 Deep Learning for NLP: ANNs, RNNs and LSTMs explained!
Deep Learning for NLP: ANNs, RNNs and LSTMs explained!
 Deep Learning for NLP: ANNs, RNNs and LSTMs explained!
Deep Learning for NLP: ANNs, RNNs and LSTMs explained!Learn about Artificial Neural Networks, Deep Learning, Recurrent Neural Networks and LSTMs like never before and use NLP to build a Chatbot!
By Jaime Zornoza, Universidad Politecnica de Madrid

Ever fantasied about having your own personal assistant to answer any questions you can ask, or have conversations with? Well, thanks to Machine Learning and Deep Neural Networks, this is not so far from happening. Think of the amazing capabilities exhibited by Apple’s Siri or Amazon’s Alexa.
Don’t get too excited, in this next series of posts we are not going to create an omnipotent Artificial Intelligence, rather we will create a simple chatbot that given some input information and a question about such information, responds to yes/no questions regarding what it has been told.
It is nowhere near to Siri’s or Alexa’s capabilities, but it illustrates very well how even using very simple deep neural network structures, amazing results can be obtained. In this post we will learn about Artificial Neural Networks, Deep Learning, Recurrent Neural Networks and Long-Short Term Memory Networks. In the next post we will use them on a real project to make a question answering bot.
Before we start with all the fun regarding Neural Networks, I want you to first take a close look at the following image. In it there are two pictures; one of a school bus driving through a road, and one of an ordinary living room, which have had descriptions attached by human annotators.

Done? Lets get on with it then!
The beginning— Artificial Neural Networks
To construct the neural network model that will be used to create the chatbot, Keras, a very popular Python Library for Neural Networks will be used. However, before going any further, we first have to understand what an Artificial Neural Network or ANN is.
ANNs are Machine Learning models that try to mimic the functioning of the human brain, whose structure is built from a large number of neurons connected in between them — hence the name “Artificial Neural Networks”
The Perceptron
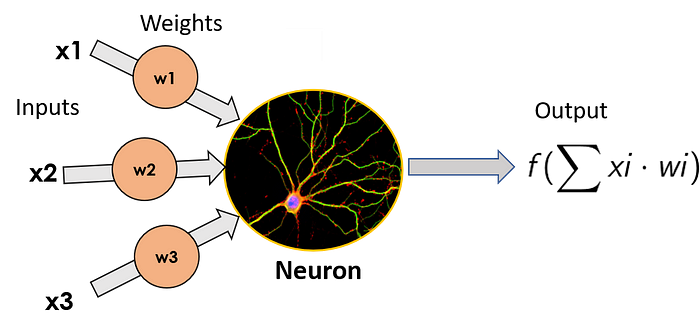
The simplest ANN model is composed of a single neuron, and goes by the Star-Trek sounding name Perceptron. It was invented in 1957 by Frank Rossenblatt, and it consist of a simple neuron, which takes the weighted sum of its inputs (which in a biological neuron would be the dendrites) applies a mathematical function to them, and outputs its result (the output would be the equivalent of the axon of a biological neuron). We won’t dive into the details of the different functions that can be applied here, as the intention of the post is not to become experts, but rather to get a basic understanding of how a neural network works.
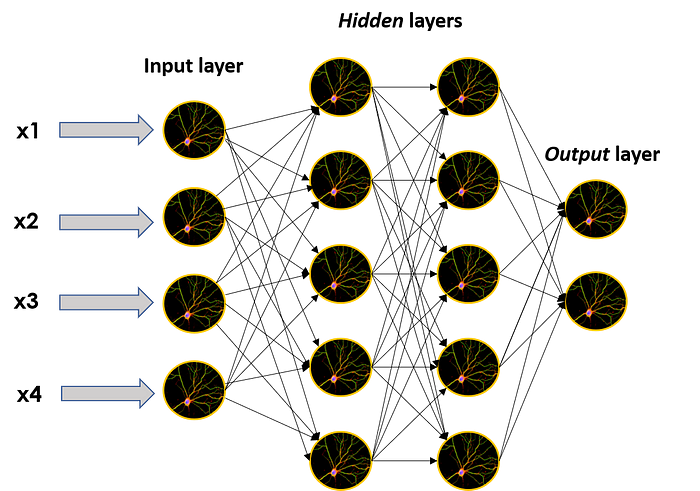
These individual neurons can be stacked on top of each other forming layers of the size that we want, and then these layers can be sequentially put next to each other to make the network deeper.
When networks are built in this way, the neurons that don’t belong to the input or output layers are considered part of the hidden layers, depicting with their name one of the main characteristics of an ANN: they are almost black box models; we understand the mathematics behind what happens, and kind of have an intuition of what goes on inside the black box, but if we take the output of a hidden layer and try to make sense of it, we will probably crunch our heads and achieve no positive results.
Still, they produce amazing results, so nobody complains about their lack of interpretability.
Neural network structures and how to train them have been known already for more than two decades. What is it then, that has lead to all the fuss and hype about ANN and Deep Learning that is going on right now? The answer to this question is just below, but before we have to understand what Deep Learning really is.
What is Deep Learning then?
Deep learning, as you might guess by the name, is just the use of a lot of layers to progressively extract higher level features from the data that we feed to the neural network. It is a simple as that; the use of multiple hidden layers to enhance the performance of our neural models.
Now that we know this, the answer to the question above is pretty easy: scale. Over the last two decades the amount of available data of all sorts, and the power of our data storing and processing machines (yes, computers), have exponentially increased.
These computing capabilities and the massive increases in the amount of available data to train our models with have allowed us to create larger, deeper neural networks, which just perform better than smaller ones.
Andrew Ng, one of the world’s leading experts in Deep Learning, makes this clear in this video. In it, he shows an image similar to the following one, and with it he explains the benefits of having more data to train our models with, and the advantage of large neural networks versus other Machine Learning models.

For traditional Machine Learning algorithms (linear or logistic regressions, SMVs, Random Forests and so on), performance increases as we train the models with more data, up to a certain point, where performance stops going up as we feed the model with further data. When this point is reached it is like the model does not know what to do with the additional data, and i’ts performance can not be improved any more by feeding more of it.
With neural networks on the other hand, this never happens. Performance, almost always increases with data (if this data is of good quality of course), and it does so at a faster pace depending on the size of the network. Therefore, if we want to get the best possible performance, we would need to be somewhere on the green line (Large Neural Network) and towards the right of the X axis (high Amount of Data).
Aside from this, there has also been some algorithmic improvements, but the main fact that has led to the magnificent rise of Deep Learning and Artificial Neural Networks, is just scale: scale of computing and scale of data.
Another important personality on the field, Jeff Dean (one of the instigators of the adoption of Deep Learning within Google), says the following about deep learning:
When you hear the term deep learning, just think of a large deep neural net. Deep refers to the number of layers typically and so this is kind of the popular term that’s been adopted in the press. I think of them as deep neural networks generally.
When talking about Deep Learning, he highlights the scalability of neural networks indicating that results get better with more data and larger models, that in turn require more computation to train, just like we have seen before.
Okay perfect I understood all that, but how do Neural Networks actually learn?
Well, you probably have guessed already: they learn from data.
Remember the weights that multiplied our inputs in the single perceptron? Well, these weights are also included in any edge that joins two different neurons. This means that in the image of a larger neural network, they are present in every single one of the black edges, taking the output of one neuron, multiplying it and then giving it as input to the other neuron that such edge is connected to.
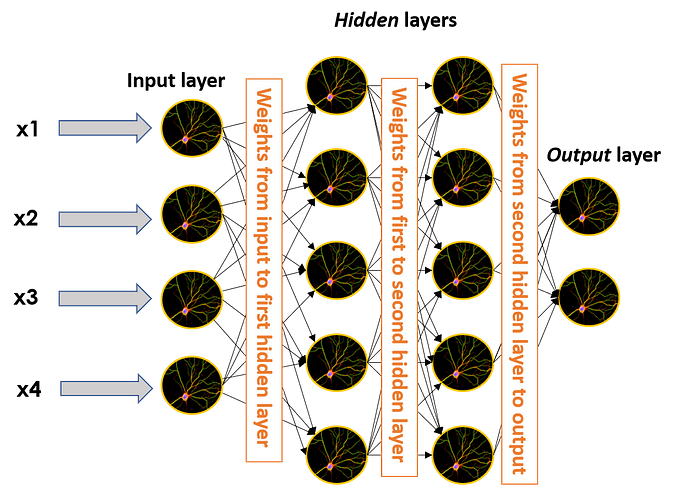
When we train a neural network (training a neural network is the ML expression for making it learn) we feed it a set of known data (in ML this is called labelled data), have it predict a characteristic that we know about such data (like if an image represents a dog or a cat) and then compare the predicted result to the actual result.
As this process goes on and the network makes mistakes, it adapts the weights of the connections in between the neurons to reduce the number of mistakes it makes. Because of this, as shown before, if we give the network more and more data most of the time it will improve it’s performance.
Learning from sequential data — Recurrent Neural Networks
Now that we know what artificial neural networks and deep learning are, and have a slight idea of how neural networks learn, lets start looking at the type of networks that we will use to build our chatbot: Recurrent Neural Networks or RNNs for short.
Recurrent neural networks are a special kind of neural networks that are designed to effectively deal with sequential data. This kind of data includes time series (a list of values of some parameters over a certain period of time) text documents, which can be seen as a sequence of words, or audio, which can be seen as a sequence of sound frequencies.
The way RNNs do this, is by taking the output of each neuron, and feeding it back to it as an input. By doing this, it does not only receive new pieces of information in every time step, but it also adds to these new pieces of information a weighted version of the previous output. This makes these neurons have a kind of “memory” of the previous inputs it has had, as they are somehow quantified by the output being fed back to the neuron.
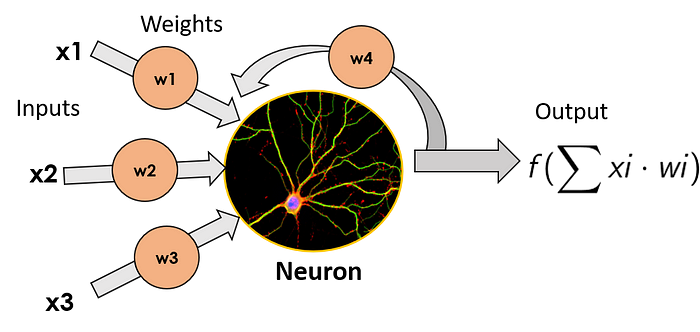
Cells that are a function of inputs from previous time steps are also known as memory cells.
The problem with RNNs is that as time passes by and they get fed more and more new data, they start to “forget” about the previous data they have seen, as it gets diluted between the new data, the transformation from activation function, and the weight multiplication. This means they have a good short term memory, but a slight problem when trying to remember things that have happened a while ago (data they have seen many time steps in the past).
We need some sort of Long term memory, which is just what LSTMs provide.
Enhancing our memory — Long Short Term Memory Networks
Long-Short Term Memory networks or LSTMs are a variant of RNN that solve the Long term memory problem of the former. We will end this post by briefly explaining how they work.
They have a more complex cell structure than a normal recurrent neuron, that allows them to better regulate how to learn or forget from the different input sources.

An LSTM neuron can do this by incorporating a cell state and three different gates: the input gate, the forget gate and the output gate. In each time step, the cell can decide what to do with the state vector: read from it, write to it, or delete it, thanks to an explicit gating mechanism. With the input gate, the cell can decide whether to update the cell state or not. With the forget gate the cell can erase its memory, and with the output gate the cell can decide whether to make the output information available or not.
LSTMs also mitigate the problems of exploding and vanishing gradients, but that is a story for another day.
That’s it! Now we have a superficial understanding of how these different kind of neural networks work, and we can put it to use to build our first Deep Learning project!
Conclusion
Neural Networks are awesome. As we will see in the next post, even a very simple structure with just a few layers can create a very competent Chatbot.
Oh, and by the way, remember this image?
Well, just to prove how cool Deep Neural Networks are, I have to admit something. I lied about how the descriptions for the images were produced.
At the beginning of the post I said that these descriptions were made by human annotators, however, the truth is that these short texts describing what can be seen on each image were actually produced by an Artificial Neural Network.
Insane right?
If you want to learn how to use Deep Learning to create an awesome chatbot, follow me on Medium, and stay tuned for my next post!
Until then, take care, and enjoy AI!
Additional Resources:
As the explanations for the different concepts described in this post have been very superficial, in case there is any of you who wants to go further and continue learning, here are some fantastic additional resources.
- How neural networks work end to end
- Youtube Video series explaining the main concepts about how Neural Networks are trained
- Deep Learning & Artificial Neural Networks
Okay, that is all, I hope you liked the post. Feel Free to connect with me on LinkedIn or follow me on Twitter at @jaimezorno. Also, you can take a look at my other posts on Data Science and Machine Learning here. Have a good read!
Bio: Jaime Zornoza is an Industrial Engineer with a bachelor specialized in Electronics and a Masters degree specialized in Computer Science.
Original. Reposted with permission.
Related:
- Understanding Backpropagation as Applied to LSTM
- Training a Neural Network to Write Like Lovecraft
- Adapters: A Compact and Extensible Transfer Learning Method for NLP