 Advice on building a machine learning career and reading research papers by Prof. Andrew Ng
Advice on building a machine learning career and reading research papers by Prof. Andrew Ng
 Advice on building a machine learning career and reading research papers by Prof. Andrew Ng
Advice on building a machine learning career and reading research papers by Prof. Andrew NgThis blog summarizes the career advice/reading research papers lecture in the CS230 Deep learning course by Stanford University on YouTube, and includes advice from Andrew Ng on how to read research papers.
By Mohamed Ali Habib, Computer Science Graduate
Introduction:
Since you’re reading this blog, you probably already know who is Andrew Ng, one of the pioneers in the field, and you maybe interested in his advice on how to build a career in Machine Learning.
This blog summarizes the career advice/reading research papers lecture in the CS230 Deep learning course by Stanford University on YouTube.
I would recommend watching the lecture for more details, it’s pretty informative. However, I thought that you might find this helpful either you watch it or not. Therefore, I tried to outline those recommendations here.
TL;DR: Skip to the key takeaways section.
Andrew shared two major recommendations, specifically:
- Reading research papers: efficient techniques ,that he uses, to read research papers when trying to master a new topic in deep learning.
- Advice for navigating a career in machine learning.
Reading Research Papers:
How can you learn efficiently and relatively quickly through reading research papers. So, what you should do in case you want to learn from the academic literature whether you want to learn to build a machine learning system/project of interest, or just to stay on top of things, gain more knowledge and evolve as a deep learning person.
Here comes the list:
- Compile a list of papers: try to create a list of research papers, mediumposts and whatever text or learning resource you have.
- Skip around the list: basically, you should read research papers in a parallel fashion; meaning try to tackle more than one paper at a time. Concretely, try to quickly skim and understand each of these paper and do not read it all, maybe you read 10–20% of each one and probably that will be enough to give you a high-level understanding of the paper in hand. After that, you may decide to eliminate some of these papers or just go over one or two them and read them fully.
He mentioned also that if you read:
5–20 papers (in a field of choice, say speech recognition) => it may be probably enough knowledge for you to implement a speech recognition system, but maybe not enough to research or be at the cutting-edge.
50–100 papers => you probably have a very good understanding of the domain application (speech recognition).
How do you read one paper?
Don’t start reading the paper from the first to the last word. Instead, take multiple passes through the paper, here’s how to do it:
- Read the Title, the abstract and the figures: by reading the title, abstract, the key network architecture figure, and maybe the experiments section, you will be able to get a general sense of the concepts in the paper. In deep learning, there are a lot of research papers where the entire paper is summarized in one or two figures without the need to go hardly through the text.
- Read the introduction + conclusions + figures + skim the rest: the introduction, the conclusions and the abstract are the places where the author(s) try to summarize their work carefully to clarify for the reviewer why their paper should be accepted for publication.
Also, skim the related work section (if possible), this section aims to highlight work done by others that somehow ties in with the author(s) work. Hence, it may be useful to read it but if you’re not familiar with the literature, it is sometimes very hard to understand. - Read the paper but skip the math.
- Read the whole thing but skip the parts that don’t make sense: great research means we’re publishing things at the boundaries of our knowledge and understanding.
He also explained that when you read papers (even the most influential ones), you’ll find maybe some parts that is much less used or it doesn’t make sense. Consequently, it’s fine if you read a paper and some of it doesn’t make sense (it’s not unusual), it’s okay to skim it initially. Unless, you’re trying to master it, then spend more time.
When you read a paper, try to answer the following questions:
- What did the author(s) try to accomplish?
- What were the key elements of the approach?
- What can you use yourself?
- What other references do you want to follow?
If you can answer these questions, hopefully, that will reflect that you have a good understanding of the paper.
It turns out as you read more papers, with practice you get faster. Because, a lot of authors use common formats when writing papers.
For example, this is a common format that authors use to describe the network architecture, especially in computer vision:
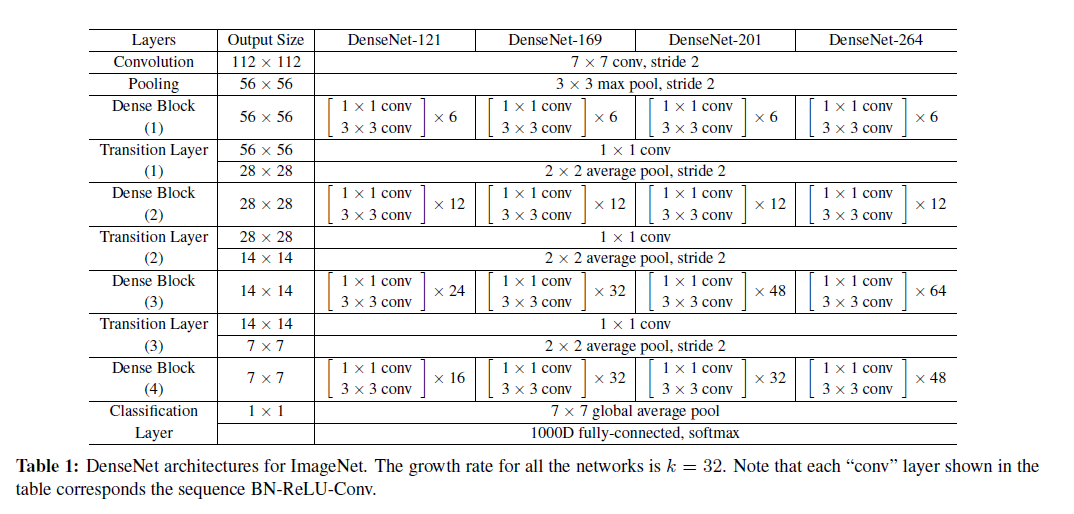
How much time it takes to understand a paper?
It’s not unusual for people that are relatively new to machine learning to need maybe an hour to understand a relatively easy paper. But, sometimes you may stumble across papers that takes 3 hours or even longer to really understand it.
Sources of papers:
There are a lot of great resources online. For example, blog posts listing the most important papers in speech recognition would be very useful if you’re new to this domain.
A lot of people try to keep up with the state-of-the-art of deep learning as it evolves rapidly. And so, here’s where you should go:
- Twitter: surprisingly, Twitter is becoming an important place for researchers to find out about new things.
- ML subreddit.
- Important Machine Learning Conferences: NeurIPS/ICML/ICLR.
- Friends: find a community or a group of friends ,interested in the field, that shares interesting research papers.
To understand the math in papers more deeply:
Try to rederive it from scratch. Although, it takes some time but it’s a very good practice.
To practice Coding:
- Download open-source code (if you can find it) and run it.
- Reimplement from scratch: if you can do this, that’s a strong sign that you have really understood the algorithm in hand.
To keep getting better:
The most important thing to keep on learning and getting better is to learn more steadily rather than having a focus-intensive activity. It’s better to read two papers a week for the next year than cramming everything over a short period of time.
Advice for navigating a career in machine learning:
Whether your goal is to get a Job (big company, startup and faculty positions) or do more advanced graduate studies (maybe join a PhD program)
Just focus on doing important work and consider your job as a tactic and a chance to do useful work.
What do recruiters look for?
- Machine Learning Skills.
- Meaningful work: projects which shows that you can do the work.
A very common pattern for successful machine learning engineers ,strong job candidates, is to develop a T-shaped knowledge base. Meaning to have a broad understanding of many different topics in AI and very deep understanding in at least one area.
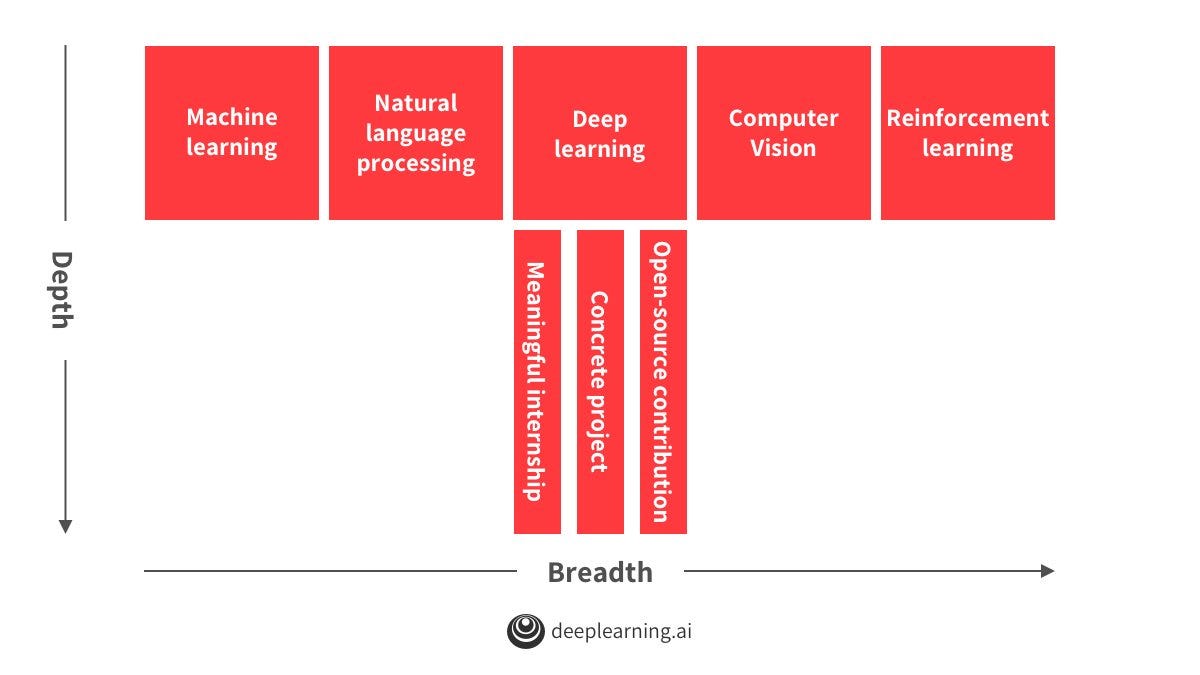
To build the horizontal piece:
A very efficient way to build foundational skills in these domains is through courses and reading research papers.
To build the vertical piece:
You can build it by doing related projects, open-source contributions, research and internships.
Selecting a job:
If you want to keep learning new things, here are the things that affect your success:
- Whether you are working with great people/projects: being surrounded by hard-working people will influence you.
- Focus on knowing about and evaluating the team that you will be working with (the 10–30 people that you will interact with the most) in addition to the manager.
- Do not focus on “brand”: the brand of the company is not that much correlated to what your personal experience would be like.
So if you get a job offer, ask about which team you will be working with and don’t accept an offer that says “join us, and we’ll assign to a team later” because you might end up with a team that work on things that don’t interest you; which doesn’t help to evolve efficiently.
On the other hand, if you can track down a good team (even in an unknown company) and join them, you can actually learn a lot.
General Advice:
- Learn the most: tend to choose things to work on that allow you to learn the most.
- Do important work: work on worthy projects that moves the world forward.
- Try to take machine learning to traditional industries: we’ve transformed a lot in the tech industry but I think one of the most exciting work to be done may be in traditional industries (outside the tech industry) because you can create much more value there.
Key Takeaways:
I tried to summarize the key takeaways of Andrew’s advice in the following list:
- Develop a habit of reading research papers: maybe 2 papers a week as a start.
- Read efficiently: compile a list of papers, read more than one paper at a time and take multiple passes through each one.
- When reading a paper: start by reading the title/abstract/figures (especially)/introduction/conclusions.
- When trying to understand an algorithm: try to rederive the math and practice coding by reimplementing it.
- Try to stay on top of things: by checking papers in ML conferences and other online resources.
- Build a T-shaped knowledge base in AI.
- Try to join a good team (in a big company or a startup) that will help you grow efficiently.
- Work on useful projects that helps you learn the most and moves the world forward.
- Try to take machine learning to other industries: healthcare, astronomy, climate change, etc.
Conclusion:
I hope you find this blog fruitful and I wish you good luck with your machine learning career.
If you liked the blog, clap for it ;)
And, let me know if you have any questions down in the comments.
Cheers!
Bio: Mohamed Ali Habib is a computer science graduate. He is interested in machine learning, deep learning and data science.
Original. Reposted with permission.
Related:
- 7 Useful Suggestions from Andrew Ng “Machine Learning Yearning”
- 6 Key Concepts in Andrew Ng’s “Machine Learning Yearning”
- If you’re a developer transitioning into data science, here are your best resources