Version Control for Data Science: Tracking Machine Learning Models and Datasets
I am a Git god, why do I need another version control system for Machine Learning Projects?
By Vipul Jain, Applied Data Scientist

Undoubtedly, GIT is the holy grail of versioning systems! Git is great in versioning the source code. But unlike software engineering, Data Science projects have additional big-ass files like datasets, trained model files, label-encodings etc. which can easily go to the size of a few GBs and therefore cannot be tracked using GIT.
Tell me the Solution?
The amazing bunch of people at https://dvc.org/ have created this tool called DVC. DVC helps us to version large data files, similar to how we version control source code files using git. Also, DVC works flawlessly on top of GIT which makes it even better!

Most of the time, tracking of datasets and models are ignored in Data Science workflows. Now with DVC we can track all the artifacts — which will make Data Scientists a lot more productive, as we don’t have to manually keep track of what we did to achieve the state, and also we don’t lose time in the processing of data and building models to reproduce the same state.

Benefits Of DVC
- Tracks large files easily — which makes reusability and reproducibility a piece of cake
- Git compatible — Works on top of git
- Storage agnostic — Supports GCS/S3/Azure and many more to store data
Let’s get started!
Installation
Installation is quite straight-forward with the command below:
pip install dvc
To verify the installation, type dvc in the terminal and if you see a bunch of DVC command options, you are on the right track.
For the demonstration, I will be using the repository dvc-sample with the following project structure:
dvc-sample ├── artifacts │ ├── dataset.csv │ └── model.model └── src ├── preprocessor.py └── trainer.py
The repository has a simple structure; there is an src folder which will have the python scripts(version controlled by git) and artifacts folder which will have all the datasets, model files and rest of the artifacts(which are bigger and need to be controlled by dvc).
Initializing dvc
The first thing we have to do is to initialize dvc in the root of the project. We do it with the command below:
dvc init
(This is very similar to git init, we only have to do it once while setting up the project)
At this point, we have added dvc support to the project. But we still have to specify the folders which we want to version control using dvc. In this example, we will be versioningartifacts folder. We do it using the command below:
dvc add artifacts
The above statement did two things -:
- Specify which folder we want to track using
dvc
(Creating a metafileartifacts.dvc) - Add the same folder to
.gitignore
(As we don’t want to track the folder with git anymore)
After executing the above command, dvc tells us to add the above two files to git

Now we add these files to git using the commands below:
git add . git commit -m 'Added dvc files'
Note: An important thing to note here is: the meta-files of artifacts folder are tracked by git and actual artifacts files are tracked by dvc. In this case, artifacts.dvc is tracked by git, and contents inside artifacts folder are tracked by dvc.
It's okay if this is not very clear now, we will look at it closely later on.
At this point, we have added
dvcto our project along with git and have also added the folder which we want to track using dvc.
Now let’s look at a typical Machine Learning workflow(simplified version):
- We have a dataset
- We do some preprocessing on the above dataset using a python script
- We train a model using a python script
- We have a model file which is the output of step #3
Above is a repetitive process; as we use multiple datasets, with a different set of preprocessing pipelines, to build and test various Machine Learning models. And this is what we want to version control in order to easily reproduce the previous versions whenever required.
For the above scenario, we are tracking #2 and #3 using git as these are smaller code files. And track #1 and #4 using dvc, as these could be pretty big in size(up to a few GBs)
Have a look at the directory structure again for more clarity:
dvc-sample ├── artifacts │ ├── dataset.csv #1 │ └── model.model #4 └── src ├── preprocessor.py #2 └── trainer.py #3
For simplicity, at any given point — the content of each of the above 4 files will be the version they belong to.
Let’s say we have written 1st version of the preprocessor and training scripts which were used on a dataset to build the model. The 4 files look like this right now:
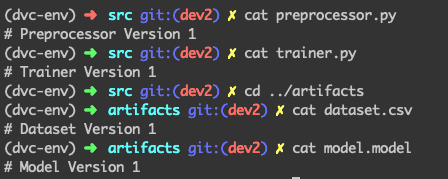
Tracking large files
Now we have to commit our code and the artifacts(dataset and model files), we do it in 3 steps:
1. We track changes inartifacts using dvc
dvc add artifacts/
(This tracks the latest version of files inside artifacts folder and modifies the meta-file artifacts.dvc)
2. We track changes in code scripts and updated meta-file(artifacts.dvc) using git
git add . git commit -m 'Version 1: scripts and dvc files'
3. Tag this state of the project as experiment01using git
(This will help us to roll back to a version later)
git tag -a experiment01 -m 'experiment01'
We have successfully saved version 1 of our scripts and the artifacts using git and dvc respectively.
Now imagine we are running a new experiment, where we have a different dataset and modified scripts. The 4 files look like this right now:

Now we repeat the same 3 steps to track Version 2.
1. We track changes inartifacts using dvc
dvc add artifacts/
2. We track changes in code scripts and updated meta-file(artifacts.dvc) using git
git add . git commit -m 'Version 2: scripts and dvc files'
3. Tag this state of the project as experiment02using git
git tag -a experiment02 -m 'experiment02'
At this stage, we have tracked the scripts and the artifacts of Version 2 as well.
Switching versions — Reproducing code and artifacts
Now comes the real test, its time to see if we can jump to any version of the two folders with ease. To start with — let’s see whats the current state of the project:
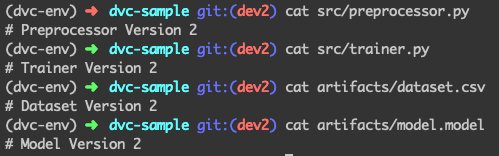
As we can see from the contents of the file, we are on Version 2 right now.
(We are looking at contents to for better intuition, in real life, we can look at git commit messages or tags)
Now let’s say we realized that version 1 was better and we want to rollback(the scripts, as well as dataset and the model) to version 1. Let’s see how we can do it with just a couple of easy commands:
1. We checkout to the experiment01 tag
git checkout experiment01
After executing the following command, the project state looks like this:
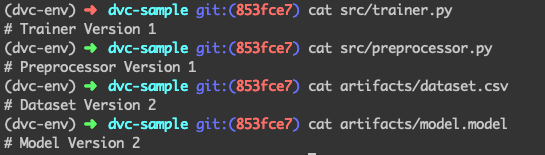
Did you notice anything?

You can see that the scripts have been changed to Version 1. Great!
But the artifacts are still on Version 2. That’s right! This is because, as of now, we have checked out using git — which has rolled back the version of code scripts and the artifacts.dvc meta-file. Now as the meta-file is already rolled back to the version we want, all we have to do to checkout using dvc
dvc checkout
This will change the files under artifacts folder as per the current version(v1) of artifacts.dvc file.
Let’s look at the files again:
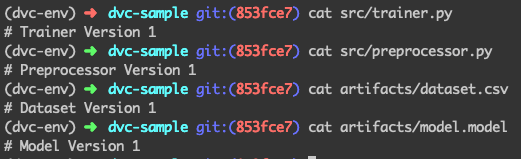
Hurray! We have successfully rolled back from version 2 to version 1 — for the scripts as well as the giant dataset and model files.

To make it simple, we have only looked at working and switching between 2 versions. The above process works exactly the same with even a few hundred experiments — giving us the power of iterating fast without maintaining manual logs while iterating or worrying about reproducing the earlier state of experiments when required.
Conclusion
DVC is a great tool to version the large files such as datasets and trained model files, exactly how we version control source code using git. It helps us with the reproducibility of artifacts of different ML experiments, saving us the time in processing data and building models.
Other Readings
- Python Basics — Classes and Objects
- Python Basics — Data Structures
- Python Basics — Handling Exceptions
- Cyclical Learning Rates — The ultimate guide for setting learning rates for Neural Networks
- Idiot’s Guide to Precision, Recall and Confusion Matrix
- Image Recognition Vs Object Detection — The Difference
Bio: Vipul Jain is a data scientist with a focus on machine learning, experience building end-to-end data products from ideation to production. Experience building experiment frameworks for A/B testing in production. Can effectively present technical concepts to non-technical stakeholders.
Original. Reposted with permission.
Related:
- How to Automate Tasks on GitHub With Machine Learning for Fun and Profit
- 5 Ways to Deal with the Lack of Data in Machine Learning
- 7 Tips for Dealing With Small Data