 What is Benford’s Law and why is it important for data science?
What is Benford’s Law and why is it important for data science?
 What is Benford’s Law and why is it important for data science?
What is Benford’s Law and why is it important for data science?Benford’s law is a little-known gem for data analytics. Learn about how this can be used for anomaly or fraud detection in scientific or technical publications.

Introduction
We all know about the Normal distribution and its ubiquity in all kind of natural phenomena or observations. But there is another law of numbers which does not get much attention but pops up everywhere — from nations’ population to stock market volumes to the domain of universal physical constants.
It is called “Benford’s Law.” In this article, we will discuss what it is and why it is important for data science.
What is Benford’s law?
Benford’s Law, also known as the Law of First Digits or the Phenomenon of Significant Digits, is the finding that the first digits (or numerals to be exact) of the numbers found in series of records of the most varied sources do not display a uniform distribution, but rather are arranged in such a way that the digit “1” is the most frequent, followed by “2”, “3”, and so in a successively decreasing manner down to “9”.
It is illustrated in the figure below.

Image Credit: Wikipedia
Who discovered this law?
The first record on the subject dates from 1881, in the work of Simon Newcomb, an American-Canadian astronomer and mathematician. Newcomb, while flipping through pages of a book of logarithmic tables, noted that the pages at the beginning of the book were dirtier than the pages at the end. This meant that his colleagues, who shared the library, preferred quantities beginning with the number one in their various disciplines.
In 1938, the American physicist Frank Benford revisited the phenomenon, which he called the “Law of Anomalous Numbers” in a survey with more than 20,000 observations of empirical data compiled from various sources, ranging from areas of rivers to molecular weights of chemical compounds, cost data, address numbers, population sizes, and physical constants. All of them, to a greater or lesser extent, followed such an exponentially diminishing distribution.
In 1995, the phenomenon was finally proven by Hill. His proof was based on the fact that numbers in data series following the Benford’s Law are, in effect, “second generation” distributions, i.e., combinations of other distributions.
Where does it pop up and are there any special conditions?
Well, in many places…
It has been shown that this result applies to a wide variety of data sets, including electricity bills, street addresses, stock prices, house prices, population numbers, death rates, lengths of rivers, etc.
Following is a figure from a physics journal paper showing the law’s reach to as diverse datasets as Census, Birth rate, Area of countries, Lottery numbers, etc.

Image credit: “Numbers follow a surprising law of digits, and scientists can’t explain why”
In general, it has been seen that a series of numerical records follows Benford’s Law when they
- represents magnitudes of events or events, such as populations of cities, flows of water in rivers or sizes of celestial bodies;
- do not have a pre-established minimum or maximum limits;
- are not made up of numbers used as identifiers, such as identity or social security numbers, bank accounts, telephone numbers; and
- have a mean which is less than the median, and the data is not concentrated around the mean
See this thesis about a detailed discussion of the law.
So, how does it help in Data Science and Analytics?
Similar to the usage of Normal distribution as a tool for reference and gold standard, this law can be utilized to detect a pattern (or lack thereof) in naturally occurring datasets. This can lead to important applications in data science, such as catching anomalies or fraud detection.
See this video for a detailed explanation of how Benford’s law is used to detect fraud.
How can data help us to detect fraud?
A simple example — how to detect if that regression model was a fraud?
These days, we see so much statistical jargon of machine learning and p-values thrown out at us in popular media, that it is essential we are able to separate the grain from the chaff.
This paper discusses, at depth, the idea of using this law for detecting potential forgery in data in scientific studies (which mainly build complex regression models and report confidence intervals and so on).
Suppose, you have this simple 1-dimensional data set.

If you are asked to do a proper regression analysis and build a model, you may come up with something like following.

But what if you never did the proper analysis (or regularization), or fudge the data a bit to improve your R² coefficient? For any number of such fraudulent scenarios, you can have various versions of the regression model fit as shown below.
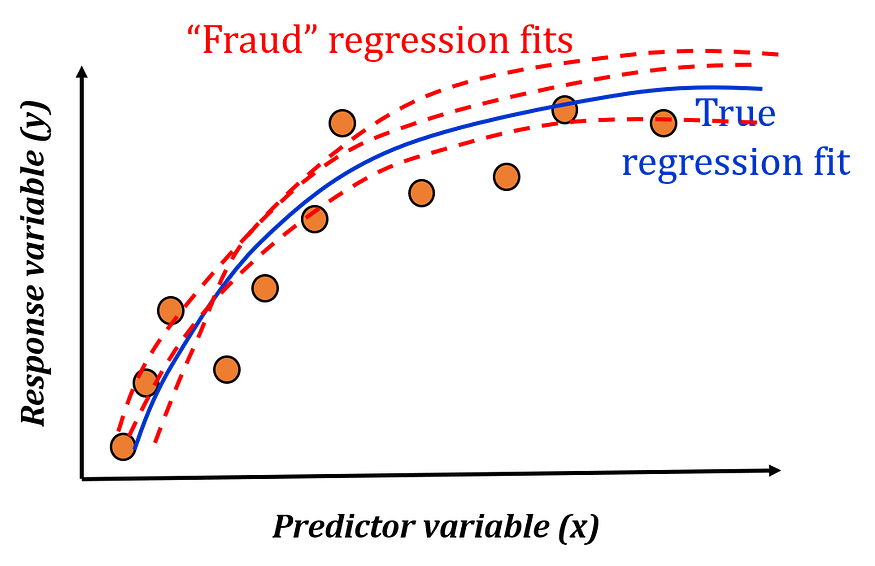
Now, if we do a meta-analysis of such models, we will get various model coefficients which may differ slightly from one another.
It turns out that if your dataset comes from naturally occurring phenomena, then with the fraudulent fits, even if you get the first numeral of the regression coefficients right, the subsequent (2nd and 3rd) numerals may show telltale signs of ‘manufacturing models.’ The distribution of those 2nd and 3rd numerals are supposed to follow a diminishing power law (even if not exactly Benford’s law) and if that is not the case, then something could be wrong.
For example, if there are a significantly higher number of 8’s in the 2nd numerals of regression model than there are 2’s, then something is not correct!
Yes, it is like detective work, to pour through the fine details of machine learning models and their coefficients, extracting numerals and checking to make sure they follow the expected distribution!
Application in Business Analytics
One area, where unscrupulous professionals, regularly try to ‘manufacture’ data is financial statements of a business.
When we humans, try to conjure up supposedly random numbers in our head, we tend to think in terms of uniform distribution or, at the most, Gaussian distribution. We certainly don’t think in terms of Geometric distribution (which the law closely follows).
So, a fraudster may be caught if a machine analyzes the supposedly random numbers he tried to insert in a business document.
This article shows how the same law can be used effectively to detect financial statement frauds. While Benford’s Law should not be used as a final decision-making tool by itself, it may prove to be a useful screening tool to indicate that a set of financial statements deserves a deeper analysis.
Benford's Law and Financial Statements
Summary
Science/technology and business publications are not above suspicion and second screening today. It is an unfortunate but true development. In this era of Big Data, every day, we are inundated by statistical models and conclusions. These studies, models, and their conclusions affect our society deeply, in an all-encompassing way— healthcare, economics, social interaction, technological research. It is even more disheartening to see that basic science research publications, which are supposed to report the pure objective truth, are not above such dishonesty and fraud.
We need effective screens and sound analytical techniques to judge the veracity of these models and research publications.
In this article, we discuss one such statistical law and its utility for detecting anomaly in number patterns.
Original. Reposted with permission.
Related: