How to Automate Tasks on GitHub With Machine Learning for Fun and Profit
Check this tutorial on how to build a GitHub App that predicts and applies issue labels using Tensorflow and public datasets.
By Hamel Husain, Michal Jastrzębski and Jeremy Lewi
Teaser: Build a model that labels issues and launch it as a product!
Install this app on your GitHub repositories from this page.
Motivation: The elusive, perfect machine learning problem

Our friends and colleagues who are data scientists would describe the ideal predictive modeling project as a situation where:
- There is an abundance of data, which is already labeled or where labels can be inferred.
- The data can be used to solve real problems.
- The problem relates to a domain you are passionate about or the problem you want to solve is your own and you can be your first customer.
- There is a platform where your data product can reach a massive audience, with mechanisms to gather feedback and improve.
- You can create this with minimal expense and time, hopefully using languages and tools you are familiar with.
- There is a way to monetize your product if it becomes successful.
The above list is aspirational and data scientists are lucky to encounter a problem that meets all of these (the authors feel lucky if we can find a problem that satisfies even half of these!).
Enter GH-Archive & GitHub Apps: Where Data Meets Opportunity
Today, we present a dataset, platform, and domain that we believe satisfies the criteria set forth above!
The dataset: GH-Archive.
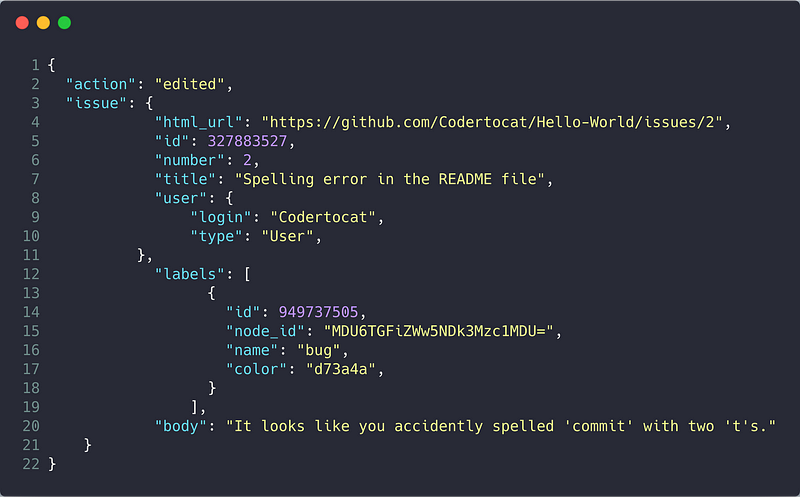
GH-Archive logs a tremendous amount of data from GitHub by ingesting most of these events from the GitHub REST API. These events are sent from GitHub to GH-Archive in JSON format, referred to as a payload. Below is an example of a payload that is received when an issue is edited:
As you can imagine, there is a large number of payloads given the number of event types and users on GitHub. Thankfully, this data is stored in BigQuerywhich allows for fast retrieval through a SQL interface! It is very economical to acquire this data, as Google gives you $300 when you first sign up for an account, and if you already have one, the costs are very reasonable.
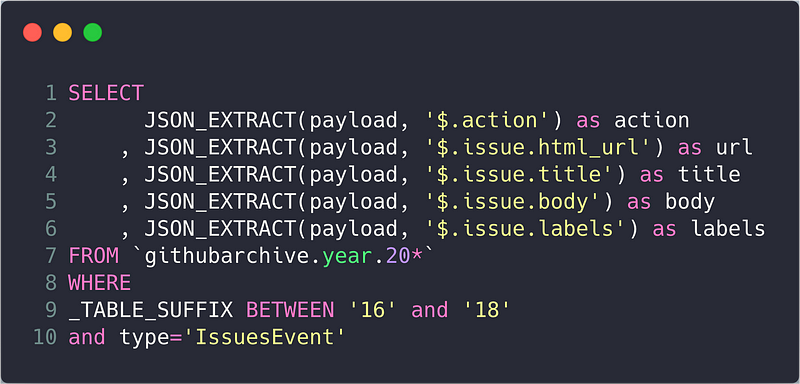
Since the data is in a JSON format, the syntax for un-nesting this data may be a bit unfamiliar. We can use the JSON_EXTRACT function to get the data we need. Below is a toy example of how you might extract data from issue payloads:
A step-by-step explanation on how to extract GitHub issues from BigQuery can be found in the appendix section of this article, however, it is important to note that more than issue data is available — you can retrieve data for almost anything that happens on GitHub! You can even retrieve large corpus of code from public repos in BigQuery.
The platform: GitHub Apps & The GitHub Marketplace
The GitHub platform allows you to build apps that can perform many actions, such as interacting with issues, creating repositories or fixing code in pull requests. Since all that is required from your app is to receive payloads from GitHub and make calls to the REST API, you can write the app in any language of your choice, including python.
Most importantly, the GitHub marketplace gives you a way to list your app on a searchable platform and charge users a monthly subscription. This is a great way to monetize your ideas. You can even host unverified free apps as a way to collect feedback and iterate.
Surprisingly, there are not many GitHub apps that use machine learning, despite the availability of these public datasets! Raising awareness of this is one of the motivations for this blog post.
An End-to-End Example: Automatically Label GitHub Issues With Machine Learning

In order to show you how to create your own apps, we will walk you through the process of creating a GitHub app that can automatically label issues. Note that all of the code for this app, including the model training steps are located in this GitHub repository.
Step 1: Register your app & complete pre-requisites.
First, you will need to set up your development environment. Complete steps 1–4 of this article. You do not need to read the section on “The Ruby Programming Language”, or any steps beyond step 4. Make sure you set up a Webhook secret even though that part is optional.
Note that there is a difference between GitHub apps and Oauth apps. For the purposes of this tutorial, we are interested in GitHub apps. You don’t need to worry about this too much, but the distinction is good to know in case you are going through the documentation.
Step 2: Get comfortable interacting with the GitHub API with python.
Your app will need to interact with the GitHub API in order to perform actions on GitHub. It is useful to use a pre-built client in the programming language of your choice in order to make life easier. While the official docs on GitHub show you how to use a Ruby client, there are third-party clients for many other languages, including Python. For the purposes of this tutorial, we will be using the Github3.py library.
One of the most confusing aspects of interfacing with the GitHub API as an app is authentication. For the following instructions, use the curl commands, not the ruby examples in the documentation.
First, you must authenticate as an app by signing a JSON Web Token (JWT). Once you have signed a JWT, you may use it to authenticate as an app installation. Upon authenticating as an app installation, you will receive an installation access token which you can use to interact with the REST API.
Note that the authenticating as an app is done via a GET request, whereas authenticating as an app installation is done via a PUT request. Even though this is illustrated in the example CURL commands, it is a detail that we missed when getting started.
Knowing the above authentication steps are useful even though you will be using the Github3.py library, as there may be routes that are not supported that you may want to implement yourself using the requests library. This was the case for us, so we ended up writing a thin wrapper around the Github3.py library called mlapp to help us interact with issues, which is defined here.
Below is code that can be used to create an issue, make a comment, and apply a label. This code is also available in this notebook.
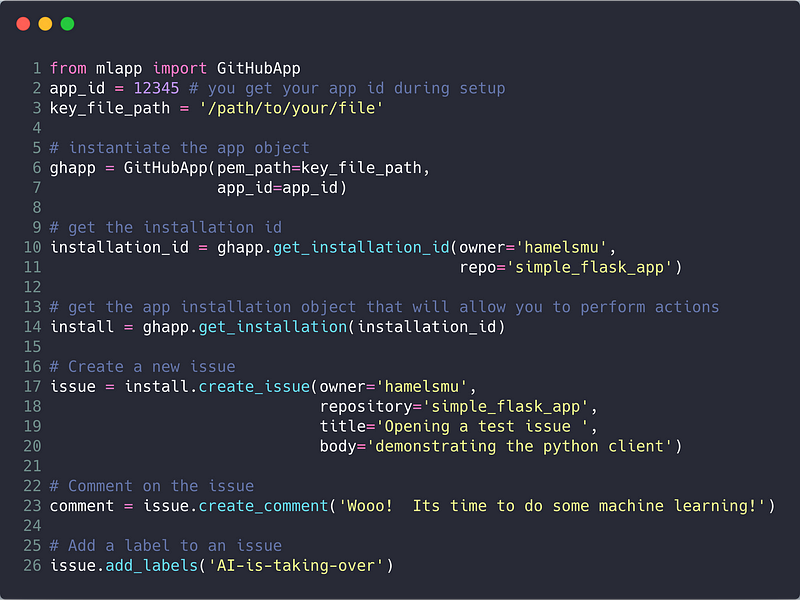
You can see the issue created by this code here.
Step 3: Acquire and prepare the data.
As mentioned previously, we can use GH-Archive hosted on BigQuery to retrieve examples of issues. Additionally, we can also retrieve the labels that people manually apply for each issue. Below is the query we used to build a Pareto chart of all of these labels:
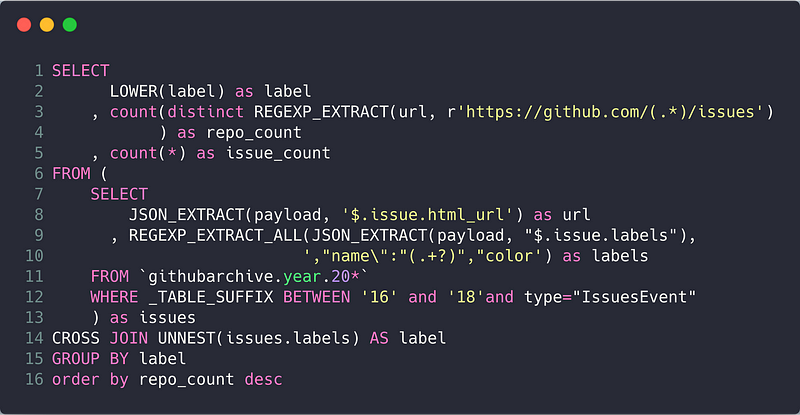
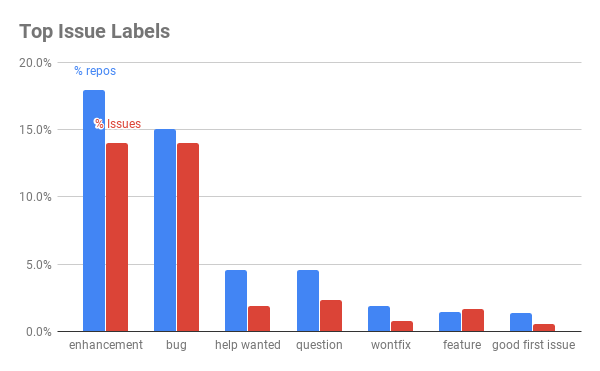
This spreadsheet contains the data for the entire Pareto chart. There is a long tail of issue labels which are not mutually exclusive. For example, the enhancement and feature labels could be grouped together. Furthermore, the quality and meaning of labels may vary greatly by project. Despite these hurdles, we decided to simplify the problem and group as many labels as possible into three categories: feature request, bug, and question using heuristics we constructed after manually looking at the top ~ 200 labels. Additionally, we consulted with the maintainers of a large open source project, Kubeflow, as our first customer to validate our intuitions.
We experimented with creating a fourth category called other in order to have negative samples of items not in the first three categories, however, we discovered that the information was noisy as there were many bugs, feature requests, and questions in this “other” category. Therefore, we limited the training set to issues that we could categorize as either a feature request, bug or question exclusively.
It should be noted that this arrangement of the training data is far from ideal, as we want our training data to resemble the distribution of real issues as closely as possible. However, our goal was to construct a minimal viable product with the least time and expense possible and iterate later, so we moved forward with this approach.
Finally, we took special care to de-duplicate issues. To be conservative, we resolved the following types of duplicates (by arbitrarily choosing one issue in the duplicate set):
- Issues with the same title in the same repo.
- Issues that have the same content in their body, regardless of the title. Removed further duplicates by only considering the first 75% of characters and alternatively last 75% of characters in an issue body.
The SQL query used to categorize issues and deduplicate issues can be viewed with this link. You don’t have to run this query, as our friends from the Kubeflow project have run this query and are hosting the resulting data as CSV files on Google Cloud Bucket, which you can retrieve by following the code in this notebook. An exploration of the raw data as well as a description of all the fields in the dataset is also located in the notebook.
Step 4: Build & train the model.
Now that we have the data, the next step is to build and train the model. For this problem, we decided to borrow a text pre-processing pipeline that we built for a similar problem and apply it here. This pre-processing pipeline cleans the raw text, tokenizes the data, builds a vocabulary, and pads the sequences of text to equal length, which are steps that are outlined in the “Prepare and Clean Data” section of our prior blog post. The code that accomplishes this task for issue labeling is outlined in this notebook.
Our model takes two inputs: the issue title and body and classifies each issue as either a bug, feature request or question. Below is our model’s architecture defined with tensorflow.Keras:
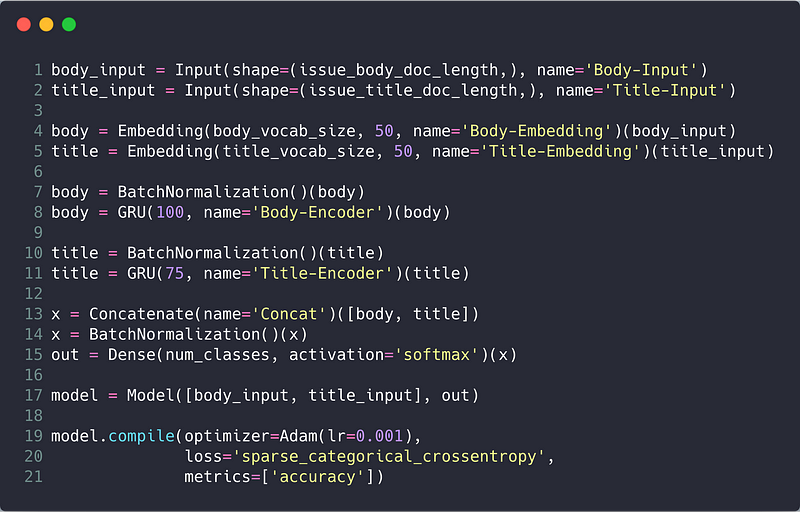
A couple of notes about this model:
- You do not have to use deep learning to solve this problem. We just used an existing pipeline we built for another closely related problem in order to quickly bootstrap ourselves.
- The model architecture is embarrassingly simple. Our goal was to keep things as simple as possible to demonstrate that you can build a real data product using a simple approach. We did not spend much time tuning or experimenting with different architectures.
- We anticipate that there is plenty of room for improvements on this model by using more state of the art architectures or improving the dataset. We provide several hints in the next steps section of this blog post.
Evaluating the model
Below is a confusion matrix showing our model’s accuracy on a test set of the three categories. The model really struggles to categorize questions but does a fairly decent job at distinguishing bugs from features.
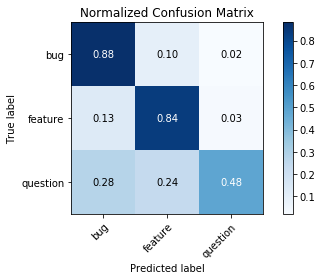
Note that since our test set is not representative of all issues (as we filtered the dataset to only those that we could categorize), the accuracy metrics above should be taken with a grain of salt. We somewhat mitigate this problem by gathering explicit feedback from our users, which allows us to re-train our model and debug problems very fast. We discuss the explicit feedback mechanism in a later section.
Making predictions
Below are model predictions on toy examples. The full code is available in this notebook.
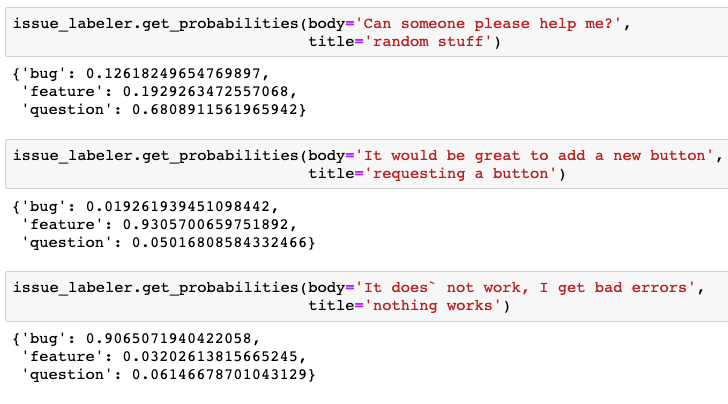
We wanted to choose reasonable thresholds so the model is not spamming people with too many incorrect predictions (this means that our app may not offer any predictions in some cases). We selected thresholds by testing our system on several repos and consulting with several maintainers on an acceptable false positive rate.
Step 5: Use Flask to respond to payloads.
Now that you have a model that can make predictions, and a way to programmatically add comments and labels to issues (step 2), all that is left is gluing the pieces together. You can accomplish this with the following steps:
- Start a web server that listens to payloads from GitHub.com (you specified the endpoint that GitHub will send payloads to when you registered your app in step 1).
- Verify the payload is coming from GitHub (illustrated by the verify_webhook function in this script).
- Respond to the payload if desired by using the GitHub API (which you learned in step 2).
- Log appropriate data and feedback you receive to a database to facilitate model retraining.
A great way to accomplish this is to use a framework like Flask and database interface like SQLAlchemy. If you are already familiar with flask, below is a truncated version of the code that applies predicted issue labels when notified by GitHub that an issue has been opened:
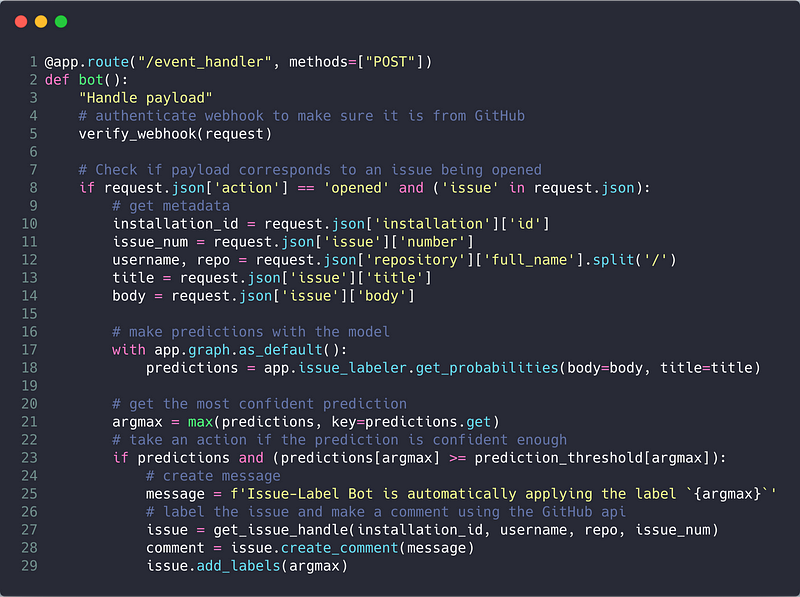
Don’t worry if you are not familiar with Flask or SQLAchemy. You can learn everything you need to know about this subject from this wonderful MOOC on Flask, HTML, CSS and Javascript. This course is a really great investment of time if you are a data scientist, as this will allow you to build interfaces for your data products in a lightweight way. We took this course and were impressed with it.
We leave it as an exercise for the reader to go through the rest of the flask code in our GitHub repository.
Collecting explicit user feedback.
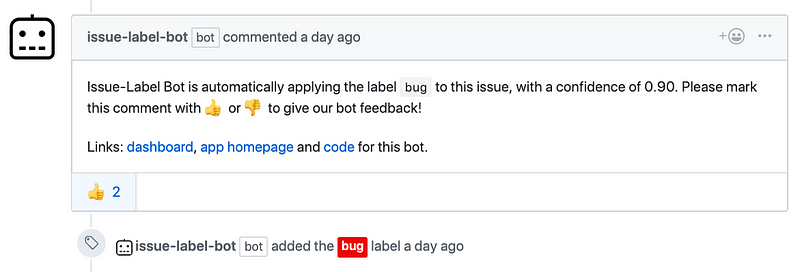
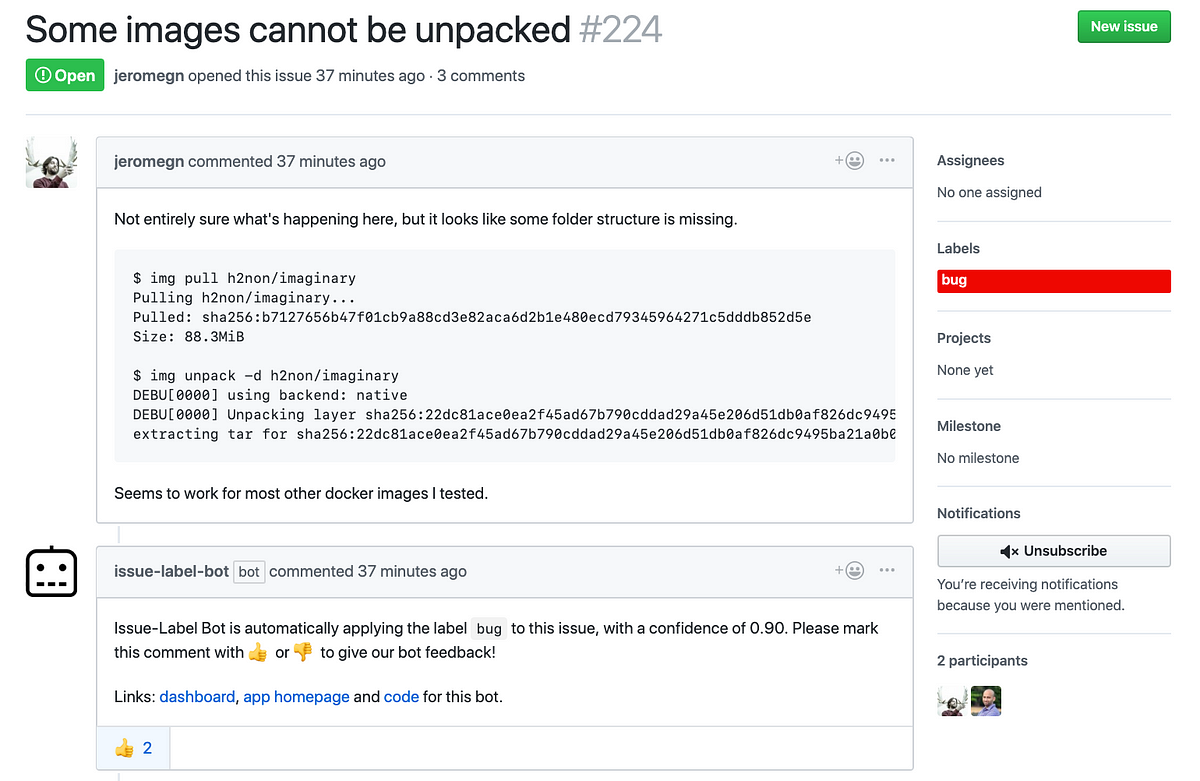
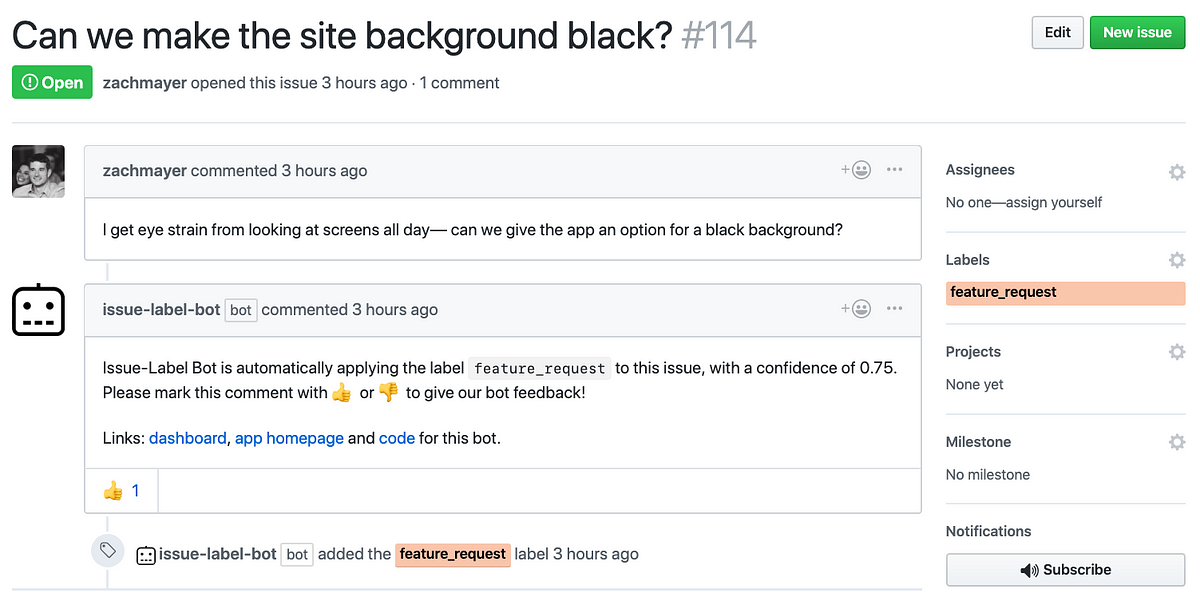
As illustrated above, explicit feedback is requested by asking users to react with ???? or ???? to a prediction. We can store these reactions in a database which allows us to re-train and debug our models. This is is perhaps one of the most exciting and important aspects of launching a data product as a GitHub App!
You can see more examples of predictions and user feedback on our app’s homepage. For example, this is the page for the kubeflow/kubeflow repo:
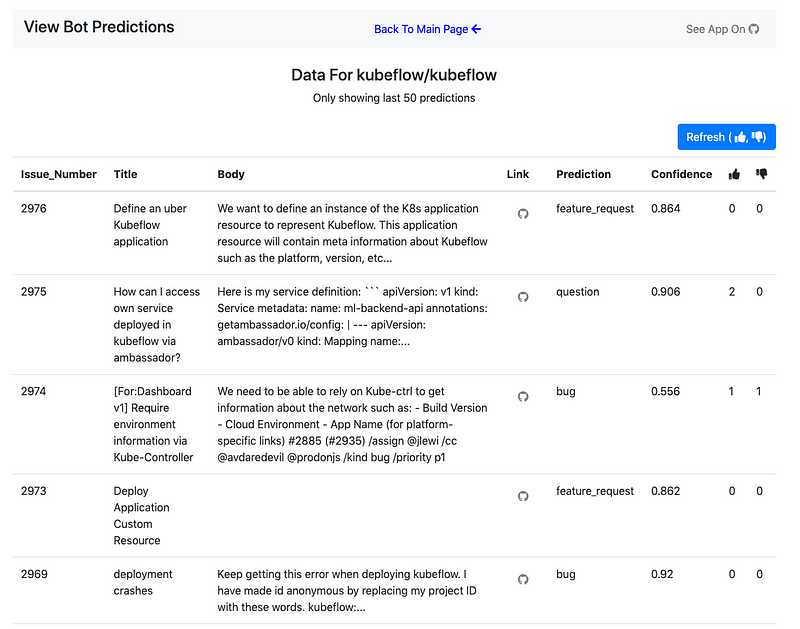
Please install our app, it’s free!
If you enjoy what you have read thus far and want to support this project, please install this app on your public repositories (this app will not make predictions on private repos even if installed there), and give our bot feedback when it makes predictions ???? ????.
Here is the link to install our app.
Conclusion: Tips for building your own machine learning powered apps
- Don’t be afraid to use public datasets. You can do a lot more than just label issues (see the resources section for ideas).
- Don’t be afraid to iterate fast, even if the solution is not perfect. Building a model is sometimes the smallest component of a project and getting user feedback is very valuable so you do not waste time.
- Try to consult with at least one real customer or user and have them guide and validate decisions.
- Take advantage of opportunities to gather explicit user feedback. This will allow you to improve your solution and your models quickly.
Part II & Next Steps
One aspect we did not cover is how to serve your app at scale. When you are just starting out, you probably do not need to worry about this and can serve this on a single server with your favorite cloud provider. You can also use a service like Heroku, which is covered in the course on Flask linked in the resources section below.
In Part II, we will cover the following:
- How to deploy your Flask app on Kubernetees so it can scale to many users.
- Using Argo pipelines to manage the model training and serving pipeline.
We believe there are many opportunities to improve upon the approach we illustrated in this post. Some ideas we have in mind are:
- Constructing better labels and negative samples of items that do not belong in the label set.
- Using the tools from fastai to explore state of the art architectures, such as Multi-Head Attention.
- Pre-training on a large corpus and fine tuning that on GitHub issues to enable a user to predict repo-specific labels instead of a small global set of labels.
- Using additional data such as information about the repository or the user opening the issue, perhaps learning an embedding for these entities.
- Allow users to customize the label thresholds and the names of labels, as well as choose which labels to predict.
Resources
- Our app’s website.
- The installation page of our app.
- The GitHub repository with all of this code.
- Need inspiration for other data products you can build using machine learning and public GitHub datasets? See these examples: (1) GitHub issue summarization and (2) Natural language semantic code search.
- This public data provided by stack exchange could be useful for transfer learning. A cool machine learning project that recently leveraged this data is stackroboflow.com.
- Machine Learning on Source Code, a survey of the literature on applications of applying machine learning to code, by Miltos Allamanis.
- Excellent course on flask: HarvardX CS50 Web.
- MOOCs by fastai for machine learning and deep learning.
- The code in our repo and associated tutorial(s) assume familiarity with Docker. This blog post offers a gentle introduction to Docker for data scientists.
- The Kubeflow project contains resources that we will use in part 2 of this blog post. Furthermore, the content of this blog post will be the subject of this upcoming talk on April 17, 2019.
Get In Touch!
We hope you enjoyed this blog post. Please feel free to get in touch with us:
Disclaimer
Any ideas or opinions presented in this article are our own. Any ideas or techniques presented do not necessarily foreshadow future products of any company. The purpose of this blog is for educational purposes only.
Original. Reposted with permission.
Related:
- Synthetic Data Generation: A must-have skill for new data scientists
- Trending Deep Learning Github Repositories
- Comparing MobileNet Models in TensorFlow