 There is No Free Lunch in Data Science
There is No Free Lunch in Data Science
 There is No Free Lunch in Data Science
There is No Free Lunch in Data ScienceThere is no such thing as a free lunch in life or data science. Here, we'll explore some science philosophy and discuss the No Free Lunch theorems to find out what they mean for the field of data science.
By Sydney Firmin, Alteryx.
During your adventures in machine learning, you may have already come across the “No Free Lunch” Theorem. Borrowing its name from the adage "there ain’t no such thing as a free lunch," the mathematical folklore theorem describes the phenomena that there is no single algorithm that is best suited for all possible scenarios and data sets.
The No Free Lunch Theorem(s)
There are, generally speaking, two No Free Lunch (NFL) theorems: one for machine learning and one for search and optimization. These two theorems are related and tend to be bundled into one general axiom (the folklore theorem).
Although many different researchers have contributed to the collective publications on the No Free Lunch theorems, the most prevalent name associated with these works is David Wolpert.
No Free Lunch for Supervised Machine Learning
In his 1996 paper The Lack of A Priori Distinctions Between Learning Algorithms, David Wolpert examines if it is possible to get useful theoretical results with a training data set and a learning algorithm without making any assumptions about the target variable.
What Wolpert proves in his 1996 paper (through a series of mathematical proofs) is that given a noise-free data set (i.e., no random variation, only trend) and a machine learning algorithm where the cost function is the error rate, all machine learning algorithms are equivalent when assessed with a generalization error rate (the model’s error rate on a validation data set).
Extending this logic (again, Wolpert does it with math equations), he demonstrates that for any two algorithms, A and B, there are as many scenarios where A will perform worse than B as there are where A will outperform B. This even holds true when one of the given algorithms is random guessing. Wolpert proved that for all possible domains (all possible problem instances drawn from a uniform probability distribution), the average performance for algorithms A and B is the same.
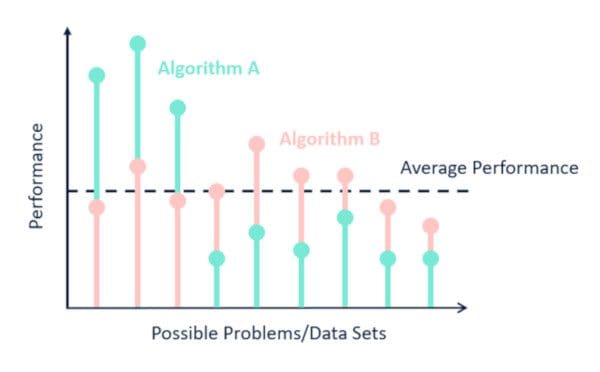
This is because nearly all (non-rote) machine learning algorithms make some assumptions (known as inductive or learning bias) about the relationships between the predictor and target variables, introducing bias into the model. The assumptions made by machine learning algorithms mean that some algorithms will fit certain data sets better than others. It also (by definition) means that there will be as many data sets that a given algorithm will not be able to model effectively. How effective a model will be is directly dependent on how well the assumptions made by the model fit the true nature of the data.
Coming back to the lunch of it all, you can’t get good machine learning “for free.” You must use knowledge about your data and the context of the world we live in (or the world your data lives in) to select an appropriate machine learning model. There is no such thing as a single, universally-best machine learning algorithm, and there are no context or usage-independent (a priori) reasons to favor one algorithm over all others.
Fun fact, this 1996 paper is a mathematical formalization of the work of the philosopher David Hume. I promise I will circle back to this a little later.
No Free Lunch for Search and Optimization Either
Wolpert and Macready’s 1997 paper No Free Lunch Theorems for Optimization demonstrates the application of similar “no free lunch” logic to the mathematical fields of search and optimization.
The No Free Lunch theorems for search and optimization demonstrate that for search/optimization problems in a limited search space, where the points being searched through are not resampled, the performance of any two given search algorithms over all possible problems is the same.
As an example, consider that you are on foot, looking for the highest point (extremum) on the earth. To find it, you would likely always make a choice to go in the direction that elevation increased, acting as a “hill-climber.”
This would work fine on Earth, where the highest point is a part of a very tall mountain range.

Now, imagine a world where the highest point on the planet is surrounded by the lowest points on the planet.
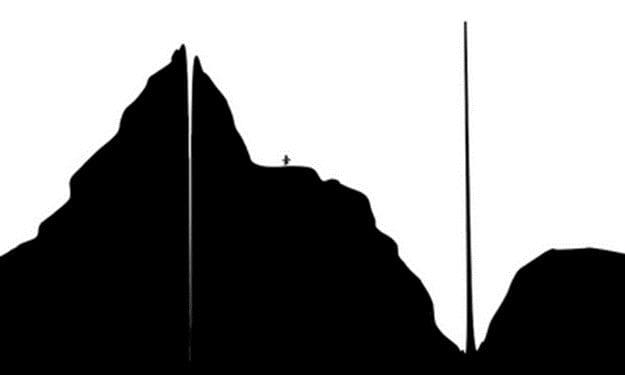
This guy is headed for disappointment.
In this scenario, a search where you always go down in elevation would perform better.
Neither hill climbing nor hill descending performs better on both planets, meaning that a random search would be just as good (on average). Without being able to assume that the highest point on a planet will occur next to other high points (a smooth surface), we can’t know that hill climbing will perform better than descending.
What this all boils down to: if no prior assumptions about the optimization program can be made, no optimization strategy can be expected to perform better than any other strategy (including random searching). A general purpose universal optimization strategy is theoretically impossible, and the only way one strategy can outperform another is for it to be specialized for the specific problem at hand. Sound familiar? There is no free efficient search optimization either.
In his 2012 paper What the No Free Lunch Theorems Really mean; How to Improve Search Algorithms, Wolpert discusses the close relationship between search and supervised learning and its implications to the No Free Lunch theorems. He demonstrates that, in the context of the No Free Lunch theorem, supervised learning is closely analogous to search/optimization. For these two theorems, “search algorithm” is seemingly interchangeable with “learning algorithm” and “objective function” with “target function.”
If you are interested in knowing more about each of the No Free Lunch theorems, there is a great summary resource on http://www.no-free-lunch.org/, including a powerpoint deck from David Wolpert on an overview of the No Free Lunch Theorems. For a more philosophical explanation of the No Free Lunch Theorem(s) give the note Notice: No Free Lunches for Anyone, Bayesians Included a read.
Are We Sure About No Free Lunch?
The No Free Lunch theorems have sparked a lot of research and academic publications. These publications are not always in favor of No Free Lunch (because who doesn’t want a free lunch)?
The “all possible problems” component of the no free lunch theorems is the first sticking point. All possible problems don’t reflect the conditions of the real world. In fact, many would argue that problems taken on by machine learning and optimization, “real world” problems, are nothing like many of the domains included in all problems. The real world tends to exhibit patterns and structures, where the “all possible problems” space includes scenarios that are entirely random or chaotic.
Researchers also argue against taking a uniform average of performance on philosophical grounds. If you have one hand in boiling water, and one hand froze in an ice block, on average the temperature of your hands is fine. Averaging performance of algorithms might cause trouble where one algorithm performs well on most problems but epically fails on a few edge cases.
In empirical research, it has been demonstrated that some algorithms consistently perform better than others. In the 2014 paper Do we Need Hundreds of Classifiers to Solve Real-World Classification Problems, researchers found that for all of the data sets in the UCI Machine Learning Repository (121 data sets), the family of classifiers that perform best includes random forest, support vector machines (SVM), neural networks, and boosting ensembles.
This is an important consideration, as it does seem that some algorithms seem to consistently top the Kaggle leaderboards or get implemented into production environments more than others. However, the No Free Lunch theorem is an important reminder about the assumptions each model makes, and the (often subconscious) assumptions we make about data and the environment it was gathered in.
No Free Lunch and David Hume
Remember when (back about 800 words) I promised I would circle back to the old dead philosopher? This is that section.

This guy…
David Hume was an 18th-century philosopher from Edinburgh, particularly interested in skepticism and empiricism. He did a lot of thinking about the problem of induction, which falls under the field of epistemology (the study of knowledge).
To get into the problem of induction, let’s first split the world into two different types of knowledge: a priori and a posteriori (this division is going back to the work of Immanuel Kant).
A priori knowledge is knowledge that exists independently of experience. This is the type of knowledge that is based on the relation of ideas, for example, 2 + 2 = 4, or an octagon has eight sides. This type of knowledge will be true regardless of what the world is like outside.
A posteriori knowledge or “matters of fact” are types of knowledge that require experience or empirical evidence. This is the type of knowledge that makes up most personal and scientific knowledge. A posteriori knowledge requires observation.
Inductive reasoning is a method of reasoning for a posteriori knowledge in which we apply observed regular patterns to instances we haven’t directly observed; e.g., all rain I have observed is wet, therefore, all rain I haven’t observed must be wet, too.
With induction, we are implicitly assuming the uniformity of nature (sometimes called the Uniformity Principle or Resemblance Principle) and that the future will always resemble the past.
Science is entirely based on inductive reasoning. Without assumptions like the uniformity of nature, no algorithm (including high-level algorithms like the scientific method or cross-validation routines) can be proven to perform better than random guessing.
Hume argued that inductive reasoning and the belief in causality cannot be rationally justified. There is no reasoning behind assuming uniformity. According to Hume, induction is instinctive for humans, like how dogs seem to instinctively chase rabbits and squirrels. Hume doesn’t really suggest a solution or justification for induction -- he kind of just shrugs and says, we can’t really help the way we are, so let’s not worry about it. (I am imagining the shrugging.)
David Wolpert’s work on the No Free Lunch theorem for supervised machine learning is a formalization of Hume. Wolpert even opens his 1996 paper with this quote from David Hume:
Even after the observation of the frequent conjunction of objects, we have no reason to draw any inference concerning any object beyond those of which we have had experience.
- David Hume, in A Treatise of Human Nature, Book I, part 3, Section 12.
Science (and machine learning models) inherently believe that under the same conditions everything always happens the same way. There is no reason to assume that because a model worked well on one data set, it will work well on other data sets. Additionally, science, statistics, and machine learning models cannot give guarantees about future experiments based on the results of previous experiments. No system can give guarantees about prediction, control, or observation in any environment.

If you’ve enjoyed the philosophy detour, and want more information on Hume and the problem of induction, there is a great video on Khan Academy called Hume: Skepticism and Induction, Part 2 (Part 1 is about a priori vs. a posteriori knowledge).
The No Free Lunch Theorem and You
If you’ve stuck with me this long, you’re probably looking for an explanation of what this all means to you. The two most important things to take away from the No Free Lunch theorems are:
- Always check your assumptions before relying on a model or search algorithm.
- There is no “super algorithm” that will work perfectly for all datasets.
The No Free Lunch theorems were not written to tell you what to do in different scenarios. The No Free Lunch theorems were specifically written to counter claims along the lines of:
My machine learning algorithm/optimization strategy is the best, always and forever, for all the scenarios.
Models are simplifications of a specific component of reality (observed with data). To simplify reality, a machine learning algorithm or statistical model needs to make assumptions and introduce bias (known specifically as inductive or learning bias). Bias-free learning is futile because a learner that makes no a priori assumptions will have no rational basis for creating estimates when provided new, unseen input data. The assumptions of an algorithm will work for some data sets but fail for others. This phenomenon is important to understand the concepts of underfitting and the bias/variance tradeoff.
The combination of your data and a randomly selected machine learning model are not enough to make accurate or meaningful predictions about the future or unknown outcomes. You, the human, will need to make assumptions about the nature of your data and the world we live in. Playing an active role in making assumptions will only strengthen your models and make them more useful, even if they are wrong.
Original. Reposted with permission.
Bio: A geographer by training and a data geek at heart, Sydney Firmin strongly believes that data and knowledge are most valuable when they can be clearly communicated and understood. In her current role as a Sr. Data Science Content Engineer, she gets to spend her days doing what she loves best; transforming technical knowledge and research into engaging, creative, and fun content for the Alteryx Community.
Related: