Easily Deploy Deep Learning Models in Production
Getting trained neural networks to be deployed in applications and services can pose challenges for infrastructure managers. Challenges like multiple frameworks, underutilized infrastructure and lack of standard implementations can even cause AI projects to fail. This blog explores how to navigate these challenges.
By Shankar Chandrasekaran, NVIDIA Product Marketing Sponsored Post.
The idea of a system that can learn from data, identify patterns and make decisions with minimal human intervention is exciting. Deep learning, a type of machine learning that uses neural networks is quickly becoming an effective tool to solve many different computing problems from object classification to recommendation systems. However, getting trained neural networks to be deployed in applications and services can pose challenges for infrastructure managers. Challenges like multiple frameworks, underutilized infrastructure and lack of standard implementations can even cause AI projects to fail. In this blog, we will explore how to navigate these challenges and deploy deep learning models in production in data center or cloud.
Join our upcoming webinar on TensorRT Inference Server
Generally speaking, we, application developers, work with both data scientists and IT to bring AI models to production. Data scientists use specific frameworks to train machine/deep learning models for various use cases. We integrate the trained model into the application we are developing to solve the business problem. IT operations team then runs and manages the deployed application in the data center or cloud.

There are 2 major challenges in bringing deep learning models to production:
- We need to support multiple different frameworks and models leading to development complexity, and there is the workflow issue. Data scientists develop new models based on new algorithms and data and we need to continuously update production.
- If we use NVIDIA GPUs to deliver game-changing levels of inference performance, there are a couple of things to keep in mind. First, GPUs are powerful compute resources, and running a single model per GPU may be inefficient. Running multiple models on a single GPU will not automatically run them concurrently to maximize GPU utilization.
Then, what can we do? Let’s look at how we can use an application like NVIDIA’s TensorRT Inference Server to address these challenges. You can download TensorRT Inference Server as a container from NVIDIA NGC registry or as open-source code from GitHub.
TensorRT Inference Server: Making Deployment Easier
TensorRT Inference server eases deployment of trained neural networks through a combination of features:
Supporting Multiple Framework Models: We can address the first challenge by using TensorRT Inference Server’s model repository, which is a storage location where models developed from any framework such as TensorFlow, TensorRT, ONNX, PyTorch, Caffe, Chainer, MXNet or even custom framework can be stored. TensorRT Inference Server can deploy models built in all of these frameworks, and when the inference server container starts on a GPU or CPU server, it loads all the models from the repository into memory. The application then uses an API to call the inference server to run inference on a model. If we have a lot of models that cannot fit in memory, then we can break the single repository into multiple repositories and run different instances of TensorRT Inference Server, each pointing to a different repository. We can easily update, add or delete models by changing the model repository even while the inference server and our application are running.
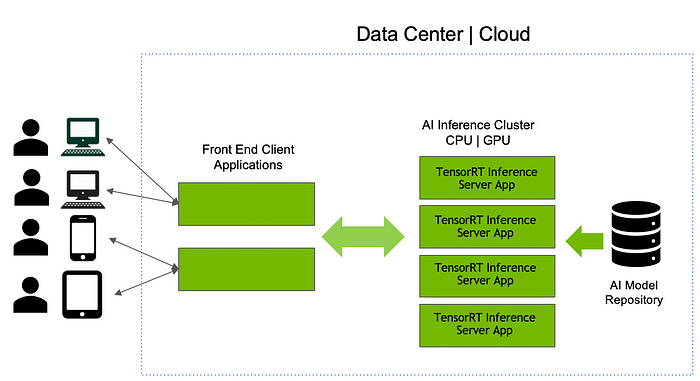
Maximizing GPU Utilization: Now that we have successfully run the application and inference server, we can address the second challenge. GPU utilization is often a key performance indicator (KPI) for infrastructure managers. TensorRT Inference Server can schedule multiple models (same or different) on GPUs concurrently; it automatically maximizes GPU utilization. So, as a developer, we do not have to take special steps and IT operations requirements are also met. Rather than deploying one model per server, IT operations will run the same TensorRT Inference Server container on all servers. Since it supports multiple models, it can keep the GPU utilized and servers more balanced than a single model per server scenario. Here is a demo video that explains the server load balancing and utilization.
Enabling Real-Time and Batch Inference: There are two types of inference. If our application needs to respond to the user in real-time, then inference needs to complete in real-time too. Because latency is a concern, the request cannot be put in a queue and batched with other requests. On the other hand, if there is no real-time requirement, the request can be batched with other requests to increase GPU utilization and throughput.
When we develop our application, it is good to understand the real-time requirements. TensorRT Inference Server has a parameter to set latency threshold for real-time applications, and also supports dynamic batching that can be set to a non-zero number to implement batched requests. We must work closely with the IT operations to ensure these parameters are correctly set.
Inference on CPU, GPU and heterogeneous cluster: In many organizations, GPUs are used mainly for training. Inference is done on regular CPU servers. However, running inference on GPUs brings significant speedups and we need the flexibility to run our models on any processor.
TensorRT Inference Server supports both GPU and CPU inference.
Let us explore how to migrate from CPU to GPU inference.
- Our current cluster is a set of CPU only servers which all run the TensorRT Inference Server application.
- We introduce GPU servers to the cluster, run TensorRT Inference Server software on these servers.
- We add the GPU accelerated models to the model repository.
- Using the configuration file we instruct the TensorRT Inference Server on these servers to use GPUs for inference
- We can either retire the CPU only servers from the cluster or use both in a heterogeneous mode.
- There is no code change needed to the application calling the TensorRT Inference Server.
Integrating with DevOps Infrastructure: The last point is more pertinent to our IT teams. Does your organization follow DevOps practice? For those not familiar with the term, it is a set of processes and practices followed to shorten the overall software development and deployment cycle. Organizations practicing DevOps tend to use containers to package their applications for deployment. TensorRT Inference Server is a Docker container that IT can use Kubernetes to manage and scale. They can also make the inference server a part of Kubeflow pipelines for an end-to-end AI workflow. The GPU/CPU utilization metrics from the inference server tell Kubernetes when to spin up a new instance on a new server to scale.
It’s easy to integrate TensorRT Inference Server into our application code by setting the model configuration file and integrating a client library.
Deploying trained neural networks can pose challenges, but in this blog we’ve walked through some tips to make those deployments easier. We would love to hear from you in the comments below, on what challenges you faced while running inference in production and how you solved them.
Want to learn more? Be sure to join our upcoming webinar on TensorRT Inference Server.
You can also
- download TensorRT Inference Server as a container from NVIDIA NGC registry
- or as open-source code from GitHub.