A 2019 Guide to Object Detection
Object detection has been applied widely in video surveillance, self-driving cars, and object/people tracking. In this piece, we’ll look at the basics of object detection and review some of the most commonly-used algorithms and a few brand new approaches, as well.

Object detection is a computer vision technique whose aim is to detect objects such as cars, buildings, and human beings, just to mention a few. The objects can generally be identified from either pictures or video feeds.
Object detection has been applied widely in video surveillance, self-driving cars, and object/people tracking. In this piece, we’ll look at the basics of object detection and review some of the most commonly-used algorithms and a few brand new approaches, as well.
How Object Detection Works
Object detection locates the presence of an object in an image and draws a bounding box around that object. This usually involves two processes; classifying and object’s type, and then drawing a box around that object. We’ve covered image classification before, so let’s now review some of the common model architectures used for object detection:
- R-CNN
- Fast R-CNN
- Faster R-CNN
- Mask R-CNN
- SSD (Single Shot MultiBox Defender)
- YOLO (You Only Look Once)
- Objects as Points
- Data Augmentation Strategies for Object Detection
R-CNN Model
This technique combines two main approaches: applying high-capacity convolutional neural networks to bottom-up region proposals so as to localize and segment objects; and supervised pre-training for auxiliary tasks.
Rich feature hierarchies for accurate object detection and semantic segmentation
Object detection performance, as measured on the canonical PASCAL VOC dataset, has plateaued in the last few years. The...
This is followed by domain-specific fine-tuning that yields a high-performance boost. The authors of this paper named the algorithm R-CNN (Regions with CNN features) because it combines regional proposals with convolutional neural networks.

This model takes an image and extracts about 2000 bottom-up region proposals. It then computes the features for each proposal using a large CNN. Thereafter, it classifies each region using class-specific linear Support Vector Machines (SVMs). This model achieves a mean average precision of 53.7% on PASCAL VOC 2010.
The object detection system in this model has three modules. The first one is responsible for generating category-independent regional proposals that define the set of candidate detectors available to the model’s detector. The second module is a large convolutional neural network responsible for extracting a fixed-length feature vector from each region. The third module consists of a class of support vector machines.

This model uses selective search to generate regional categories. Selective search groups regions that are similar based on color, texture, shape, and size. For feature extraction, the model uses a 4096-dimensional feature vector by applying the Caffe CNN implementation on each regional proposal. Forward propagating a 227 × 227 RGB image through five convolutional layers and two fully connected layers computes the features. The model explained in this paper achieves a 30% relative improvement over the previous results on PASCAL VOC 2012.
Some of the drawbacks of R-CNN are:
- Training is a multi-stage pipeline. Tuning a convolutional neural network on object proposals, fitting SVMs to the ConvNet features, and finally learning bounding box regressors.
- Training is expensive in space and time because of deep networks such as VGG16, which take up huge amounts of space.
- Object detection is slow because it performs a ConvNet forward pass for each object proposal.
Fast R-CNN
In this paper, a Fast Region-based Convolutional Network method (Fast R-CNN) for object detection is proposed.
Fast R-CNN
This paper proposes a Fast Region-based Convolutional Network method (Fast R-CNN) for object detection. Fast R-CNN...
It’s implemented in Python and in C++ using Caffe. This model achieves a mean average precision of 66% on PASCAL VOC 2012, versus 62% for R-CNN.

In comparison to the R-CNN, Fast R-CNN has a higher mean average precision, single stage training, training that updates all network layers, and disk storage isn’t required for feature caching.
In its architecture, a Fast R-CNN, takes an image as input as well as a set of object proposals. It then processes the image with convolutional and max-pooling layers to produce a convolutional feature map. A fixed-layer feature vector is then extracted from each feature map by a region of interest pooling layer for each region proposal.
The feature vectors are then fed to fully connected layers. These then branch into two output layers. One produces softmax probability estimates over several object classes, while the other produces four real-value numbers for each of the object classes. These 4 numbers represent the position of the bounding box for each of the objects.
Faster R-CNN
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
State-of-the-art object detection networks depend on region proposal algorithms to hypothesize object locations...
This paper proposes a training mechanism that alternates fine-tuning for regional proposal tasks and fine-tuning for object detection.

The Faster R-CNN model is comprised of two modules: a deep convolutional network responsible for proposing the regions, and a Fast R-CNN detector that uses the regions. The Region Proposal Network takes an image as input and generates an output of rectangular object proposals. Each of the rectangles has an objectness score.
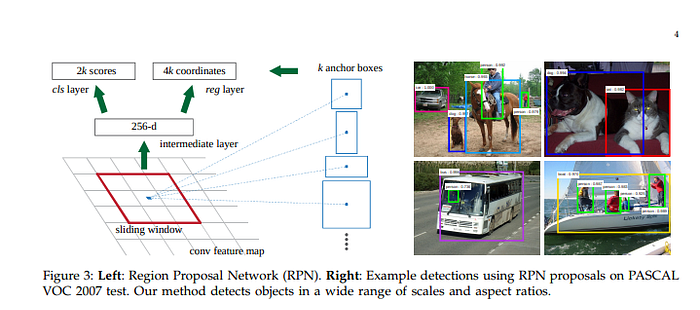
Mask R-CNN
Mask R-CNN
We present a conceptually simple, flexible, and general framework for object instance segmentation. Our approach...
The model presented in this paper is an extension of the Faster R-CNN architecture described above. It also allows for the estimation of human poses.

In this model, objects are classified and localized using a bounding box and semantic segmentation that classifies each pixel into a set of categories. This model extends Faster R-CNN by adding the prediction of segmentation masks on each Region of Interest. The Mask R-CNN produces two outputs; a class label and a bounding box.
SSD: Single Shot MultiBox Detector
SSD: Single Shot MultiBox Detector
We present a method for detecting objects in images using a single deep neural network. Our approach, named SSD...
This paper presents a model to predict objects in images using a single deep neural network. The network generates scores for the presence of each object category using small convolutional filters applied to feature maps.
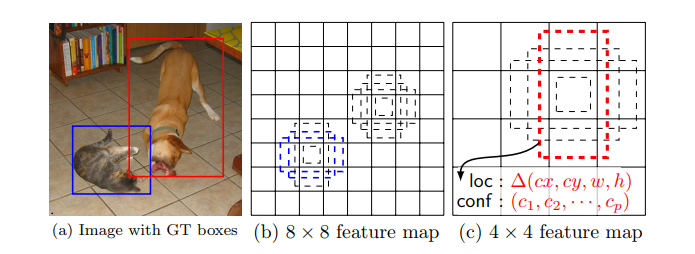
This approach uses a feed-forward convolutional neural network that produces a collection of bounding boxes and scores for the presence of certain objects. Convolutional feature layers are added to allow for feature detection at multiple scales. In this model, each feature map cell is linked to a set of default bounding boxes. The figure below shows how SSD512 performs on animals, vehicles, and furniture.

You Only Look Once (YOLO)
This paper proposes a single neural network to predict bounding boxes and class probabilities from an image in a single evaluation.
You Only Look Once: Unified, Real-Time Object Detection
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform...
The YOLO models process 45 frames per second in real-time. YOLO views image detection as a regression problem, which makes its pipeline quite simple. It’s extremely fast because of this simple pipeline.
It can process a streaming video in real-time with a latency of less than 25 seconds. During the training process, YOLO sees the entire image and is, therefore, able to include the context in object detection.
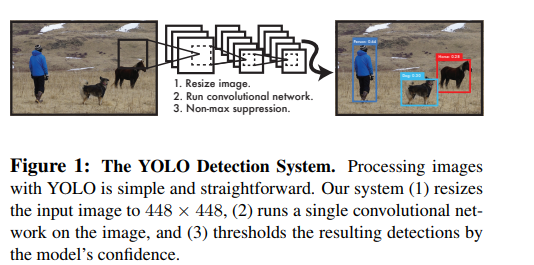
In YOLO, each bounding box is predicted by features from the entire image. Each bounding box has 5 predictions; x, y, w, h, and confidence. (x, y) represents the center of the bounding box relative to the bounds of the grid cell. w and h are the predicted width and height of the whole image.
This model is implemented as a convolutional neural network and evaluated on the PASCAL VOC detection dataset. The convolutional layers of the network are responsible for extracting the features, while the fully connected layers predict the coordinates and output probabilities.

The network architecture for this model is inspired by the GoogLeNet model for image classification. The network has 24 convolutional layers and 2 fully-connected layers. The main challenges of this model are that it can only predict one class, and it doesn’t perform well on small objects such as birds.

This model achieves a mean average precision of 52.7%, it is, however, able to go up to 63.4%.

Objects as Points
This paper proposes modeling an object as a single point. It uses key point estimation to find center points and regresses to all other object properties.
Objects as Points
Detection identifies objects as axis-aligned boxes in an image. Most successful object detectors enumerate a nearly...
These properties include 3D location, pose orientation, and size. It uses CenterNet, a center point based approach that’s faster and more accurate compared to other bounding box detectors.

Properties such as object size and pose are regressed from features of the image at the center location. In this model, an image is fed to a convolutional neural network which generates a heatmap. The maximum values in these heatmaps represent the centers of the objects in the image. In order to estimate human poses, the model examines 2D joint locations and regresses them at the center point location.
This model achieves 45.1% COCO average precision at 1.4 frames per second. The figure below shows how this compared with the results obtained in other research papers.

Learning Data Augmentation Strategies for Object Detection
Data augmentation involves the process of creating new image data by manipulating the original image by, for example, rotating and resizing.
Learning Data Augmentation Strategies for Object Detection
Data augmentation is a critical component of training deep learning models. Although data augmentation has been shown...
While this isn’t itself a model architecture, this paper proposes the creation of transformations that can be applied to object detection datasets that can be transferred to other objection detection datasets. The transformations are usually applied at training time.

In this model, an augmentation policy is defined as a set of n policies that are selected at random during the training process. Some of the operations that have been applied in this model include distorting color channels, distorting the images geometrically, and distorting only the pixel content found in the bounding box annotations.
Experimentation on the COCO dataset has shown that optimizing a data augmentation policy is able to improve the accuracy of detection by more than +2.3 mean average precision. This allows a single inference model to achieve an accuracy of 50.7 mean average precision.
Conclusion
We should now be up to speed on some of the most common—and a couple of recent—techniques for performing object detection in a variety of contexts.
The papers/abstracts mentioned and linked to above also contain links to their code implementations. We’d be happy to see the kind of results you obtain after testing them.
Let’s not limit ourselves. Object detection can also live inside your smartphone. Learn how Fritz can teach mobile apps to see, hear, sense, and think.
Bio: Derrick Mwiti is a data analyst, a writer, and a mentor. He is driven by delivering great results in every task, and is a mentor at Lapid Leaders Africa.
Original. Reposted with permission.
Related:
- Object Detection with Luminoth
- An Overview of Human Pose Estimation with Deep Learning
- Large-Scale Evolution of Image Classifiers