Multi-modal deep learning in less than 15 lines of code
Learn how to easily build, iterate and deploy a state-of-the-art deep learning model to predict customer ratings with a declarative approach to machine learning.

The challenges of building multi-modal models from scratch
For many machine learning use-cases, organizations rely solely on tabular data and tree-based models like XGBoost and LightGBM. This is because deep learning is simply too hard for most ML teams. Common challenges include:
- Lack of expert knowledge needed to develop complex deep learning models
- Frameworks like PyTorch and Tensorflow require teams to write thousands of lines of code that is prone to human error
- Training distributed DL pipelines requires deep knowledge of infrastructure and can take weeks to train models
As a result, teams miss out on valuable signals hidden within unstructured data like text and images.
Rapid model development with declarative systems
New declarative machine learning systems—like open-source Ludwig started at Uber—provide a low-code approach to automating ML that enables data teams to build and deploy state-of-the-art models faster with a simple configuration file. Specifically, Predibase—the leading low-code declarative ML platform—along Ludwig make it easy to build multi-modal deep learning models in < 15 lines of code.
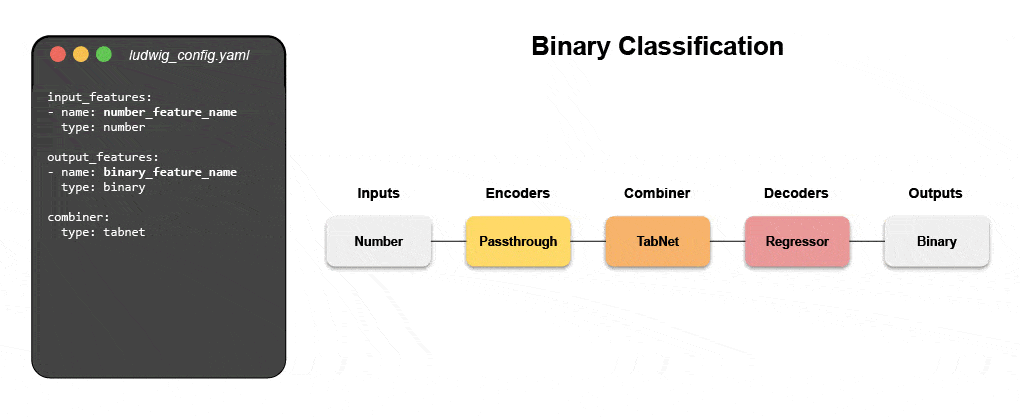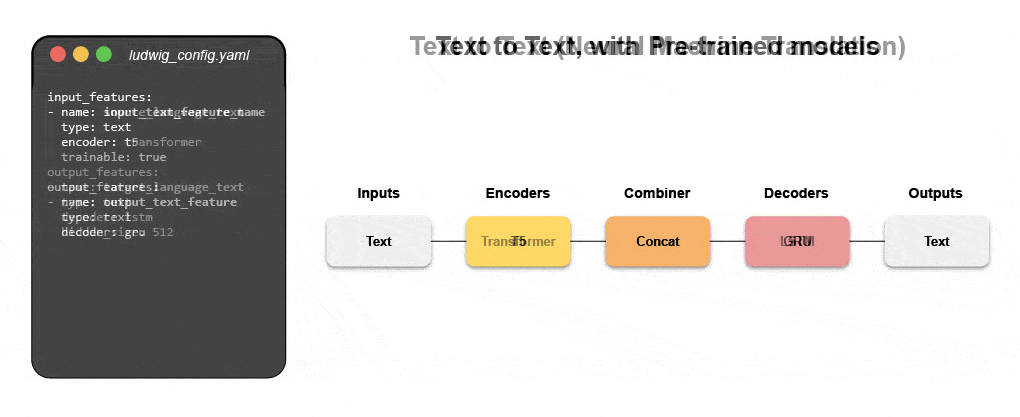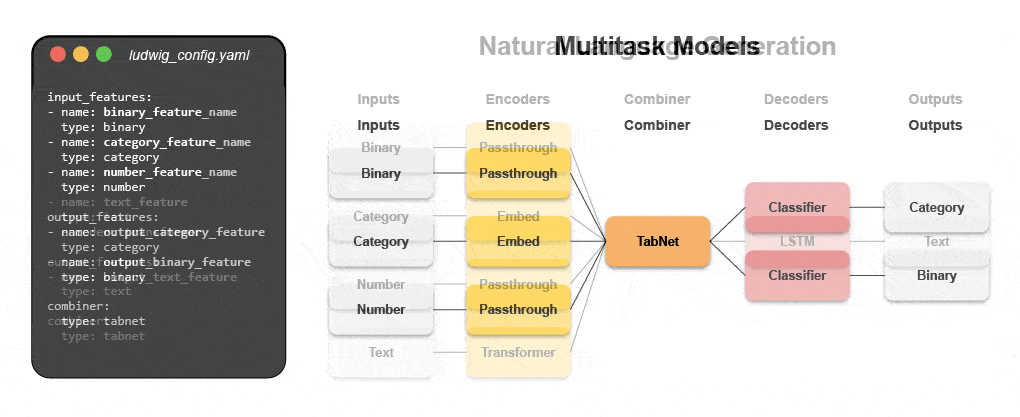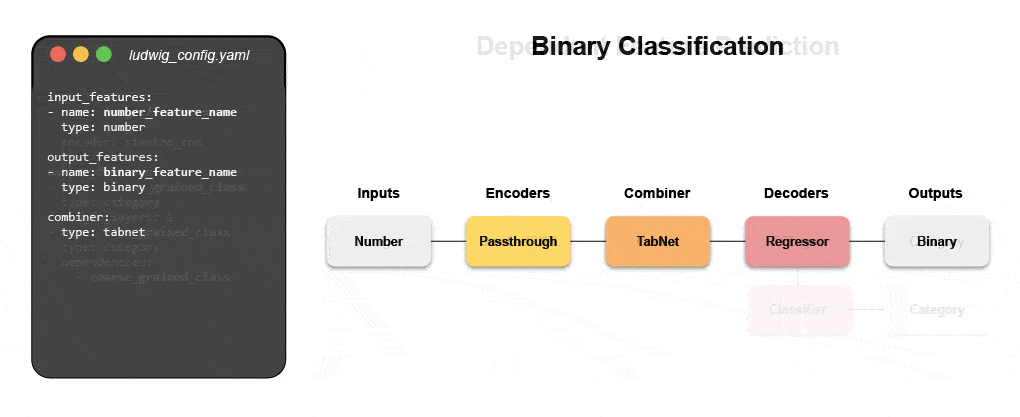
Learn how build a multi-modal model with declarative ML
Join our upcoming webinar and live tutorial to learn about declarative systems like Ludwig and follow along with step by step instructions for building a multi-modal customer review prediction model leveraging text and tabular data.
In this session you will learn how to:
- Rapidly train, iterate, and deploy a multi-modal model for customer review predictions,
- Use low-code declarative ML tools to dramatically reduce the time it takes to build multiple ML models,
- Leverage unstructured data just as easily as structured data with open-source Ludwig and Predibase