A Single Function to Streamline Image Classification with Keras
We show, step-by-step, how to construct a single, generalized, utility function to pull images automatically from a directory and train a convolutional neural net model.
Introduction
Plenty has been written about deep learning frameworks such as Keras and PyTorch, and how powerful yet simple to use they are for constructing and playing with wonderful deep learning models.
There are so many tutorials/articles already written about model architecture and optimizers— the concept of convolution, max pooling, optimizers such as ADAM or RMSprop.
What if, all you wanted, is a single function to pull automatically images from a specified directory on your disk, and give you back a fully trained neural net model, ready to be used for prediction?

Therefore, in this article, we focus on how to use a couple of utility methods from the Keras (TensorFlow) API to streamline the training of such models (specifically for a classification task) with a proper data pre-processing.
Basically, we want to,
- grab some data
- put them inside a directory/folder arranged by classes
- train a neural net model with minimum code/fuss
In the end, we aim to write a single utility function, which can take just the name of your folder where training images are stored, and give you back a fully trained CNN model.
The dataset
We use a dataset consisting of 4000+ images of flowers for this demo. The dataset can be downloaded from the Kaggle website here.
The data collection is based on the data Flickr, Google images, Yandex images. The pictures are divided into five classes,
- daisy,
- tulip,
- rose,
- sunflower,
- dandelion.
For each class, there are about 800 photos. Photos are not high resolution, about 320 x 240 pixels. Photos are not reduced to a single size, they have different proportions.
However, they come organized neatly in five directories named with the corresponding class labels. We can take advantage of this organization and apply the Keras methods to streamline the training of our convolutional network.
The code repo
The full Jupyter notebook is here in my Github repo. Feel free to fork and extend it, and give it a star if you like it.
We will use bits and pieces of the code in this article to show the important parts for illustration.
Should you use a GPU?
It is recommended to run this script on a GPU (with TensorFlow-GPU), as we will build a CNN with five convolutional layers and consequently, the training process with thousands of images can be computationally intensive and slow if you are not using some sort of GPU.
For the Flowers dataset, a single epoch took ~ 1 minute on my modest laptop with NVidia GTX 1060 Ti GPU (6 GB Video RAM), Core i-7 8770 CPU, 16 GB DDR4 RAM.
Alternatively, you can take advantage of Google Colab, but loading and pre-processing the datasets can be a bit of hassle there.
Data pre-processing
Housekeeping and showing images
Note that the first part of the data pre-processing section of the notebook code is not essential for the training of the neural net. This set of code is just for illustration purpose and showing a few training images as an example.
On my laptop, the data is stored in a folder one level above my Notebooks folder. Here is the organization,

With some basic Python code, we can traverse the sub-directories, count the images, and show a sample of them.
Some daisy pictures,

And some beautiful roses,

Note, the pictures vary in their sizes and aspect ratios.
Building the ImageDataGenerator object
This is where the actual magic happens.
The official description of the ImageDataGenerator class says "Generate batches of tensor image data with real-time data augmentation. The data will be looped over (in batches)."
Basically, it can be used to augment image data with a lot of built-in pre-processing such as scaling, shifting, rotation, noise, whitening, etc. Right now, we just use the rescale attribute to scale the image tensor values between 0 and 1.
Here is a useful article on this aspect of the class.
Image Augmentation using Keras ImageDataGenerator
A blog for implementation of our custom generator in combination with Keras’ ImageDataGenerator to perform various…
But the real utility of this class for the current demonstration is the super useful method flow_from_directory which can pull image files one after another from the specified directory.
Note that, this directory just has to be the top-level directory where all the sub-directories of individual classes can be stored separately. The flow_from_directory method automatically scans through all the sub-directories and sources the images along with their appropriate labels.
We can specify the class names (as we did here with the classes argument) but this is optional. However, we will later see, how this can be useful for selective training from a large trove of data.
Another useful argument is the target_size, which lets us resize the source images to a uniform size of 200 x 200, no matter the original size of the image. That is some cool image-processing right there with a simple function argument.
We also specify the batch size. If you leave batch_size unspecified, by default, it will be set to 32.
We choose the class_mode as categorical as we are doing a multi-class classification here.
When you run this code, the Keras function scans through the top-level directory, finds all the image files, and automatically labels them with the proper class (based on the sub-directory they were in).
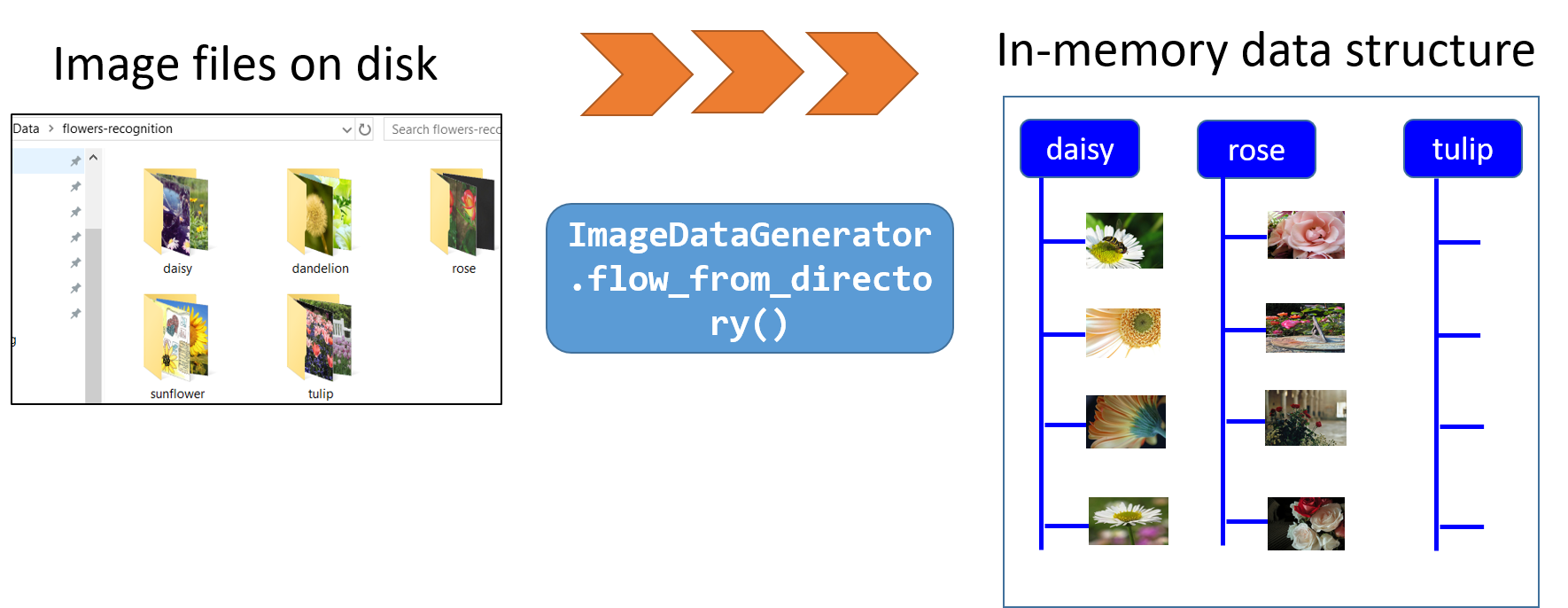
Isn’t that cool?
But wait, there is more. This is a Python generator object and that means it will be used to ‘yield’ the data one by one during the training. This significantly reduces the problem of dealing with a very large dataset, whose contents cannot be fitted into memory at one go. Look at this article to understand it better,
Python’s Generator Expressions: Fitting Large Datasets into Memory
Generator Expressions are an interesting feature in Python, which allows us to create lazily generated iterable objects…
Building the conv net model
As promised, we will not spend time or energy on analyzing the code behind the CNN model. In brief, it consists of five convolutional layers/max-pooling layers and 128 neurons at the end followed by a 5 neuron output layer with a softmax activation for the multi-class classification.
We use RMSprop with an initial learning rate of 0.001.
Here is the code again. Feel free to experiment with the network architecture and the optimizer.

Training with the ‘fit_generator’ method
We discussed before what cool things the train_generator object does with the flow_from_directory method and with its arguments.
Now, we utilize this object in the fit_generator method of the CNN model, defined above.
Note the steps_per_epoch argument to fit_generator. Since train_generator is a generic Python generator, it never stops and therefore the fit_generator will not know where a particular epoch is ending and the next one is starting. We have to let it know the steps in a single epoch. This is, in most cases, the length of the total training sample divided by the batch size.
In the previous section, we found out the total sample size as total_sample. Therefore, in this particular case, the steps_per_epoch is set to int(total_sample/batch_size) which is 34. Therefore, you will see 34 steps per epoch in the training log below.
Partial training log…

We can check the accuracy/loss with the usual plot code.
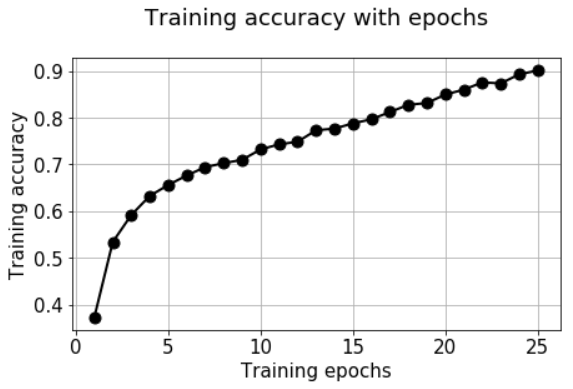
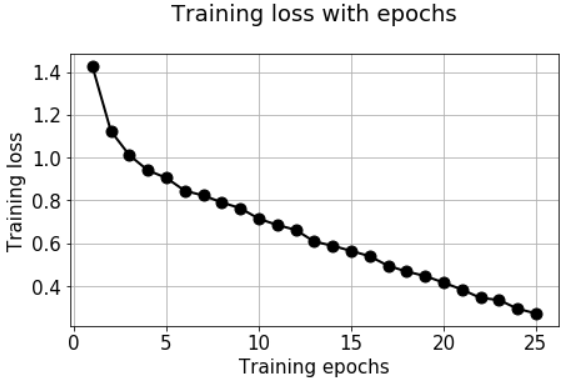
OK. What have we accomlished so far?
We have been able to utilize Keras ImageDataGenerator and fit_generator methods to pull images automatically from a single directory, label them, resize and scale them, and flow them one by one (in batches) for training a neural network.
Can we encapsulate all of these in a single function?
Encapsulate all of these in a single function?
One of the central goals of making useful software/computing systems is abstraction i.e. hide the gory details of internal computation and data manipulation and present a simple and intuitive working interface/ API to the user.
Just as a practice towards that goal, we can try to encapsulate the process we followed above, in a single function. Here is the idea,
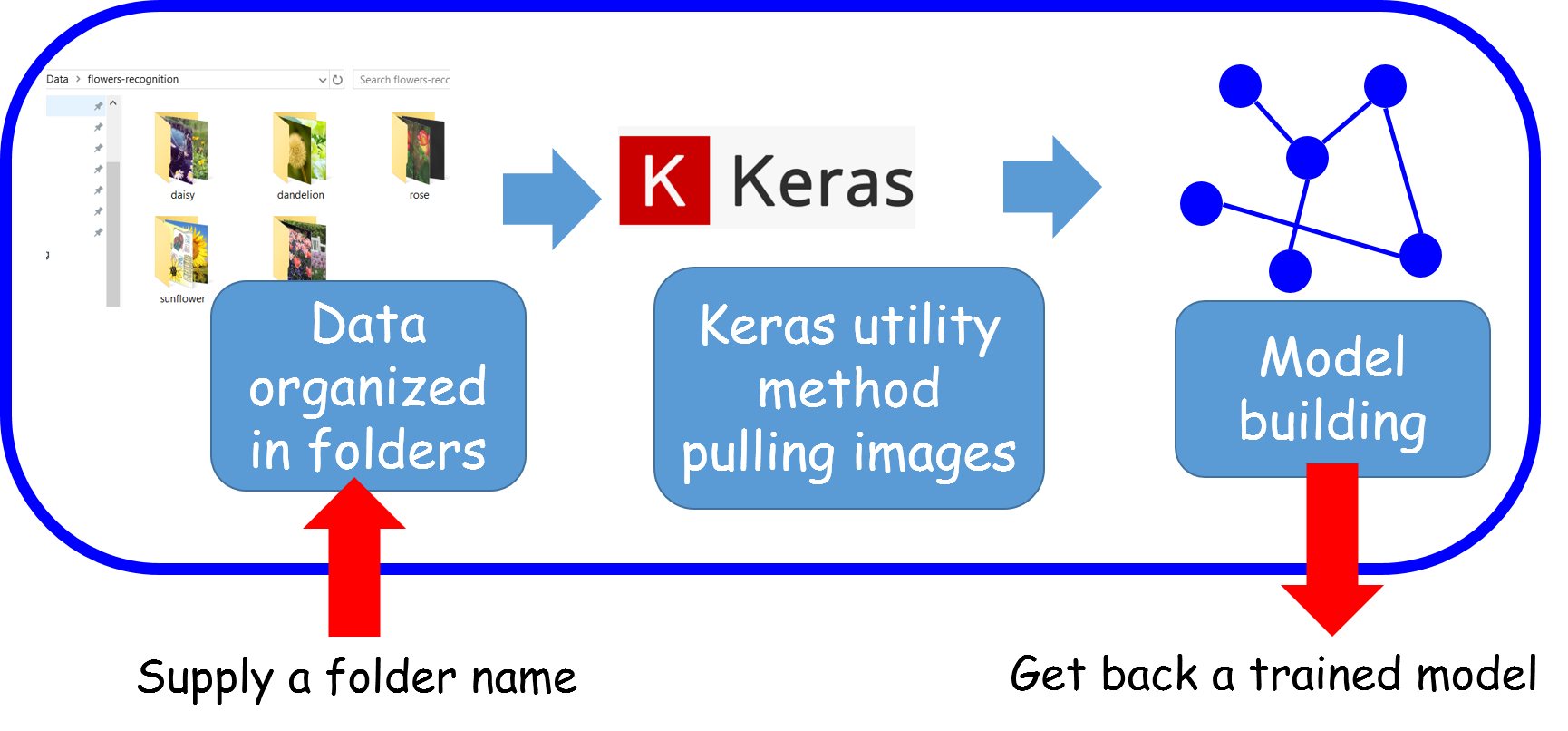
Aim for a flexible API with useful arguments
When you are designing a high-level API, why not go for more generalization than what is required for this particular demo with flowers dataset? With that in our mind, we can think of providing additional arguments to this function for making it applicable to other image classification cases (we will see an example soon).
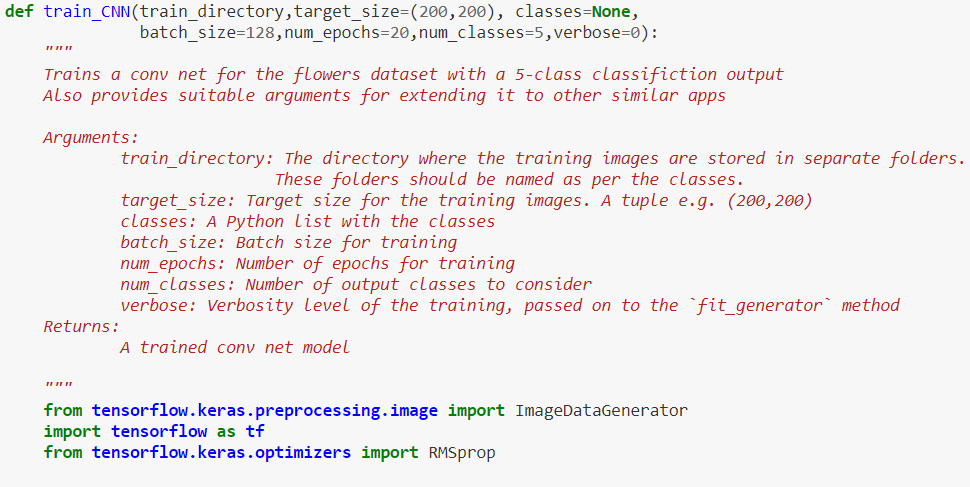
Specifically, we provide the following arguments in the function,
train_directory: The directory where the training images are stored in separate folders. These folders should be named as per the classes.target_size: Target size for the training images. A tuple e.g. (200,200)classes: A Python list with the classes, for which we want the training to happen. This forces the generator to choose specific files from thetrain_directoryand not look at all the data.batch_size: Batch size for trainingnum_epochs: Number of epochs for trainingnum_classes: Number of output classes to considerverbose: Verbosity level of the training, passed on to thefit_generatormethod
Of course, we could have provided additional arguments corresponding to the whole model architecture or optimizer settings. This article is not focused on such issues, and therefore, we keep it compact.
Again, the full code is in the Github repo. Below, we just show the docstring portion to emphasis on the point of making it a flexible API,
Testing our utility function
Now we test our train_CNN function by simply supplying a folder/directory name and getting back a trained model which can be used for predictions!
Let’s also suppose that we want to train only for ‘daisy’, ‘rose’, and ‘tulip’ now and ignore the other two flowers’ data. We simply pass on a list to the classes argument. In this case, don't forget to set the num_classes argument to 3. You will notice how the steps per epoch are automatically reduced to 20 as the number of training samples is less than the case above.
Also, note that the verbose is set to 0 by default in the function above, and therefore you need to specify explicitly verbose=1 if you want to monitor the progress of the training epoch-wise!
Basically, we are able to get a fully trained CNN model with 2 lines of code now!
Is the function useful for another dataset?
This is an acid test for the utility of such a function.
Can we just take it and apply to another dataset without much modification?
Caltech-101
A rich yet manageable image classification dataset is Caltech-101. By manageable I meant, not as large as the ImageNet database, which requires massive hardware infrastructure to train, and therefore, out of bounds, for testing cool ideas quickly on your laptop, yet diverse enough for practicing and learning the tricks and trades of convolutional neural networks.

Caltech-101 is an image dataset of diverse types of objects belonging to 101 categories. There are about 40 to 800 images per category. Most categories have about 50 images. The size of each image is roughly 300 x 200 pixels.
The dataset was built by none other than Prof. Fei Fei Li and her colleagues (Marco Andreetto, and Marc ‘Aurelio Ranzato) at Caltech in 2003 when she was a graduate student there. We can surmise, therefore, that Caltech-101 was a direct precursor for her work on the ImageNet.
Training Caltech-101 with two lines of codes
We downloaded the dataset and uncompressed the contents in the same Data folder as before. The directory looks like following,
So, we have what we want — a top-level directory with sub-directories containing training images.
And then, the same two lines as before,
All we did is to pass on the address of this directory to the function and choose what categories of the image we want to train the model for. Let’s say we want to train the model for classification between ‘cup’ and ‘crab’. We can just pass their names as a list to the classes argument as before.
Also, note that we may have to reduce the batch_size significantly for this dataset as the total number of training images will be much lower compared to the Flowers dataset and if the batch_size is higher than the total sample then we will have steps_per_epoch equal to 0 and that will create an error during training.
Voila! The function finds the relevant images (130 of them in total) and trains the model, 4 per batch, i.e. 33 steps per epoch.

Testing our model
So, we saw how easy it was to just pass on the training images’ directory address to the function and train a CNN model with our chosen classes.
Is the model any good? Let’s find out by testing it with random pictures downloaded from the internet.
Remember, the Caltech-101 dataset was created by Fei Fei Li and colleagues back in 2003. So, there is little chance that any of the newer images on the internet will be in the dataset.
We downloaded following random pictures of ‘crabs’ and ‘cups’.



After some rudimentary image processing (resizing and dimension expansion to match the model), we get the following result,
model_caltech101.predict(img_crab)>> array([[1., 0.]], dtype=float32)
The model predicted the class correctly for the crab test image.
model_caltech101.predict(img_cup)>> array([[0., 1.]], dtype=float32)

The model predicted the class correctly for the cup test image.
But what about for this one?
model_caltech101.predict(img_crab_cup)>> array([[0., 1.]], dtype=float32)
So, the model predicts the test image as a cup. Almost fair, isn’t it?
Validation set and other extensions
So far, inside the fit_generator we only had a train_generator object for training. But what about a validation set? It follows exactly the same concept as a train_generator. You can randomly split from your training images a validation set and set them aside in a separate directory (same sub-directory structures as the training directory) and you should be able to pass that on to the fit_generator function.
There is even a method of flow_from_dataframe for the ImageDataGenerator class, where you can pass on the names of the image files as contained in a Pandas DataFrame and the training can proceed.
Feel free to experiment with these extensions.
Summary
In this article we went over a couple of utility methods from Keras, that can help us construct a compact utility function for efficiently training a CNN model for an image classification task. If we can organize training images in sub-directories under a common directory, then this function may allow us to train models with a couple of lines of codes only.
This makes sense since rather than individually scraping and pre-processing images using other libraries (such as PIL or Scikit-image), with these built-in classes/methods and our utility function, we can keep the code/data flow entirely within Keras and train a CNN model in a compact fashion.
If you have any questions or ideas to share, please contact the author at tirthajyoti[AT]gmail.com. Also, you can check the author’s GitHub repositories for other fun code snippets in Python, R, and machine learning resources. If you are, like me, passionate about machine learning/data science, please feel free to add me on LinkedIn or follow me on Twitter.
Original. Reposted with permission.
Related:
- Object-oriented programming for data scientists: Build your ML estimator
- How a simple mix of object-oriented programming can sharpen your deep learning prototype
- What is Benford’s Law and why is it important for data science?