technology requirements but because they have a better understanding of the challenges and their suitable solutions. But don’t despair! Thankfully, with the growing maturity of cloud solutions and PaaS this can be achieved in any industry.
Motivation
The first differentiator for commercial success with data science is the business’s motivation to start a team in the first place. The motivation makes all the difference between the endeavour becoming a vanity project or being aligned with business strategy.
From my experience, data science requires a business motivated by a vision rather than short term goals. This is founded in the complexity and timelines of data science and data innovation. Data science is still a synonym for innovation which is difficult to deliver against a quickly changing priority of short term goals. Companies who look at data science to achieve their vision also demonstrate a better understanding of what data science actually is and how it adds value.
The motivation will also be the stand or fall of any culture or business change efforts which come with a business’s transformation to become data driven.
A good litmus test for the motivation is the senior leadership buy-in.
Preparations and Requirements
However, many big data and data science projects never made it past their preliminary stages regardless of the best intentions because the requirements and foundations were simply not in place.
Infrastructure
There are the obvious requirements around data infrastructure: any data team needs access to quality data and suitable infrastructure to work with such data. But what does a good infrastructure look like? It depends on your data volumes and volatility and the market for data solutions is evolving so rapidly that any recommendation is outdated by the time I publish this. But there is a constant ground truth and
your litmus test for data infrastructure should be multi-tenancy and an ability to experiment in production.

As data volumes and volatility increases, it becomes infeasible or cost prohibitive to maintain separate environments such as production and development environments for your data. You will have to come to terms with the data science requirement of Experimentation in Production. If you have to keep data scientists as far away from production data stores and pipelines as possible simply to guarantee their performance then you do not have good multi-tenancy. Multi-tenancy is not the same as scalability and scalability alone is not a solution. Whatever capacity or elasticity your data infrastructure has your data scientists will eventually use it all and stand in direct conflict with your mission critical data processes. Good multi-tenant native technologies are the only solution to share data and resources cost-effectively and securely with 1) data placement control, 2) job placement control, 3) access control and 4) admin, audit and reporting.
Additionally, your infrastructure needs a level of agility. As you will see most data science projects (hopefully not the team) are very short lived and have a high failure rate. You simply do not know where the data will take you and whether there is a feasible model at the end of each idea. To maintain productivity your infrastructure needs agility to support short lived projects with high failure rates.
Team and Org Structures
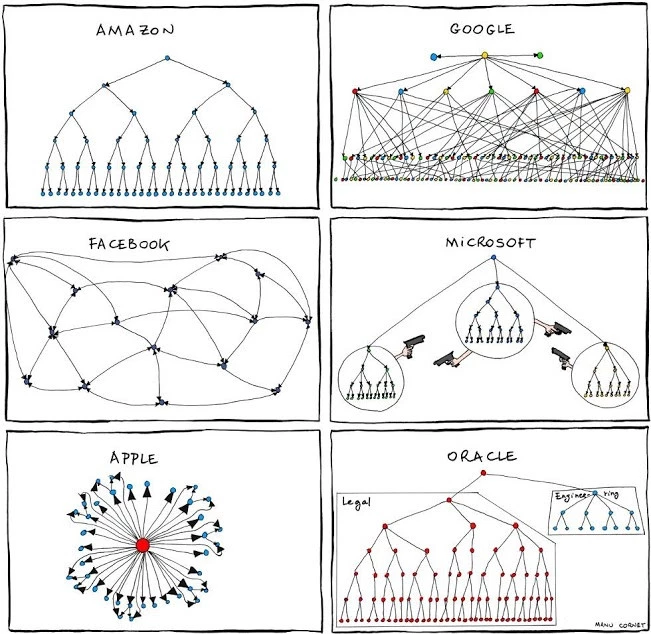
Team and organisational structure is an important consideration. There are many ways to organise and structure teams but simply changing where people sit will not solve many problems. The trend points towards cross-functional project teams which are motivated by a shared goal or mission statement. No difference for data science. In particular in bigger companies with many product teams or business units a centralised team will struggle to align with business priorities and ends up being isolated.
But placing data scientists in cross-functional squads easily isolates them from their peers. That’s a problem when it has an impact on culture and consequently retention of data scientists. Additionally, isolating data scientists from their peers will limit their ability to solve problems innovatively and to overcome challenges or blockers. Data scientists who can solve any business problem and are great generalists and perfect specialists at the same time still have unicorn status. It’s unlikely to find one for each squad or business unit. A centralised data science team benefits from a wider cross-section of skills and makes retention easier.
There are interesting new approaches, e.g. running a citizen data science initiative which relies on technology to overcome skills gaps in an analytics and data science self-service/empowerment strategy. Accenture published an extensive review of org structures for analytics and data science.
Whatever structure is right for your business, data scientists need support from other functions such as engineering, data architecture, DevOps and product. In the end, it does not matter to the success of data science whether this support exists within cross-functional teams or is accessible via good collaboration and robust prioritisation between teams and departments.
Data science is a team sport!
Hiring
Don’t get misled by the increasing supply of data scientist in the market. Data science is still an innovation subject and there are as few experienced data science ‘unicorns’ out there as before. To attract experienced data scientist a business has to look at much more than just competitive salary levels. The people who make up successful data science teams are driven by curiosity, they love to play with new technology and are motivated by the opportunities and challenges a business can offer them.
Building a new team comes with some obvious challenges: where do you source good candidates and what is a suitable interview process? There is also a ‘chicken or the egg’ dilemma of who should build the team? Ideally an experienced senior data science manager with some hands-on experience to navigate the buzzwords and identify the talent.

Getting that first hire right is important and the right candidate will interview you more than the other way round.
Your litmus test is to get challenged by candidates on senior leadership buy-in, motivation, infrastructure, business change processes, delivery pipelines and culture.
In the current market where there is a shortage of talent it is crucial that companies have a good recruitment process. When talent is in short supply businesses need to be lightning fast with feedback to agencies and candidates, every single time. The candidate is king. If candidates have a bad experience it will have an adverse effect on the reputation of the business and the best candidates go elsewhere.
If you want to include some form of test or presentation as part of your recruitment process than be prepared to reward the effort of candidates with an equivalent time investment to go through their submissions and provide detailed feedback. And above all, make it business relevant! Stay away from exam like setups with pseudo code on whiteboards. No data scientist has to work like this in their day-to-day job or is ever expected to.
Technical interviews like this are still way too popular with hiring managers.
Delivery
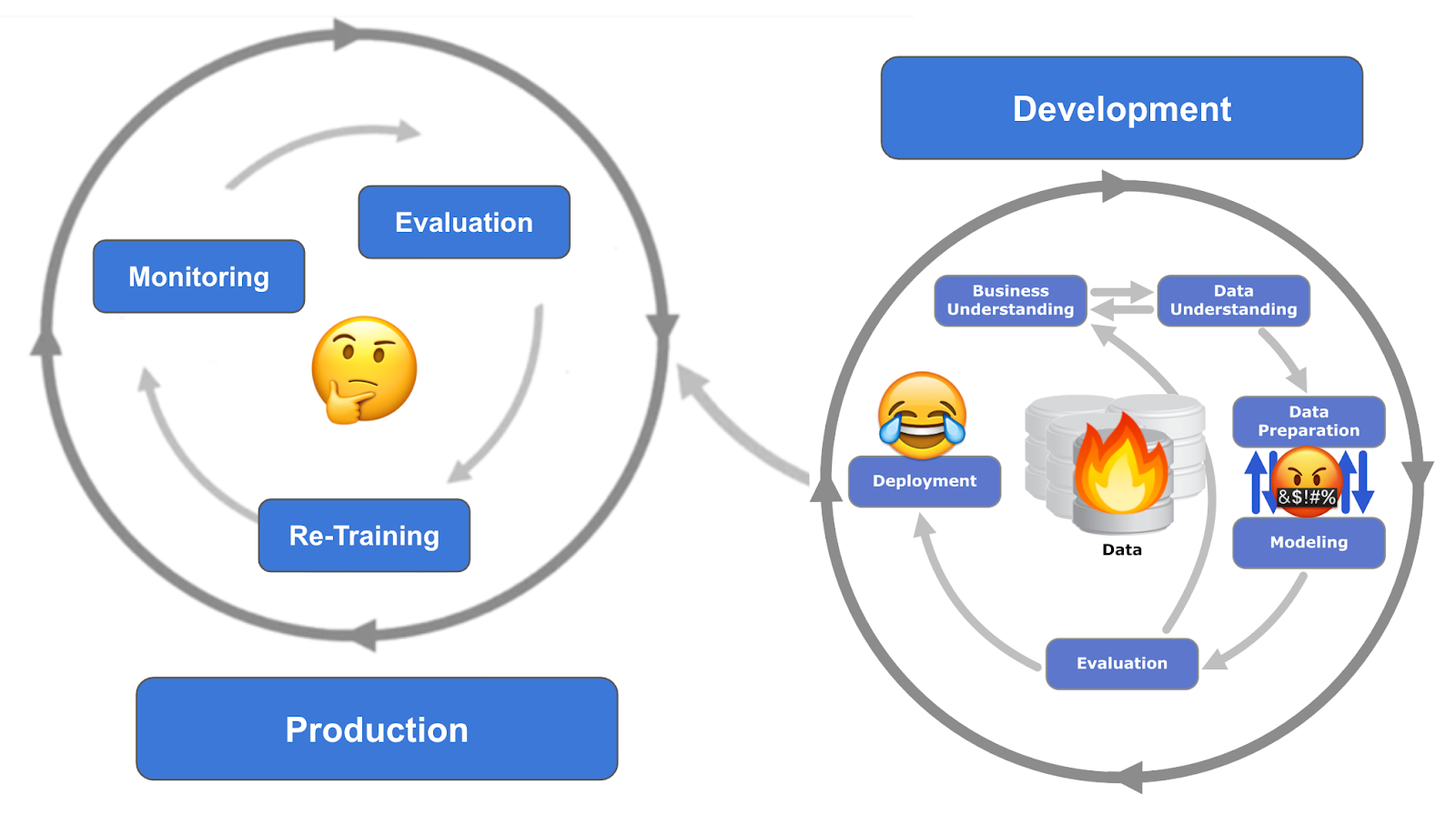
Delivery is the topic with the most misconceptions: commercial data science has to overcome much fewer scientific problems than technological challenges. Unfortunately, there is an unnecessary focus on the challenges of data preparation even though production deployment of models is the toughest challenge in commercial data science. For a data science team to be commercially successful it needs a delivery pipeline which meets the following requirements:
- Evaluate a big number of incumbent and challenger models in parallel
- Manage the model life cycle
- Handle an increasing heterogeneity of data science toolkits
- Allow experimentation in production without impacting the user experience and decouple the business objectives from the data science objectives
- Decouple enterprise requirements like SLAs and GDPR from the data science models
- Scale this to peaks of 50+k page loads per minute without hiring armies of DevOps engineers
All of this are technical challenges and not scientific problems. Read about a solution called Rendezvous Architecture in my article about Machine Learning Logistics. A key priority is the automation of the model lifecycle management in production or DataOps. It would be a mistake to rely on data scientists for your DataOps: it’s not a robust or scalable solution and it will frustrate the data scientists which quickly causes them to leave.
Successful data science delivery benefits from a robust business change process. The data transformation of a business to become data driven will cause significant change. Data science, innovation and general business change should never be a battle of interests but a well defined and objective change management process.
UI, UX and Design

Data science is equivalent with experimentation in production and even the best models stand or fall with the user experience of their integration and execution. Models will never be 100% correct and UI and UX has to take that into account. The imperfections of your recommendation engine for example should not result in equal frustrations of users having to navigate them. When you action a propensity score, e.g. for up-selling, how intrusive should that intervention be taking the uncertainties into account? From my experience, many data science projects fail to deliver not because the maths was wrong but because the UX was bad.
Retention
Culture is the most important retention tool there is and has importance way beyond retention at the same time. Not just for data science!

Data science culture is more than just company perks and benefit packages. Any talent is motivated by their work making an impact but business adaptation of data science can be slow and cause frustration. At the same time, data science has a strong community organising meet-ups, conferences and hackathons. This should be leveraged by businesses as part of their investment into culture. Why not host a meet-up or lunch-and-learn and give your data scientists a platform to present their work and improve their visibility within the business? Why not organise a hackathon? The important thing to keep in mind though is that culture is not created overnight and a one-time consideration. It will terribly backfire if you have no strategy to follow up your hackathons and get promising ideas onto the backlog afterwards. You do not want your hackathons to further highlight the inability of business adaptation.

More uniquely to data science, technology plays an important role in retention.
There is an important link between a scalable delivery pipeline and a happy data scientist.
Data scientists are motivated by developing new models to solve relevant business problems rather than the day-to-day operational responsibilities of models in production. This means that data infrastructure, data science platforming, automations and DataOps are crucial problems not just for the delivery of business outcome but also for the retention of the team long term. Any data scientist who delivered a model end-to-end into production becomes extremely valuable in a market where over 75% of teams fail to do so. Day-to-day maintenance and monitoring of models in production won’t be a good way to retain that talent. Quickly, you find yourself with an unmaintained model in production which is drifting and there is no one left who understands how the model ever worked in the first place.
Delivery, technology and retention are all tightly coupled to the long term success of data science.
Last but not least: you need a career development strategy for your data scientists! At the moment, too many data scientists change jobs to get career progression or to find new and exciting challenges to solve. On the one hand, this includes support and acknowledgment of learning and development needs in a constantly changing domain as part of your career framework. On the other hand, data science is still an emerging business domain and it is not very business conform as of yet. Your career framework needs flexibility to accommodate this.
Bio: Jan Teichmann is a Senior Data Scientist at ZPG
Original. Reposted with permission.
Related: