Introducing IceCAPS: Microsoft’s Framework for Advanced Conversation Modeling
The new open source framework that brings multi-task learning to conversational agents.

Neural conversation systems and disciplines such as natural language processing(NLP) have seen significant advancements over the last few years. However, most of the current NLP stacks are designed for simple dialogs based on one or two sentences. Structuring more sophisticated conversations that factor in aspects such as personalities or context remains an open challenge. Recently, Microsoft Research unveiled IceCAPS, an open source framework for advanced conversation modeling.
Modeling conversations is different from effectively processing natural language sentences. We typically use different tone and language depending on the context of a conversation. Similarly, we exhibit different personalities and emotions depending on the setting of the dialog. More importantly, it is important to realize that effective conversations are not based on a single task such as understanding a sentence and rather on a combination of multiple, cohesive tasks. If we compare those dynamics with the behavior of the current generation of chatbots, we can quickly realize how much work is still needed in conversational modeling.
Multi-Task Learning
In the context of artificial intelligence(AI), modeling conversations is not a matter of mastering a new task but multiple. When we engage in a conversation, the same question can be answered in infinite ways using a combination of contextual, syntactical and semantical structures. We are able to do that because our brains combine the richness of language with a canvas of possible answers given a specific context. Think about it like a painters palette. Painters don’t go to work using a small group of structured colors. Instead, they mix paints of different colors that allow them to create a palette that offers a glimpse of the possibilities in front of them. Using the same section of the palette in two consecutive attempts is likely to result on slightly different colors with enough of a variation to make the painting interesting. The AI paradigm that tries to mimics this multi-faceted approach towards a given goal is known as multi-task learning.
Conceptually, multi-task learning is a subfield of machine learning that focuses on models that exploit commonalities between different task in order to achieve a common goal. More specifically, multi-task learning shares subset of parameters among multiple tasks so those tasks can make use of shared feature representations. For example, this technique has been used in conversational modeling to combine general conversational data with unpaired utterances; by pairing a conversational model with an autoencoder that shares its decoder, one can use the unpaired data to personalize the conversational model.

Multi-task learning is a key element of the next generation of conversational models and the foundation of Microsoft’s IceCAPS effort.
IceCAPS
The Intelligent Conversation Engine: Code and Pre-trained Systems, or Microsoft Icecaps is an open source toolkit that allow researcher to model advanced conversational interactions. By more advanced, IceCAPs focuses on leveraging multi-task learning to design conversational agents that can master multiple language capabilities. The current implementation of IceCAPs is based on TensorFlow but its principles can be abstracted to other deep learning frameworks.
The IceCAPS architecture is based on two fundamental principles: component chaining and multi-task learning. The idea of component chaining is to abstract sequence-to-sequence models as chains of sequence encoders and sequence decoders. IceCAPs implements various encoders and decoders, which can be chained together to form a single, end-to-end functional model. This chaining paradigm allows users to flexibly combine components and create topologies including multiple models with shared components.
Multi-task learning is another foundational component of the IceCAPS architecture. The idea of conversational agents that can master multiple tasks sounds ideal but what does it mean exactly? In the case of IceCAPS, the framework allows users to build arrays of models with arbitrary sharing of components, and place them in a multi-task learning environment. Users can construct arbitrary multi-task training schedules, assigning different tasks or balances among tasks per training step. One particular use case of multi-task learning is to combine generate data with conversational utterances.
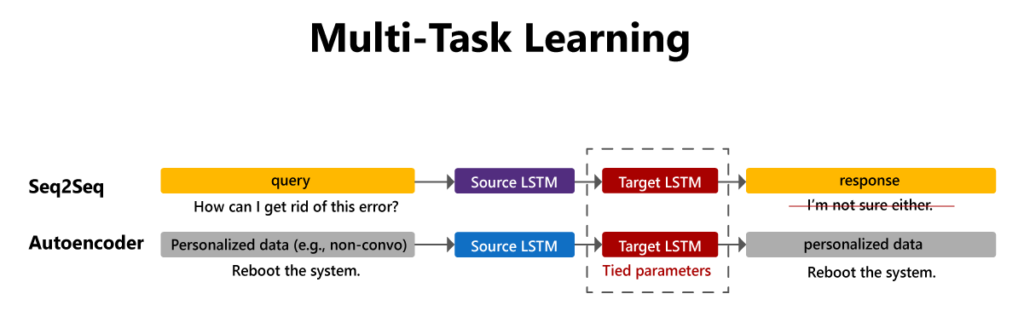
The multi-task learning capabilities of IceCAPs are implemented via SpaceFusion, , a specialized multi-task learning paradigm originally designed to jointly optimize for diversity and relevance of generated responses. Following our painter’s palette analogy, SpaceFusion combines fragments of human dialogs to build conversations in the same spontaneous way that painters use combinations of colors in a palette to achieve a specific impact. To see SpaceFusion in action, let’s think about a natural language processing(NLP) scenario that has been tackled using two different approaches: sequence-to-sequence(S2S) and variational autoencoder(AE) models. Each type of model produces a different latent space that is completely disjointed. A technique like SpaceFusion generates a heterogenous distribution for the features generated by both the S2S and the AE models.

IceCAPS provide many built-in modules that abstract the most common architecture of conversational applications. Some examples of these modules include including transformers, LSTM-based seq2seq models with attention, n-gram convolutional language models, and deep convolutional networks for baseline image grounding. IceCAPS combines those built-in modules into a series of innovative conversational capabilities such as personality or knowledge grounding.
Personality Grounding
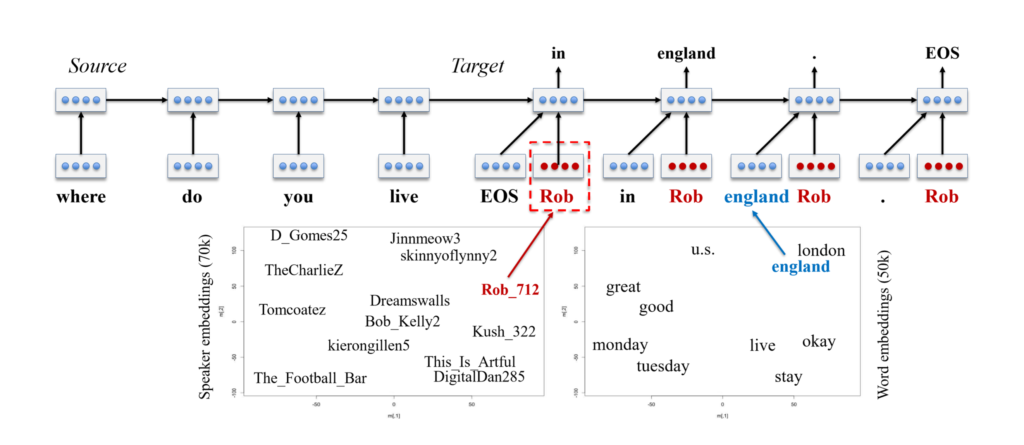
Any intelligent conversational AI agents must be able to adapt different personas and styles in order to better fit a given context. Icecaps allows researchers and developers to train multi-persona conversation systems on multi-speaker data using personality embeddings. Personality embeddings work similarly to word embeddings; just as we learn an embedding for each word to describe how words relate to each other within a latent word space, we can learn an embedding per speaker from a multi-speaker dataset to describe a latent personality space. By combining a word embedding space with a persona embedding space, personalized sequence-to-sequence models enable personalized response generation.
Knowledge Grounding
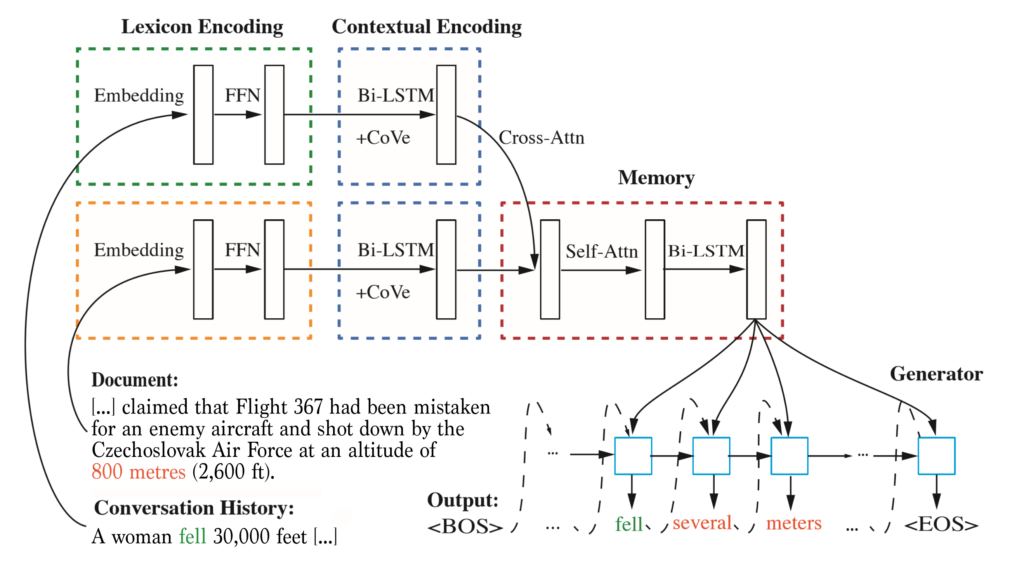
One of the ultimate goals of conversational agents is that they are able to master the knowledge present in encyclopedic sources such as Wikipedia. However that goal often becomes challenging as those data sources are not structured in conversational formats that can be used to train NLP agents. IceCAPS addresses this by implementing an approach to knowledge-grounded conversation that combines machine reading comprehension and response generation modules. The model uses attention to isolate content from the knowledge source relevant to the context, allowing the model to produce more informed responses. The knowledge-grounding approach can be used to extract pertinent information from an external knowledge base for shaping generated responses.
Building sophisticated conversational systems with Microsoft IceCAPS is relatively straightforward. The framework provides an intuitive programming model to assemble complex chains of components that deliver a specific language capability. IceCAPS builds on top of TensorFlow’ architecture to abstract key capabilities of advanced conversational agents.
Microsoft IceCAPS is an interesting approach to streamline the implementation of conversational agents that can master multiple tasks at one. The current release contributes key conversation modeling features to the open-source community, including personalization, knowledge grounding, diverse response modeling and generation, and more generally a multi-task architecture for inducing biases in conversational agents. By leveraging multi-task learning, IceCAPS provides a strong foundation to build NLP agents that better resemble human conversations.
Bio: Jesus Rodriguez is a technology expert, executive investor, and startup advisor. A software scientist by background, Jesus is an internationally recognized speaker and author with contributions that include hundreds of articles and presentations at industry conferences.
Original. Reposted with permission.
Related:
- What is Machine Behavior?
- Beyond Neurons: Five Cognitive Functions of the Human Brain that we are Trying to Recreate with Artificial Intelligence
- How DeepMind and Waymo are Using Evolutionary Competition to Train Self-Driving Vehicles