10 New Things I Learnt from fast.ai Course V3
Fastai offers some really good courses in machine learning and deep learning for programmers. I recently took their "Practical Deep Learning for Coders" course and found it really interesting. Here are my learnings from the course.
By Raimi Bin Karim, AI Singapore

Everyone’s talking about the fast.ai Massive Open Online Course (MOOC) so I decided to have a go at their 2019 deep learning course Practical Deep Learning for Coders, v3.
I’ve always known some deep learning concepts/ideas (I’ve been in this field for about a year now, dealing mostly with computer vision), but never really understood some intuitions or explanations. I also understand that Jeremy Howard, Rachel Thomas and Sylvain Gugger (follow them on Twitter!) are influential people in the deep learning sphere (Jeremy has a lot of experience with Kaggle competitions), so I hope to gain new insights and intuitions, and some tips and tricks for model training from them. I have so much to learn from these folks.
So, here I am after 3 weeks of watching the videos (I didn’t do any exercises ????????????????) and writing this post to compartmentalise the new things I learnt to share with you. There were of course some things I was clueless about so I did a little bit more research on them, and presented them in this article. Towards the end, I also write about how I felt about the course (spoiler alert: I love it ❣️).
Disclaimer Different people gather different learning points, depending on what deep learning background you have. This post is not recommended for beginners of deep learning and is not a summary of the course contents. This post instead assumes you have basic knowledge of neural networks, gradient descent, loss functions, regularisation techniques and generating embeddings. Some experience of the following would be great too: image classification, text classification, semantic segmentation and generative adversarial networks.
I organised the content of my 10 learning points as such: from the theory of neural networks, to architectures, to things related to loss function (learning rate, optimiser), to model training (and regularisation), to the deep learning tasks and finally model interpretability.
Contents: 10 New Things I Learnt
- The Universal Approximation Theorem
- Neural Networks: Design & Architecture
- Understanding the Loss Landscape
- Gradient Descent Optimisers
- Loss Functions
- Training
- Regularisation
- Tasks
- Model Interpretability
- Appendix: Jeremy Howard on Model Complexity & Regularisation
0. Fast.ai & Transfer Learning
“It’s always good to use transfer learning [to train your model] if you can.” — Jeremy Howard
Fast.ai is synonymous to transfer learning and achieving great results in a short amount of time. The course really lives up to its name. Transfer learning and experimentalism are the two key ideas that Jeremy Howard keeps emphasizing in order to be efficient Machine Learning Practitioners.
1. The Universal Approximation Theorem

The universal approximation theorem says that you can approximate any function with just one hidden layer in a feed-forward neural network. This follows that you can also achieve the same kind of approximation for any neural network that goes deeper.
I mean, wow! I just got to know this like only now. This is the fundamental of deep learning. If you have stacks of affine functions (or matrix multiplications) and nonlinear functions, the thing you end up with can approximate any function arbitrarily closely. It is the reason behind the race for different combinations of affine functions and nonlinearities. It’s the reason why architectures are getting deeper.
2. Neural Networks: Design & Architecture

- ResNet-50 is pretty much SOTA, hence you would generally want to use it for many image-related tasks like image classification and object detection. This architecture is used a lot in the course’s Jupyter notebooks.
- U-net is pretty much the state of the art for image segmentation tasks.
- For convolutional neural networks (CNNs), stride=2 convolutions are common for the first few layers
- DenseNet uses concatenation as the final operation in the building blocks, whereas ResNet uses the addition operation.
- Dropout
At random, we throw away activations. Intuition: so that no activation can memorise any part of the input. This would help with overfitting wherein some part of the model is basically learning to recognise a particular image rather than a particular feature or item. There’s also embedding dropout but that was briefly touched upon. - Batch normalisation (BatchNorm)
BatchNorm does 2 things: (1) normalise activations, and (2) introduce scaling and shifting parameters to each normalised activation. However, it turns out that (1) is not as important as (2). In the paper How Does Batch Normalization Help Optimization?, it was mentioned that “[BatchNorm] reparametrizes the underlying optimization problem to make its landscape significantly smooth[er].” Intuition is this: because it’s now less bumpy, we can use a higher learning rate, hence faster convergence (see Fig. 3.1).
3. Understanding the Loss Landscape
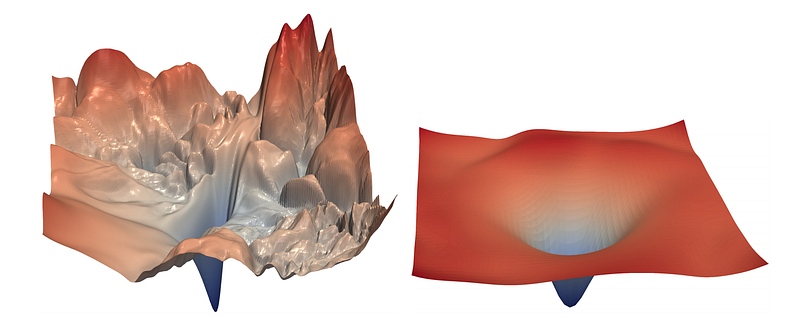
Fig 3.1: Loss landscapes; left landscape has many bumps, right is a smooth landscape. Source: https://arxiv.org/abs/1712.09913
Loss functions usually have bumpy and flat areas (if you visualise them in 2D or 3D diagrams). Have a look at Fig. 3.2. If you end up in a bumpy area, that solution will tend not to generalise very well. This is because you found a solution that is good in one place, but it’s not very good in other place. But if you found a solution in a flat area, you probably will generalise well. And that’s because you found a solution that is not only good at one spot, but around it as well.
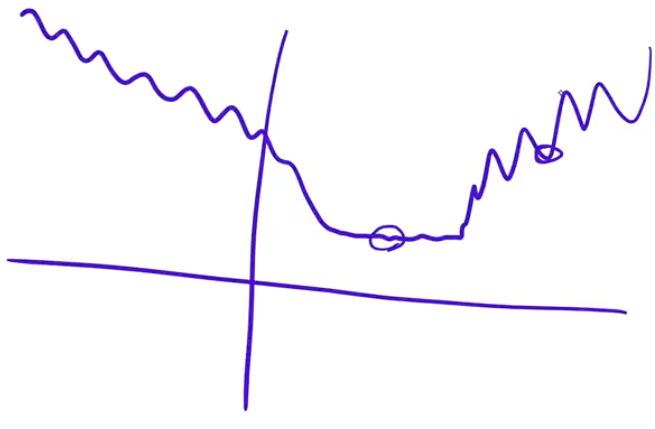
Fig. 3.2: Loss landscape visualised in a 2D diagram. Screenshot from course.fast.ai. Most of the above paragraph are quoted from Jeremy Howard. Such a simple and beautiful explanation.
4. Gradient Descent Optimisers
The new thing I learnt was that the RMSprop optimiser acts as an “accelerator”. Intuition: if your gradient has been small for the past few steps, obviously you need to go a little bit faster now.
(For an overview of gradient descent optimisers, I have written a post titled 10 Gradient Descent Optimisation Algorithms.)
5. Loss Functions
Learnt 2 new loss functions:
- Pixel mean squared error (Pixel MSE). This can be used in semantic segmentation, which was one of the course contents but not covered in this article.
- Feature loss ????. This can be used in image restoration tasks. See Task: Image Generation.
6. Training

This section looks into a combination of tweaks for:
- Weight initialisation
- Hyperparameter setting
- Model fitting/fine-tuning
- Other improvements
Transfer learning
Model weights can either be (i) randomly initialised, or (ii) transferred from a pre-trained model in a process called transfer learning. Transfer learning makes use of pre-trained weights. Pre-trained weights have useful information.
The usual model fitting for transfer learning works like this: train the weights that are closer to the output and freezes the other layers.
It is important that for transfer learning, one uses the same ‘stats’ that the pre-trained model was applied with, eg. correcting the image RGB values with a certain bias.
❤️ 1cycle policy ❤️
This is truly the best thing I learnt in this course. I am guilty of taking learning rates for granted all this while. Finding a good learning rate is important, because we can at the very least provide our gradient descent with an educated guess of a learning rate, rather than some gut feeling value that might just be suboptimal.
Jeremy Howard keeps using lr_finder() and fit_one_cycle() in his code and it bothers me that it works well but I don’t know why it works. So I read the paper by Leslie Smith and Sylvain Gugger’s blog post (recommended readings!), and this is how 1cycle works:
1. Perform an LR range test: train the model with (linearly) increasing learning rates from a small number (10e-8) to a high number (1 or 10). Plot a loss vs. learning rate graph like below.
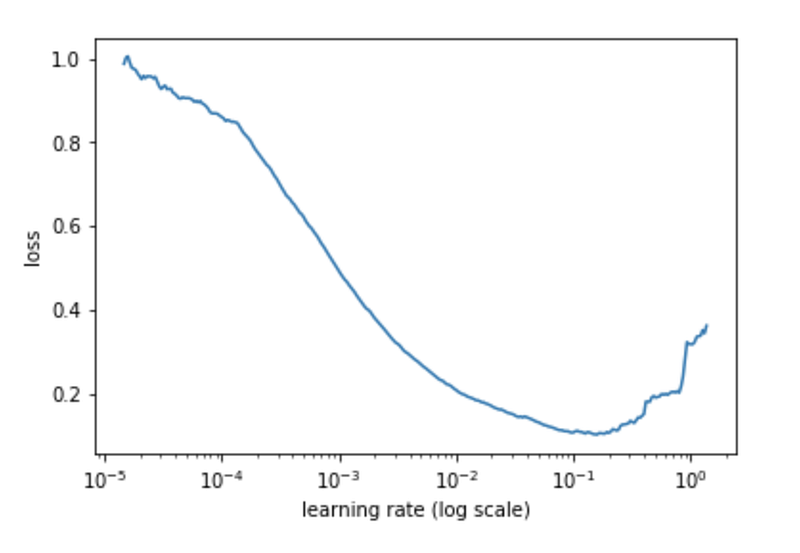
2. Choose minimum and maximum learning rate. To choose maximum learning rate, look at the graph and pick a learning rate that is high enough and give lower loss values (not too high, not too low). Here you’d pick 10e-2. Choosing the minimum can be about ten times lower. Here it’d be 10e-3. For more information how to pick these values.
3. Fit the model by the no. of cycles of cyclical learning rate. One cycle is when your training runs through the learning rates from the chosen minimum learning rate to the chosen maximum, then back to the minimum.
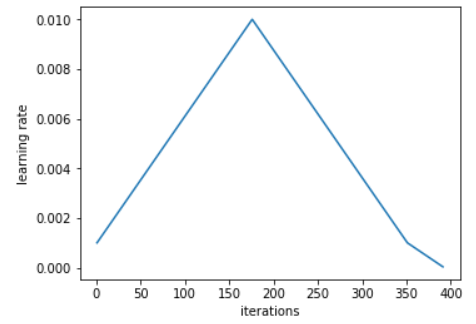
So why do we do it this way? The whole idea is the following. In a loss landscape, we want to jump over the bumps (because we don’t want to get stuck at some trench). So increasing the learning rate at the start helps the model to jump out away from that trench, explore the function surface and try to find areas where the loss is low and the region is not bumpy (because if it’s bumpy, it gets kicked out again). This enables us to train the model more quickly. We also tend to end up with much more generalisable solutions.

Discriminative learning rates for pre-trained models
Train earlier layer(s) with super low learning rate, and train later layers with higher learning rate. The idea is to not drastically alter the almost-perfect pre-trained weights except for minuscule amounts, and to be more aggressive with teaching the layers near the outputs. Discriminative learning rate was introduced in ULMFiT.
A magic number divisor
In the 1cycle fitting, to get the minimum learning rate, divide maximum with 2.6⁴. This number works for NLP task. See https://course.fast.ai/videos/?lesson=4 at 33:30 for more information.
Random forest for hyperparameter search
It was mentioned that random forest can be used to search for hyperparameters.
Using default values
When using a library or implementing a paper’s code, use the default hyperparameter values and “don’t be a hero”.
Model fine-tuning for pre-trained models
I notice Jeremy’s style: after training the last layers, unfreeze all layers and train all weights. However, this step is experimental because it may or may not improve accuracy. If it doesn’t, I hope you have saved your last trained weights ????.
Progressive resizing
This is most applicable to image-related tasks. Start training using smaller versions of the images. Then, train using larger versions. To do this, use transfer learning to port the trained weights to a model with the same architecture but accepts different input size. Genius.
Mixed precision training
A simplified version what this does is to use single precision (float32) data type for backpropagation, but half precision (float16) for forward pass.
7. Regularisation

Use the magic number 0.1 for weight decay. If you use too much weight decay, your model won’t trained well enough (underfitting). If too little, you’ll tend to overfit but that’s okay because you can stop the training early.
8. Tasks

- Multi-label classification
- Language Modelling
- Tabular Data
- Collaborative Filtering
- Image Generation
a) Multi-label classification
I’ve always wondered how you can carry out an [image] classification task whose number of labels can vary, i.e. multi-label classification (not to be confused with multi-class classification/multinomial classification whose sibling is binary classification).
It was not mentioned how the loss function works for multi-label classification in detail. But after googling, I found out that the labels should be a vector of multi-hot encoding. This means that each element must be applied to a sigmoid function in the final model output. The loss function, which is a function of the output and ground truth, is calculated using binary cross entropy to penalise each element independently.
b) Language Modelling
For this language modelling task, I like how ‘language model’ is defined (rephrased):
A language model is a model that learns to predict the next word of a sentence. In order to do so, you need to know quite a lot of about English and world knowledge.
This means you need to train the model with a lot of data. This is the part where the course introduces ULMFiT, a model that can be reused based on pre-training (transfer learning, in other words).
c) Tabular Data
This is my first encounter of using deep learning for tabular data wi with categorical variables! I didn’t know you could do that? Anyway, what we can do is we can create embeddings from categorical variables. I wouldn’t have thought about this if I hadn’t taken this course. A little googling away got me a post by Rachel Thomas on An Introduction to Deep Learning for Tabular Data on the use of such embeddings.
So then, the question is how do you combine (a) the vector of continuous variables and (b) the embeddings from categorical variables? The course didn’t mention anything about this but this StackOverflow post highlights 3 possible ways:
- 2 models – one for (a), one for (b). Ensemble them.
- 1 model, 1 input. This input is a concatenation between (a) and (b).
- 1 model, 2 inputs. The 2 inputs are (a) and (b). You concatenate these two in the model itself.
d) Collaborative Filtering
Collaborative filtering is when you’re tasked to predict how much a user is going to like a certain item (in this example, let’s say we’re using movie ratings). The course introduced the use embedding to solve this. This is my first encounter of collaborative filtering using deep learning (as if I had much experience with collaborative filtering in the first place)!
The goal is to create an embedding of size n for each user and item. To do that, we initialise each embedding vector randomly. Then, for every user rating for a movie, we compare it with the dot product of their respective embeddings, using MSE, for example. Then we perform gradient descent optimisation.
e) Image Generation
Here are some things I learnt:
- ‘Crappification’ for generating data, as and how we want them to be. I just like this term that was coined.
- Generative Adversarial Networks (GANs) hate momentum, so set it to 0.
- It’s hard to know how the model is performing by just looking at losses. One must personally see generated images from time to time (though the losses towards the end should roughly stay the same for both discriminator and generator).
- One way to improve the quality of the generated image is by including perceptual loss (AKA feature loss in fast.ai) in our loss function. Feature loss is computed by taking the values from a tensor somewhere in the middle of the network.
9. Model Interpretability

In one of the lessons, Jeremy Howard showed an activation heat-map of an image for an image classification task. This heat map displays the pixels that were ‘activated’. This kind of visualisation will help us understand what features or parts of an image resulted in the outputs of the model ????????.
10. Appendix: Jeremy Howard on Model Complexity & Regularisation

I transcribed this part of the course (Lesson 5) because the intuition is just so compelling ❤️. Here Jeremy first rounds up people who think that increasing model complexity is not the way to go, then reshapes their perspective, then brings them to L2 regularisation.
Oh and I was from Statistics so he caught me off guard there ????.
And so if any of you are unlucky enough to have been brainwashed by a background in statistics or psychology or econometrics or any of these kinds of courses, you’re gonna have to unlearn the idea that you need less parameters because what you instead need to realise this is you will fit this lie that you need less parameters because it’s a convenient fiction for the real truth which is you don’t want your function be too complex. And having less parameters is one way of making it less complex.
But what if you had a thousand parameters and 999 of those parameters were 1e-9. Or what if there was 0? If there’s 0 then they’re not really there. Or if they’re 1e-9, they’re hardly there.
So why can’t I have lots of parameters if lots of them are really small? And the answer is you can. So this thing, [where] counting the number of parameters is how we limit complexity, is actually extremely limiting. It’s a fiction that really has a lot of problems, right? And so, if in your head complexity is scored by how many parameters you have, you’re doing it all wrong. Score it properly.
So why do we care? Why would I want to use more parameters?
Because more parameters means more nonlinearities, more interactions, more curvy bits, right? And real life (of loss landscape) is full of curvy bits. Real life does not look like this [under fitted line]. But we don’t want them to be more curvy than necessary, or more interacting than necessary.
So therefore let’s use lots of parameters and then penalise complexity.
Okay so one way to penalise complexity is, as I kind of suggested before: Let’s sum up the value of your parameters. Now that doesn’t quite work because some parameters are positive and some are negative, right? So what if we sum up the square of the parameters.
And that’s actually a really good idea.
Let’s actually create a model and in the loss function we’re gonna add the sum of the square of the parameters. Now here’s a problem with that though. Maybe that number is way too big and it’s so big that the best loss is to set all of the parameters to 0. Now that would be no good. So actually we wanna make sure that doesn’t happen. So therefore let’s not just add the sum of the squares of the parameters to the model but let’s multiply that by some number that we choose. And that number that we choose in fast is called
wd.
You might also like to check out my article Intuitions on L1 and L2 Regularisation how I explain these two regularisation techniques using gradient descent here.
Conclusion
I really love this course. Here are some reasons why:
- They give intuitions and easy-to-understand explanations.
- They supplement their courses with great resources.
- They encourage you to apply deep learning to your respective domains to build things.
- They seem like they’re always up to date with interesting and novel publications, and incorporate them into the fastai library where appropriate.
- They also do a lot of research on deep learning (read: ULMFiT).
- They have built a community around the fastai library hence you will get support easily.
- Their tips and tricks are good for Kagglers and accuracy-driven modelling.
Looking forward to the next part of the course!
Bio: Raimi Bin Karim is an AI Engineer at AI Singapore
Original. Reposted with permission.
Related: