Data Anonymization – History and Key Ideas
While effective anonymization technology remains elusive, understanding the history of this challenge can guide data science practitioners to address these important concerns through ethical and responsible use of sensitive information.
By Nicolas Sartor, Aircloak.
“'Anonymized' Data Can Be Anything But’” – Forbes, July 24, 2019
When the world media reported the results of a recent scientific paper on the ineffectiveness of data anonymization, it was anything but news.
- Already in 1981, the US computer scientist Dorothy E. Denning stated in one of her scientific papers on database security that when working with data, it can probably never be completely ensured that no sensitive information is revealed.
- In 2008, scientists Arvind Naranayan and Vitaly Shmatikov published their work on the now-infamous Netflix de-anonymization case. The researchers succeeded in re-identifying a supposedly anonymous data set released by Netflix. And the headlines? “Why 'Anonymous' Data Sometimes Isn’t”.
- In August 2009, Paul Ohm’s paper “Broken Promises of Privacy: Responding to the Surprising Failure of Anonymization”was published. His sober conclusion was: “Data can be either useful or perfectly anonymous but never both.”
It seems as if history repeats itself constantly. And this raises a big question:
Why, after decades of intensive research and thousands of scientific publications, has no data anonymization technology that is generally usable by non-experts been developed thus far?
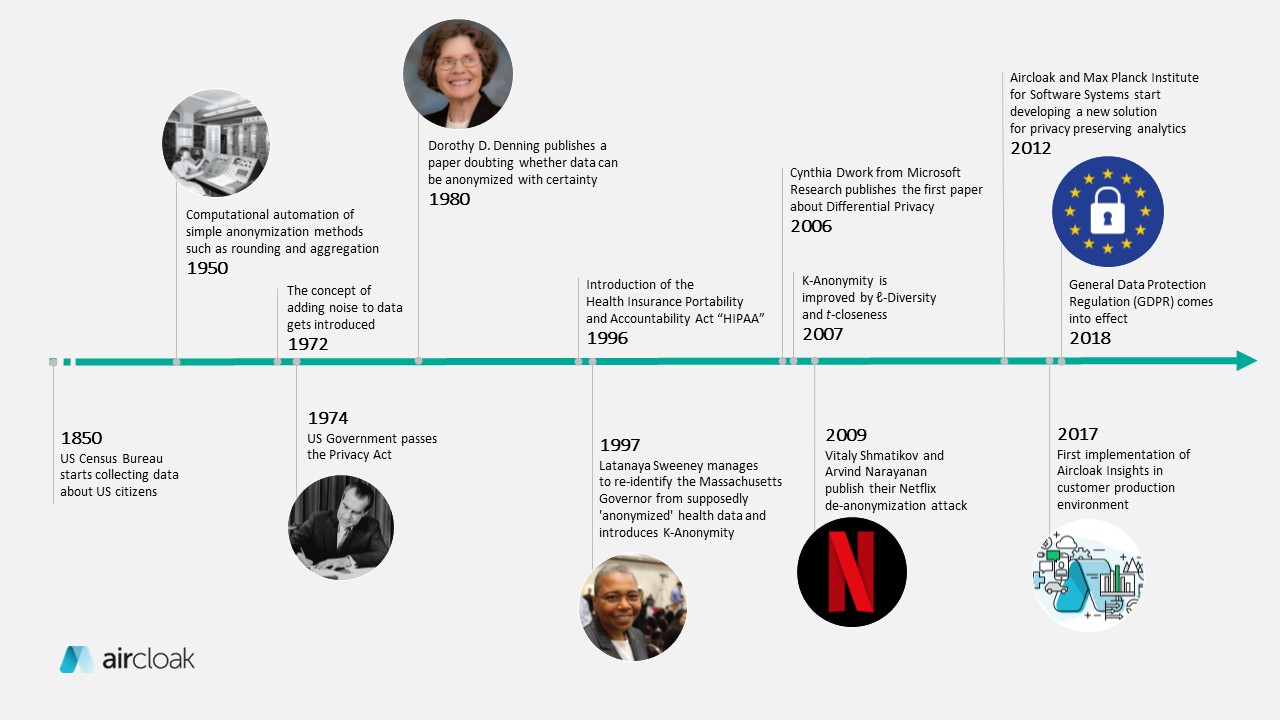
Timeline on the history of data anonymization.
In order to answer this question, we need to delve into the past. Let us look at the development of anonymization in a broad context. This history touches on research, business, politics, and public opinion, as well as mathematics, statistics, information technology, ethics, and sociology. Above all, it is characterized by a permanent conflict:
The constant tension between data protection and data quality.

Privacy vs. Utility Trade-off: The better the data utility has to be, the worse gets the privacy and vice versa.
The Beginnings of Data and Confidentiality
One of the first institutions to use data on a large scale was the US Federal Bureau of Statistics (Census Bureau). At the beginning of the 19th century, censuses were conducted at regular intervals to determine how seats in the House of Representatives needed to be redistributed, what taxes could be levied on each state, and what the country’s military potential was in the event of war.
During this time, data protection hardly played a role. The first 50 years of census taking is notable for the absence of concern about privacy. This changed around 1850 when census questions increased in both number and degree of sensitivity. As a security measure, the Census Bureau began to remove personal data from publicly available census data.
Over the ensuing decades, the bureau used a variety of techniques to mitigate the risk of individuals being identified in the released data. These techniques include rounding, adding random noise to values, aggregation, cell suppression, cell swapping, and sampling, among others.
In the 1950s, the bureau started using computers to tabulate data, and by the 1960s, anonymization techniques like those mentioned above were being automated. Computers enabled analysts to “cross-tabulate” data (set filter conditions on queries). This tremendously increased an analyst’s ability to analyze the data but also opened the possibility that an analyst could specify a query that uniquely identifies an individual.

One of the first computers that was used by the US Census for automated statistics: UNIVAC I (Credit: en.wikipedia.org).
The debate on data protection started in the early 1960s. The US government under John F. Kennedy planned to set up a National Data Centre to further improve the state information system. The public viewed this as heavy interference in the constitutional “Right to be alone” and “Right to privacy.” The project failed and triggered demands for a legal basis for the processing of personal data. The eventual result was the adoption of the Privacy Act in 1974, which introduced rules for data processing for federal authorities containing the essential principles of data protection: Necessity, Security, and Transparency.
The American debate was repeated in Europe. In 1970, the Hessian Data Protection Act was introduced, regarded as the oldest data protection law in the world. It regulated when the public administration of the German State of Hesse may process personal data and which requirements it must observe in doing so. Based on the public discussions about data protection, research into anonymization was also intensified. This was the beginning of a cycle that still persists:
Originally, only simple data is published. But over time, increasingly sophisticated data is released. To secure that data, new anonymization methods are invented, but each time researchers find a way to bypass them.
One concept that promised to cope with greater complexity and data diversity was the addition of noise. The earliest publication we found that proposes adding noise is from the statistician, Fellegi, in 1972. Of course, noise must be unpredictable and, therefore random. In the context of a query-based system, this creates a difficulty. If each answer produced has a new zero-mean random noise sample, then an analyst need only repeat the query multiple times and take the average to eliminate the noise.
Researcher Dorothy E. Denning proposed seeding the random number generator with the contents of the query itself. But even she recognized that this approach was easy to break.
Noisy Data (Credit: matlab-monkey.com).
Denning never explored this problem further and stopped working on data anonymity altogether. In fact, by the mid-1980s, the entire computer science community had lost interest in data anonymity. That was partly because it was a difficult problem, but primarily because the research community had far more pressing problems to work on.
The Renaissance of Data Anonymization
Fast forward around 15 years, and data anonymization becomes a hot topic in Computer Science again. In 1997, Latanaya Sweeney managed to re-identify the then Massachusetts Governor William Weld from supposedly ‘anonymized’ health data. In his paper “Broken Promises of Privacy,” University of Colorado law professor Paul Ohm describes the case.
“At the time the Massachusetts Group Insurance Commission (GIC) released the data, William Weld, then Governor of Massachusetts, assured the public that GIC had protected patient privacy by deleting identifiers. In response, then graduate student Sweeney started hunting for the Governor’s hospital records in the GIC data. She knew that Governor Weld resided in Cambridge, Massachusetts, a city of 54,000 residents and seven ZIP codes. For twenty dollars, she purchased the complete voter rolls from the city of Cambridge, a database containing, among other things, the name, address, ZIP code, birth date, and sex of every voter. By combining this data with the GIC records, Sweeney found Governor Weld with ease. Only six people in Cambridge shared his birth date, only three of the men, and of them, only he lived in his ZIP code. In a theatrical flourish, Dr. Sweeney sent the Governor’s health records (which included diagnoses and prescriptions) to his office.”

Latanaya Sweeney and William Weld (Credit: blackcomputeher.org and bostonherald.com).
Sweeney’s results had a significant impact on privacy-centered policy-making including the health privacy legislation HIPAA, but she also introduced the formal K-Anonymity model to overcome the shortcomings of older anonymization methods. The model was subsequently enhanced by additions called ℓ-Diversity and t-closeness. Researchers and analysts moved a step closer to the goal of being able to analyze data in a privacy-preserving way. Unfortunately, generating the anonymized data and balancing it with reasonable utility was still a very complex manual process and error-prone.
As a result, in many practical applications, the strength of anonymization was sacrificed in favor of higher data usability. This approach even had legal backing. The 1974 German Federal Data Protection Act defined anonymization as follows:
“Anonymization is the alteration of personal data […] so that the individual information about personal or factual circumstances can no longer be attributed to an identified or identifiable natural person, or can only be attributed with a disproportionately large expenditure of time, cost and labor.”
Due to this wording, the term “factual anonymization” was coined. It was already clear at that time that no anonymization procedure can guarantee privacy. So, the disclosure of sensitive information could not completely be excluded in the case of “factual anonymization,” but it required a disproportionately large effort on the part of an attacker.
The “disproportionality” was mostly determined by economic aspects but was not defined precisely. It was in a legal grey area – there was neither an official authority that could check anonymization processes nor legal consequences for insufficient anonymization.
A Way out of the Dilemma…?
In 2006 the supposed “Game Changer” was introduced. Cynthia Dwork of Microsoft Research published a paper on a concept called 'Differential Privacy'. Similar to K-Anonymity, Differential Privacy is not an anonymization method, but a mathematical model of privacy. However, the groundbreaking news was that you could now calculate, and thus formally prove, how anonymous a person was in a data record. Researchers, practitioners, and lawyers were (and still are) extremely impressed by this model.
Over the years that followed, the research community and the general public became increasingly convinced that differential privacy is the only resilient concept that can offer a way out of the privacy vs. utility dilemma.
It took another eight years for the theory to be put into practice. In 2014, Google began to collect differential private user statistics in Chrome. Two years later, Apple followed suit and used differential privacy for user data from iPhones. But again it didn’t take long to get back to the well-known problem of utility vs. privacy.
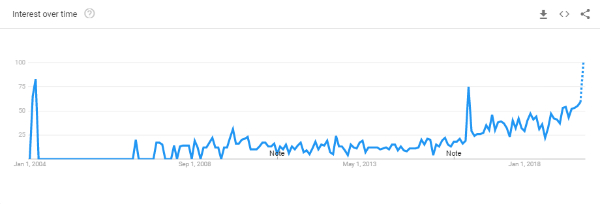 Differential Privacy becomes a thing – Google Trends for ‘Differential Privacy” since 2004 with a spike in 2016, resulting from Google’s and Apple’s implementation.
Differential Privacy becomes a thing – Google Trends for ‘Differential Privacy” since 2004 with a spike in 2016, resulting from Google’s and Apple’s implementation.
Differential Privacy uses a parameter called epsilon to determine the degree of privacy. In order for data to be protected, this parameter must remain very low. Epsilon directly limits the number of queries you can make. A data set with a low (and secure) epsilon < 1 can only be queried a few times (usually around a few 10s of queries in total). After that, access to the data is no longer permitted, as privacy cannot be guaranteed.
The Wired article “How One of Apple’s Key Privacy Safeguards Falls Short” highlights the problem:
“[…] the research team determined that MacOS’s implementation of differential privacy uses an epsilon of 6, while iOS 10 has an epsilon of 14. As that epsilon value increases, the risk that an individual user’s specific data can be ascertained increases exponentially.
“According to differential privacy co-inventor McSherry, academics generally see any value of epsilon over one as a serious privacy compromise. iOS and macOS send that data back to Apple once a day; McSherry says the risk increases with every day’s upload. “Anything much bigger than one is not a very reassuring guarantee,” McSherry says. “Using an epsilon value of 14 per day strikes me as relatively pointless as a safeguard”.
Many other differential privacy implementations share this problem. Mostly, when trying to preserve data usability, a much higher epsilon is chosen, and data protection is sacrificed.
Google’s recently released open-source library, which is designed to allow analysts around the world to use differential privacy, also gives users a free hand in choosing the epsilon:
“Epsilon is a configurable parameter. A lower value means more privacy but less accuracy.”
The coming months will show how effectively Google’s open-source library for Differential Privacy is used in practice. The fear remains that users will decide in favor of high data usability and against data security, as already shown in the past when dealing with other anonymization methods.
Sacrificing the Good for the Perfect
In 2005, German statistics professor Rainer Lenz coined the term “data protection idealist” to describe one of the biggest problems in statistics and data anonymization: the discrepancy between theory and practice.
“…the case of the data protection idealist can […] not be considered relevant. Rather, it represents a special case in which […] the attacker is not interested about the value of the information that is […] revealed by him, but by showing that deanonymization […] is possible. A data protection idealist will accept much higher costs because disclosure as such is important to him. This cost-benefit relation is outside of the reasonable framework and therefore, cannot be considered.”
If the past decades have shown us anything, it is that perfect and usable anonymization doesn’t exist. The use cases are too different, the technical progress too fast, the IT infrastructures too heterogeneous, and the questions in analyses too complex for any theoretical model to be transferred into practice.

(Credit: pilarsola.com).
Of course, it is difficult to convince an overwhelming majority of researchers, lawyers, and other experts that even differential privacy is not the magic bullet that has been claimed. It may take years for the public image of a “data protection ideal” and the attitude towards “perfect data anonymization” to change again.
Who is it to blame? Privacy and personal data are highly emotive issues. Nobody wants their own information, such as patient files or bank transaction data to be made public. Moreover, according to data protection researchers Arvind Naranayan and Vitaly Shmatikov, the problem lies not only in the individual case but also in social dimensions:
“We have also come to better recognize that these aggregations of data may result in harms to society and democracy, rather than just to individuals, as illustrated by Cambridge Analytica’s activities.”
Breaking the Age-Old Cycle of Nonsense
But how can we prevent ourselves from continuing to go round in circles or from completely freezing given the complexity of the problem?
Our (short) answer is absolute transparency and continuous development.
When we founded Aircloak in 2014, we set the goal of replacing the slow and error-prone processes of anonymizing data with an automated solution. We rely on an empirical rather than a formal approach, which is essentially based on four principles:
- Use strong criteria for anonymity
- Establish and maintain a “no known attacks” stance
- Full transparency
- Encourage active public oversight
We accept that no usable form of anonymization provides a full guarantee. To ensure that Aircloak remains state-of-the-art at all times and complies with the anonymization standards of GDPR, we have introduced the world’s only bug bounty for an anonymization method with the Aircloak Attack Challenge. We encourage privacy experts to test and attack our anonymization. Any vulnerabilities that are identified in our software are immediately investigated, and we release a patch as soon as possible.
This ensures that our customers can rely on a very high degree of anonymization, while their data remains usable without any need for expert knowledge.
Yves-Alexandre de Montjoye, Assistant Professor of Data Protection at UCL London and a member of the Belgian data protection supervisory authority, also suggests that Privacy Enhancing Technologies should take a proven model from IT-Security: the adversarial approach.
“For the researchers, the key takeaway from the work is that a change of mindset is needed around privacy protection akin to the shift the security industry underwent in moving from sitting behind a firewall waiting to be attacked to adopting a pro-active, adversarial approach that’s intended to out-smart hackers.
“As a community to really move to something closer to adversarial privacy,” de Montjoye tells TechCrunch. “We need to start adopting the red team, blue team penetration testing that has become standard in security.
“At this point it’s unlikely that we’ll ever find a perfect system, so I think what we need to do is how do we find ways to see those vulnerabilities, patch those systems and really try to test those systems that are being deployed — and how do we ensure that those systems are truly secure?”
We are, therefore, very thankful when third parties engage in our solution through the Attack Challenge and help to make it safer. We believe that the ethical and responsible use of sensitive information is definitely possible and hope that Aircloak Insights contributes to that goal.
Original. Reposted with permission.
Related: