The Data Fabric for Machine Learning – Part 2: Building a Knowledge-Graph
Before being able to develop a Data Fabric we need to build a Knowledge-Graph. In this article I’ll set up the basis on how to create it, in the next article we’ll go to the practice on how to do this.

Introduction
In the last articles of the series:
I’ve been talking about the data fabric in general, and giving some concepts of Machine Learning and Deep Learning in the data fabric. And also gave my definition of the data fabric:
The Data Fabric is the platform that supports all the data in the company. How it’s managed, described, combined and universally accessed. This platform is formed from an Enterprise Knowledge Graph to create an uniform and unified data environment.
If you take a look at the definition, it says that the data fabric is formed from an Enterprise Knowledge Graph. So we better know how to create and manage it.
Objectives
General
Set up the basis of knowledge-graphs theory and construction.
Specifics
- Explain the concepts of knowledge-graphs related to enterprises.
- Give some recommendation about building a successful enterprise knowledge-graph.
- Show examples of knowledge-graphs.
Main theory
The fabric in the data fabric is built from a knowledge-graph, to create a knowledge-graph you need semantics and ontologies to find an useful way of linking your data that uniquely identifies and connects data with common business terms.
Section 1. What is a Knowledge-Graph?

The knowledge graph consists in integrated collections of data and information that also contains huge numbers of links between different data.
The key here is that instead of looking for possible answers, under this new model we’re seeking an answer. We want the facts — where those facts come from is less important. The data here can represent concepts, objects, things, people and actually whatever you have in mind. The graph fills in the relationships, the connections between the concepts.
In this context we can ask this question to our data lake:
What exists here?
We are in a different here. A one where it’s possible to set up a framework to study data and its relation to other data. In a knowledge-graph information represented in a particular formal ontology can be more easily accessible to automated information processing, and how best to do this is an active area of research in computer science like data science.
All data modeling statements (along with everything else) in ontological languages and the world of knowledge-graphs for data are incremental, by their very nature. Enhancing or modifying a data model after the fact can be easily accomplished by modifying the concept.
With a knowledge-graph what we are building is a human-readable representation of data that uniquely identifies and connects data with common business terms. This “layer” helps end users access data autonomously, securely and confidently.
Remember this image?

I proposed before that insights in the data fabric can be an insight can be thought as a dent in it. And the automatic process of discovering what that insight is, it’s machine learning.
But what is this fabric? Is the object formed by the knowledge-graph. Like in Einstein’s theory of relativity, where the fabric is made by the continuum (or discrete?) of spacetime, here the fabric is built when you create a knowledge-graph.
For building the knowledge-graph you need linked data. The goal of linked data is to publish structured data in such a way that it can be easily consumed and combined with other linked data, and ontologies as the way we can connect entities and understand their relationships.
Section 2. Creating a Successful Enterprise Knowledge Graph

A while ago Sebastien Dery wrote an interesting article about the challenges of knowledge-graphs. Here you can take a look:
Challenges of Knowledge Graphs
From Strings to Things — An Introduction medium.com
And from the great blog at cambridgesemantis.com
and more resources, one of the concepts that I haven’t even mention in any article, but is very important, is the concept of triples: subject, object, and predicate (or entity-attribute-value). Commonly when you study triplets they actually mean the Resource Description Framework (RDF).
RDF is one of the three foundational Semantic Web technologies, the other two being SPARQL and OWL. RDF is the data model of the Semantic Web.
NOTE: Oh btw, almost all this concepts came with the new definition of semantics for the world wide web, but we will use it for knowledge-graphs in general.
I’m not going to give a full description of the framework here, but I’ll give you an example on how they work. Remember that I’m doing this because is the way we start building ontologies, linking data and the knowledge-graph.
Let’s take a look at an example to see what this triples are. This is closely related to the example from Sebastien.
We will start with the string “geoffrey hinton”.

Here we have a simple string that represents first edge, the thing I want to know more about
Now to start building a knowledge-graaph first the system recognizes the that string actually meant the person Geoffrey Hinton. And then it will recognize the related entities to that person.
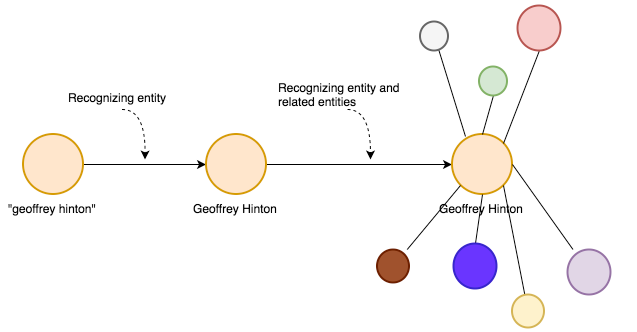
Then we have some entities that are related to Geoffrey but we don’t know what they are yet.
Btw, this is Geoffrey Hinton if you don’t know him:

And then the system will start giving names to the relationships:
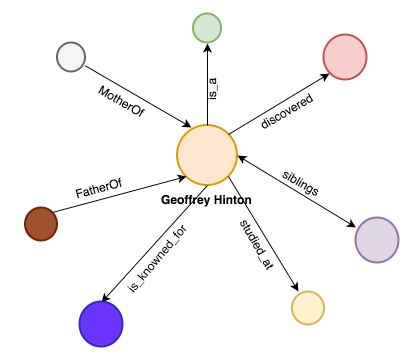
Now we have named relationships where we know what type of connection we have for our main entity.
This system can go for a while finding connections of connections and thus creating a huge graph representing the different relationships for our “search string”.
To do this the knowledge-graph uses the triples. Like this:
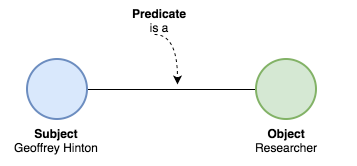
To have a triple we need a subject and object, and a predicate linking the two.
So as you can see we have the subject <Geoffrey Hinton> related to the object <Researcher> by the predicate <is a>. This may sound easy for us humans, but it needs a very comprehensive framework to do this with machines.
This is the way the knowledge-graph gets formed and how we link data using ontologies and semantics.
So, what do we need to create a successful knowledge-graph? Partha Sarathi from Cambridge Semantics wrote a great blog about that. You can read it here:
And to sum up, he says we need:
- People that envision it: You need people with the intersection of some form of business-critical subject matter expertise and technology.
- Data diversity and probably a high volume of it: The value and scale of adoption of an Enterprise Knowledge Graph are directly proportional to the diversity of data encompassed by it.
- A good product to built it: The knowledge graph needs to be, among others, well-governed, secure, easily connectable to upstream and downstream systems, analyzable at scale, and, more often than not, cloud-friendly. The product used for creating a modern Enterprise Knowledge Graph thus needs to be optimized for automation, support connectors for a wide array of input systems, offer standards-based data output to downstream systems, render any volume of its data analyzable rapidly, and make governance user-friendly.
You can read more here:
Section 3. Knowledge-Graphs examples
Google:

Google is a basically a huge knowledge (with more additions) graph and they created maybe the biggest data fabric there is upon that. Google has billions of facts that includes information about and relationships between millions of objects. And allow us to search through their system to discover insights inside it.
Here you can learn more:
LinkedIn:

My favorite social network LinkedIn has a huge knowledge graph base built upon “entities” on LinkedIn, such as members, jobs, titles, skills, companies, geographical locations, schools, etc. These entities and the relationships among them form the ontology of the professional world.
Insights help leaders and sales make business decisions, and increase member engagement with LinkedIn:
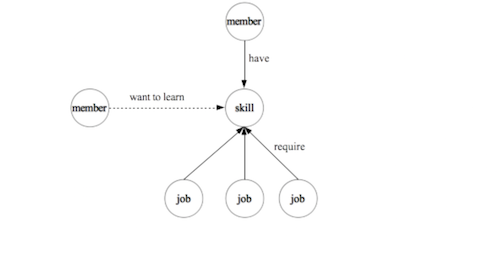
Remember that LinkedIn (and almost every) knowledge-graph needs to scale as new members register, new jobs are posted, new companies, skills, and titles appear in member profiles and job descriptions, etc.
You can read more here:
Knowledge-graphs for financial institutions:
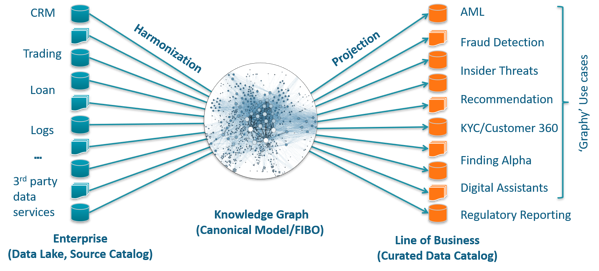
In this article by Marty Loughlin, he showed an example of what the platform Anzo can do for a bank, and there you can see that this technology is not only related to search engines and works with disparate data.
There he shows how a knowledge-graph can help this kind of institution with:
- Alternative Data for Analytics and Machine Learning
- Interest Rate Swap Risk Analytics
- Trade Surveillance
- Fraud Analytics
- Feature Engineering & Selection
- Data Migration
and more. Go take a look.
Conclusion

To create a knowledge-graph you need semantics and ontologies to find an useful way of linking your data that uniquely identifies and connects data with common business terms and thus building the underlaying structure of the data fabric.
When we build a knowledge-graph we need to form triples to link data using ontologies and semantics. Also the manufacturing of the knowledge-graph depends on basically three things: People that envision it, data diversity and a good product to built it.
There are many examples of knowledge-graphs around us that we don’t even know. Most successful companies in the world are implementing and migrating their systems to build a data fabric and of course all the things inside of it.
Bio: Favio Vazquez is a physicist and computer engineer working on Data Science and Computational Cosmology. He has a passion for science, philosophy, programming, and music. He is the creator of Ciencia y Datos, a Data Science publication in Spanish. He loves new challenges, working with a good team and having interesting problems to solve. He is part of Apache Spark collaboration, helping in MLlib, Core and the Documentation. He loves applying his knowledge and expertise in science, data analysis, visualization, and automatic learning to help the world become a better place.
Original. Reposted with permission.
Related:
- My Best Tips for Agile Data Science Research
- How to Monitor Machine Learning Models in Real-Time
- The year in AI/Machine Learning advances: Xavier Amatriain 2018 Roundup