Coding Random Forests® in 100 lines of code*
There are dozens of machine learning algorithms out there. It is impossible to learn all their mechanics; however, many algorithms sprout from the most established algorithms, e.g. ordinary least squares, gradient boosting, support vector machines, tree-based algorithms and neural networks.
By STATWORX
Motivation
There are dozens of machine learning algorithms out there. It is impossible to learn all their mechanics; however, many algorithms sprout from the most established algorithms, e.g. ordinary least squares, gradient boosting, support vector machines, tree-based algorithms and neural networks. At STATWORX we discuss algorithms daily to evaluate their benefits for a specific project. In any case, understanding these core algorithms is key to most machine learning algorithms in the literature.
Why bother writing from scratch?
While I like reading machine learning research papers, the maths is sometimes hard to follow. That is why I like implementing the algorithms in R by myself. Of course, this means digging through the maths and the algorithms as well. However, you can challenge your understanding of the algorithm directly.
In my last blog posts, I introduced two machine learning algorithms in 150 lines of R Code. You can find the other blog posts about coding gradient boosted machines and regression trees from scratch on our blog or in the readme on my GitHub. This blog post is about the random forest, which is probably the most prominent machine learning algorithm. You have probably noticed the asterisk (*) in the title. These things often suggest, that there has to be something off. Like seeing a price for a cell phone plan in a tv commercial and while reading the fine prints you learn that it only applies if you have successfully climbed Mount Everest and you got three giraffes on your yacht. Also, yes your suspicion is justified; unfortunately, the 100 lines of code only apply if we don’t add the code from the regression tree algorithm, which is essential for a random forest. That is why I would strongly recommend reading the blog about regression trees, if you are not familiar with the regression tree algorithm.
Understanding ML with simple and accessible code
In this series we try to produce very generic code, i.e. it won’t produce a state-of-the-art performance. It is instead designed to be very generic and easily readable.
Admittedly, there are tons of great articles out there which explain random forests theoretically accompanied with a hands-on example. That is not the objective of this blog post. If you are interested in a hands-on tutorial with all the necessary theory, I strongly recommend this tutorial. The objective of this blog post is to establish the theory of the algorithm by writing simple R code. The only thing you need to know, besides the fundamentals of a regression tree, is our objective: We want to estimate our real-valued target (y) with a set of real-valued features (X).
Reduce dimensionality with Feature Importance
Fortunately, we do not have to cover too much maths in this tutorial, since that part is already covered in the regression tree tutorial. However, there is one part, which I have added in the code since the last blog post. Regression trees and hence random forests, opposed to a standard OLS regression, can neglect unimportant features in the fitting process. This is one significant advantage of tree-based algorithms and is something which should be covered in our basic algorithm. You can find this enhancement in the new reg_tree_imp.R script on GitHub. We use this function to sprout trees in our forest later on.
Before we jump into the random forest code, I would like to touch very briefly on how we can compute feature importance in a regression tree. Surely, there are tons of ways on how you can calculate feature importance, the following approach is, however, quite intuitive and straightforward.
Evaluating the goodness of a split
A regression tree splits the data by choosing the feature which minimizes a certain criterion, e.g. the squared error of our prediction. Of course, it is possible, that some features will never be chosen for a split, which makes calculating their importance very easy. However, how can we compute importance with chosen features? A first shot could be to count the number of splits for each feature and relativize it by the total number of all splits. This measure is simple and intuitive, but it cannot quantify how impactful the splits were, and this is something we can accomplish with a very simple but more sophisticated metric. This metric is a weighted goodness of fit. We start by defining our goodness of fit for each node. For instance, the mean squared error, which is defined as:

This metric describes the average squared error we make when we estimate our target y_i with our predictor the average value in our current node \bar(y)_{node}. Now we can measure the improvement by splitting the data with the chosen feature and compare the goodness of fit of the parent node with the performance of its children nodes. Essentially, this is more or less the exact step we performed to evaluate the best splitting feature for the current node.
Weighting the impact of a split
Splits at the top of the tree are more impactful as more data reaches the nodes at this stage of the tree. That’s why it makes sense to lay more importance on earlier splits by taking into account the number of observations which reached this node.

This weight describes the number of observations in the current node measured by the total number of observations. Combining the results above, we can derive a weighted improvement of a splitting feature p in a single node as:
Quantifying improvements by splitting the data in a regression tree
![Improvement^{[p]}_{node} = w_{node}MSE_{node} - (w_{left}MSE_{left} + w_{right}MSE_{right})](https://www.statworx.com/wp-content/ql-cache/quicklatex.com-de8a05136223408bbb6cbfdbbe8db7e1_l3.svg)
This weighted improvement is calculated at every node which was split for the respective splitting feature p. To get better interpretability of this improvement, we sum up the improvements for each feature in our tree and normalize it by the overall improvement in our tree.
Quantifying the importance of a feature in a regression tree
![Importance^{[p]} = \frac{\sum_{k=1}^{p} Improvement^{[k]}}{\sum_{i=1}^{n_{node}} Improvement^{[i]}}](https://www.statworx.com/wp-content/ql-cache/quicklatex.com-b3877b27bf9aa8d9e9d69788a4c878d7_l3.svg)
This is the final feature importance measure used within regression tree algorithm. Again, you can follow these steps within the code of the regression tree. I have tagged all variables, functions and column names involved in the feature importance calculation with imp_* or IMP_* , that should make it a little easier to follow.
The Random forest Algorithm
All right, enough with this regression tree and importance – we are interested in the forest in this blog post. The objective of a random forest is to combine many regression or decision trees. Such a combination of single results is referred to as ensemble techniques. The idea of this technique is very simple but yet very powerful.
Building a regression tree orchestra
In a symphonic orchestra, different groups of instruments are combined to form an ensemble, which creates more powerful and diverse harmonies. Essentially, it is the same in machine learning, because every regression tree we sprout in random forest has the chance to explore the data from a different angle. Our regression tree orchestra has thus different views on the data, which makes the combination very powerful and diverse opposed to a single regression tree.
Simplicity of a random forest
If you are not familiar with the mechanics algorithm, you probably think that the code gets very complicated and hard to follow. Well, to me the amazing part of this algorithm is how simple and yet effective it is. The coding part is not as challenging as you might think. Like in the other blog posts we take a look at the whole code first and then we go through it bit by bit.
The algorithm at one glimpse
#' reg_rf
#' Fits a random forest with a continuous scaled features and target
#' variable (regression)
#'
#' @param formula an object of class formula
#' @param n_trees an integer specifying the number of trees to sprout
#' @param feature_frac an numeric value defined between [0,1]
#' specifies the percentage of total features to be used in
#' each regression tree
#' @param data a data.frame or matrix
#'
#' @importFrom plyr raply
#' @return
#' @export
#'
#' @examples # Complete runthrough see: www.github.com/andrebleier/cheapml
reg_rf <- function(formula, n_trees, feature_frac, data) {
# source the regression tree function
source("algorithms/reg_tree_imp.R")
# load plyr
require(plyr)
# define function to sprout a single tree
sprout_tree <- function(formula, feature_frac, data) {
# extract features
features <- all.vars(formula)[-1]
# extract target
target <- all.vars(formula)[1]
# bag the data
# - randomly sample the data with replacement (duplicate are possible)
train <-
data[sample(1:nrow(data), size = nrow(data), replace = TRUE)]
# randomly sample features
# - only fit the regression tree with feature_frac * 100 % of the features
features_sample <- sample(features,
size = ceiling(length(features) * feature_frac),
replace = FALSE)
# create new formula
formula_new <-
as.formula(paste0(target, " ~ ", paste0(features_sample,
collapse = " + ")))
# fit the regression tree
tree <- reg_tree_imp(formula = formula_new,
data = train,
minsize = ceiling(nrow(train) * 0.1))
# save the fit and the importance
return(list(tree$fit, tree$importance))
}
# apply the rf_tree function n_trees times with plyr::raply
# - track the progress with a progress bar
trees <- plyr::raply(
n_trees,
sprout_tree(
formula = formula,
feature_frac = feature_frac,
data = data
),
.progress = "text"
)
# extract fit
fits <- do.call("cbind", trees[, 1])
# calculate the final fit as a mean of all regression trees
rf_fit <- apply(fits, MARGIN = 1, mean)
# extract the feature importance
imp_full <- do.call("rbind", trees[, 2])
# build the mean feature importance between all trees
imp <- aggregate(IMPORTANCE ~ FEATURES, FUN = mean, imp_full)
# build the ratio for interpretation purposes
imp$IMPORTANCE <- imp$IMPORTANCE / sum(imp$IMPORTANCE)
# export
return(list(fit = rf_fit,
importance = imp[order(imp$IMPORTANCE, decreasing = TRUE), ]))
}
As you have probably noticed, our algorithm can be roughly divided into two parts. Firstly, a function sprout_tree() and afterwards some lines of code which call this function and process its output. Let us now work through all the code chunk by chunk.
# source the regression tree function
source("algorithms/reg_tree_imp.R")
# load plyr
require(plyr)
# define function to sprout a single tree
sprout_tree <- function(formula, feature_frac, data) {
# extract features
features <- all.vars(formula)[-1]
# extract target
target <- all.vars(formula)[1]
# bag the data
# - randomly sample the data with replacement (duplicate are possible)
train <-
data[sample(1:nrow(data), size = nrow(data), replace = TRUE)]
# randomly sample features
# - only fit the regression tree with feature_frac * 100 % of the features
features_sample <- sample(features,
size = ceiling(length(features) * feature_frac),
replace = FALSE)
# create new formula
formula_new <-
as.formula(paste0(target, " ~ ", paste0(features_sample,
collapse = " + ")))
# fit the regression tree
tree <- reg_tree_imp(formula = formula_new,
data = train,
minsize = ceiling(nrow(train) * 0.1))
# save the fit and the importance
return(list(tree$fit, tree$importance))
}
Sprouting a single regression tree in a forest
The first part of the code is the sprout_tree() function, which is just a wrapper for the regression tree function reg_tree_imp(), which we source as the first action of our code. Then we extract our target and the features from the formula object.
Creating different angles by bagging the data
Afterwards, we bag the data, which means we are randomly sampling our data with the chance of replacement. Remember when I said every tree will look at our data from a different angle? Well, this is the part where we create the angles. Random sampling with replacement is just a synonym for generating weights on our observations. This means that a specific observation in the data set of a specific tree could be repeated 10 times. The next tree could, however, lose this observation completely. Furthermore, there is another way of creating different angles in our trees: Feature sampling.
Solving collinearity issues between trees in a forest
From our complete feature set X we are randomly sampling a feature_frac * 100 percent to reduce the dimensionality. With feature sampling we can a) compute faster and b) capture angles on our data from supposedly weaker features as we decrease the value of feature_frac . Suppose, we have some degree of multicollinearity between our features. It might occur, that the regression tree will select only a specific feature if we use every feature in every tree.
However, supposedly features with less improvement could bare new valuable information for the model, but are not granted the chance. This is something you can achieve by lowering the dimensionality with the argument feature_frac. If your objective of the analysis is feature selection, e.g. feature importance, you might want to set this parameter to 80%-100% as you will get a more clear cut selection. Well, the rest of the function is fitting the regression tree and exporting the fitted values as well as the importance.
Sprouting a forest
In the next code chunk we start applying the sprout_tree() function n_trees times with the help of plyr::raply(). This function repeatedly applies a function call with the same arguments and combines the results in a list. Remember, we do not need to change anything in the sprout_tree() function, since the angles are created randomly every time, we call the function.
# apply the rf_tree function n_trees times with plyr::raply
# - track the progress with a progress bar
trees <- plyr::raply(
n_trees,
sprout_tree(
formula = formula,
feature_frac = feature_frac,
data = data
),
.progress = "text"
)
# extract fit
fits <- do.call("cbind", trees[, 1])
# calculate the final fit as a mean of all regression trees
rf_fit <- apply(fits, MARGIN = 1, mean)
# extract the feature importance
imp_full <- do.call("rbind", trees[, 2])
# build the mean feature importance between all trees
imp <- aggregate(IMPORTANCE ~ FEATURES, FUN = mean, imp_full)
# build the ratio for interpretation purposes
imp$IMPORTANCE <- imp$IMPORTANCE / sum(imp$IMPORTANCE)
# export
return(list(fit = rf_fit,
importance = imp[order(imp$IMPORTANCE, decreasing = TRUE), ]))
Afterwards, we combine the single regression tree fits a data frame. By calculating the row mean we are taking the average fitted value of every regression tree in our forest. Our last action is to calculate the feature importance of our ensemble. That’s the mean feature importance of a feature in all trees normalized by the overall mean importance of all variables.
Applying the algorithm
Let us apply the function to see, whether the fit is indeed better compared to a single regression tree. Additionally, we can check out the feature importance. I have created a little example on GitHub, which you can check out. First, we simulate data with the Xy package. In this simulation, five linear variables were used to create our target y. To make it a little spicier, we add five irrelevant variables, which were created in the simulation as well. The challenge now, of course, is whether the algorithm will use any irrelevant feature or if the algorithm can perfectly identify the important features. Our formula is:
eq <- y ~ LIN_1 + LIN_2 + LIN_3 + LIN_4 + LIN_5 + NOISE_1 + NOISE_2 + NOISE_3 + NOISE_4 + NOISE_5
The power of the forest
Neither the random forest nor the regression tree has selected any unnecessary features. However, the regression tree was only split by the two most important variables. Whereas, the random forest selected all five relevant features.
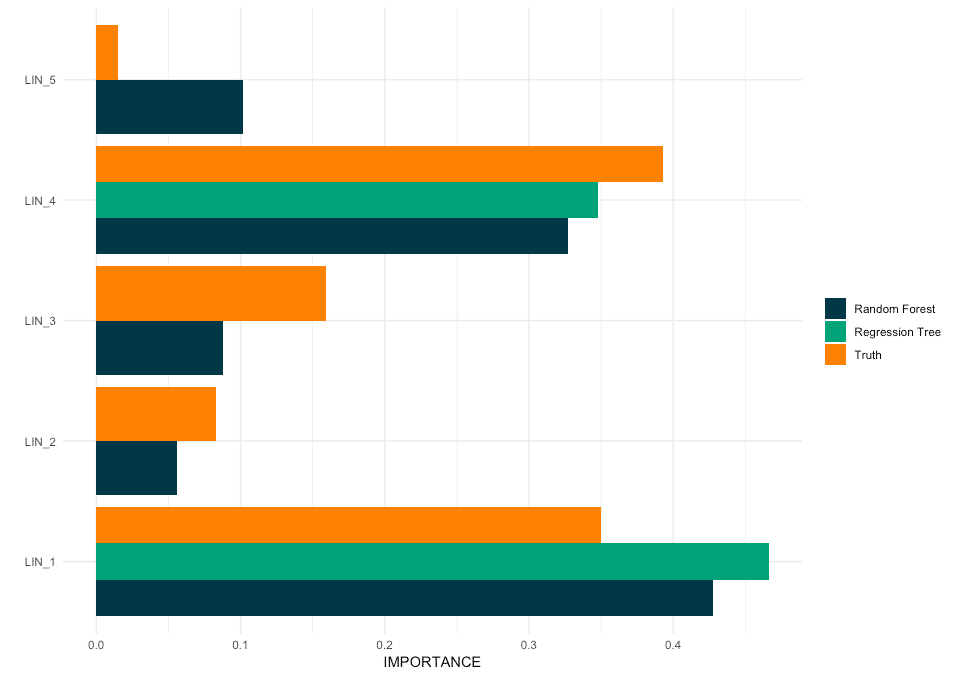
This does not mean that the regression tree is not able to find the right answer. It depends on the minimum observation size (minsize) of the tree. Surely the regression tree would eventually find all important features if we lower the minimum size. The random forest, however, found all five essential features with the same minimum size.
Learning strengths and weaknesses
Of course, this was only one example. I would strongly recommend playing around with the functions and examples by yourself because only then you can get a feel for the algorithms and where they shine or fail. Feel free to clone the GitHub repository and play around with the examples. Simulation is always nice because you get a clearcut answer; however, applying the algorithms to familiar real-world data might be beneficial to you as well.
Bio: STATWORX is a consulting company for data science, statistics, machine learning and artificial intelligence located in Frankfurt, Zurich and Vienna.
Original. Reposted with permission.
RANDOM FORESTS and RANDOMFORESTS are registered marks of Minitab, LLC.
Related:
- A Guide to Decision Trees for Machine Learning and Data Science
- Explaining Random Forest (with Python Implementation)
- Random forests explained intuitively