 The Last SQL Guide for Data Analysis You’ll Ever Need
The Last SQL Guide for Data Analysis You’ll Ever Need
 The Last SQL Guide for Data Analysis You’ll Ever Need
The Last SQL Guide for Data Analysis You’ll Ever NeedThis is it: the last SQL guide for data analysis you'll ever need! OK, maybe it’s actually the first. But it’ll give you a solid head start.
By Muhsin Warfa, Systems Developer/Technical Writer

By 2020, it’s estimated that 1.7 MB of data will be created every second for every person on earth. Absurd! Data is going to be the new oil of our digital era. The growth of data creates a need to make meaning out of it. This has spawned many professions which manage and analyze data to make smarter business decisions. Many of these professions require you to be proficient in managing data in databases.
Introduction
A common way to manage data is with a relational database management system. A relational database stores data in a tabular form consisting of rows and columns. These databases usually consist of both data and metadata. Data is the information stored in the tables while metadata is the data that describes the data’s structure or data types within the database.
To be able to communicate with these databases directly, we use SQL, which is an abbreviation for Structured Query Language. SQL is used to perform tasks such as creating, reading, updating, and deleting tables in a database.
SQL is a declarative and domain-specific language mostly used by business analysts, software engineers, data analysts, and many other professions that make use of data. You don’t need to be a programmer or know programming languages such as Python to master SQL. SQL’s syntax is similar to English. With a little bit of memorization of simple syntax, you’re ready to work comfortably with database systems.
“Declarative programming is where you say what you want without having to say how to do it. With procedural programming, you have to specify exact steps to get the result.” — Stack Overflow
My objective in this article is to get you comfortable with SQL and to cover SQL concepts individually while simultaneously coming up with queries to handle the database.
Database Setup
In this tutorial, we won’t use an RDBMS (relational database management system), but rather use a test database to write our own queries. We’ll edit the test database using W3school’s SQL editor found here. It requires no installation so we can just focus on writing queries.
Cheatsheet
Since SQL is a declarative language, it’ll help immensely if we memorize the SQL statements. Having a reference guide nearby at all times will help quickly grasp the keywords used in querying the tables. Here is a spreadsheet of keywords that I created for reference. Remember, half the battle of leashing this SQL beast is memorizing/knowing the keywords.
Data Definition Language (DDL)
Most of our queries will involve some form of action to be performed on a table. Actions fall into four categories: creating, inserting, updating and deleting tables.
Creating a table
When we want to create tables in a database, we use the CREATE TABLEstatement. Type the following code into the editor:
CREATE TABLE Countries(
Country_id int,
Country_name varchar(255),
Continent varchar(255),
Population int
);
This creates a table named countries that has four columns. The minimum that is required to create a table in SQL is to state the column name, the data types, and length. You can, of course, have more characteristics such as Not Null meaning an empty value won't be entered in the table, but these are optional attributes.
Working with Tables
Insert a table
After creating a table we can insert rows by using the INSERT INTOmethod statement. Type in the following code:
INSERT INTO countries(Country_id,Country_name, Continent,Population) VALUES (1,'Somalia','Africa',14000000);
This statement adds Somali as a new country into the countries table. It is a good practice to specify the column names and values when inserting rows into the table.
Read a table
When we want to look up the data that we stored in the database, we use the Select statement.
Select * from Countries;
This statement returns a table that displays the row we just inserted with our insert statement. The * wildcard means “show me all the rows in the table.” If you want your table to only display the Population column we remove the asterisk and replace it with its column name.
Select Population from Countries;
Update a table
If we want to modify existing records in a table we use the UPDATE statement to do so.
UPDATE Countries SET Country_name ='Kenya' WHERE Country_id=1;
This statement updates thecountry_name column in the row with the country_id of 1 to Kenya. We have to specify which country ID, because we only want to change that row. If we remove the WHERE statement, SQL will assume that we want to update all the rows in the table.
Delete records in a table
If we want to delete all rows in a table, we would then use a DELETE FROM statement.
DELETE FROM Countries;
If you want to delete the table instead of all records, we use the DROP TABLE statement.
DROP TABLE Countries;
Note: This removes the whole table from the database and can result in loss of data!
Filters
If we’re only interested in part of the data in the table we can filter the table. We have multiple statements that allow us to filter our tables. Filters basically select rows that match certain criteria and return the results back as a filtered data set. Filtering tables does not mutate the original table.
WHERE
The WHERE clause is used to filter records. In our editor we have a table called Customers. If we want to filter customers that are from country “USA” we use the WHERE statement.
SELECT * from Customers WHERE country = "USA";
AND, OR, and NOT
In our previous example, we had only one condition which was “where country is USA.” We can also combine multiple conditions using AND, OR, and NOT. For example, if you want customers from the USA or Brazil, you use the OR statement.
SELECT * from Customers WHERE country = "USA" OR country = "Brazil";
ORDER BY
Most of the time when we filter the table, the data set we get back is unsorted. We can sort this filtered unsorted data set using an ORDER BY statement.
SELECT * from Customers WHERE country = "USA" OR country = "Brazil" ORDER BY CustomerName ASC;
This will order the filtered results alphabetically . If we want to sort it descending, we replace ASC with DESC.
BETWEEN
Sometimes we would like to select rows whose values satisfy a specific range. We use the BETWEEN statement to select and choose the range.
SELECT * from Products WHERE Price BETWEEN 10 AND 20;
The statement above filters products whose price falls between 10 and 20.
Note: In a BETWEEN operation, the lower bound and upper bound are both inclusive in nature.
LIKE
Sometimes we want to filter the table with a specific pattern in mind. To do so we use the LIKE statement.
SELECT * from Customers WHERE CustomerName LIKE 'A%';
The SQL statement above filters the table to show only customers whose name begin with the letter A. If you bring the percentage sign forward it would filter customers whose name ends with the letter A.
GROUP BY
GROUP BY groups the filtered result set into groups. Think of it as a summary group for each column data set.
SELECT COUNT(CustomerID), Country FROM Customers GROUP BY Country;
This statement counts the number of customers from each country, then groups it into countries. GROUP BY is mostly used with aggregate functions which we’ll talk about in detail later in the article.
HAVING
HAVING was introduced because the WHERE statement doesn’t work with aggregate functions; it only deals with direct values in the database.
SELECT COUNT(CustomerID), Country FROM Customers GROUP BY Country HAVING COUNT(CustomerID) > 3;
This statement does the same thing as the last example. The only difference is that we only include countries that have more than three customers.
Joins
Imagine you’d like to know which customer ordered what products. If a database follows a proper database normalization technique, then products, customers, and orders would be in separate tables. If we want to see which customer ordered what products, we would then have to look at the customer ID inside the order table, then go to the customer table and see the products purchases, then use the product ID to look up the product table. As you can see, this is a huge headache if were to repeat it multiple times. In order to do this more easily, SQL has a statement called JOIN.This clause is used to combine two or more rows of tables based on a shared related column.
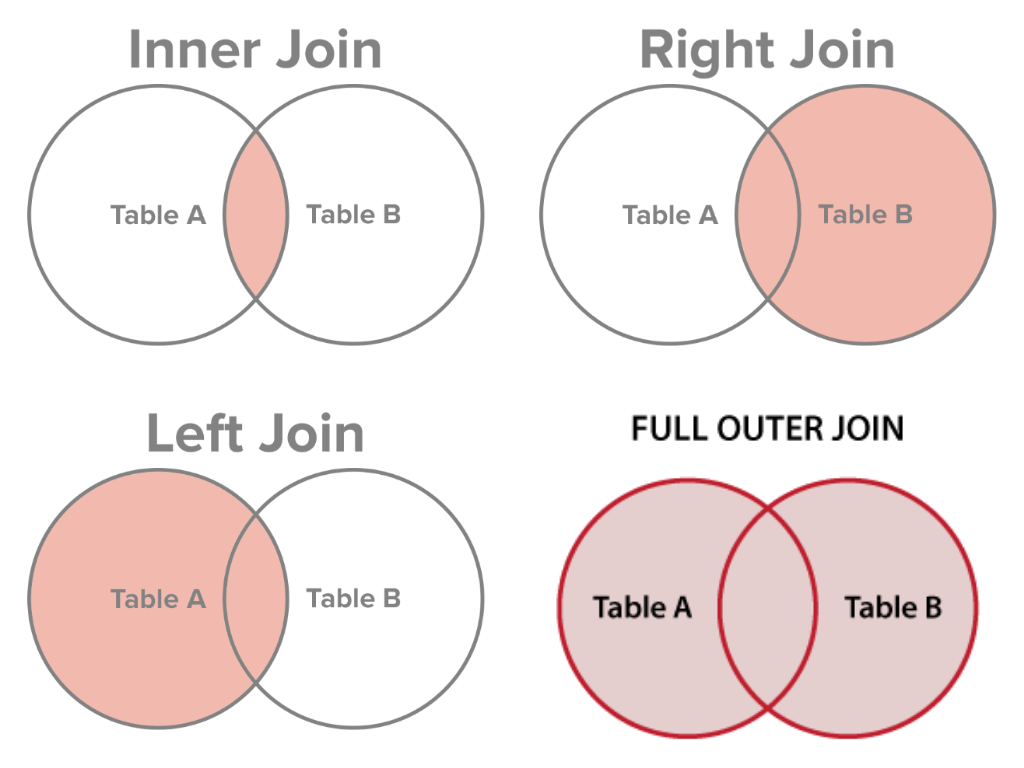
INNER JOIN
INNER JOIN, commonly known as just “JOIN,” is used to merge related tables at a shared column into a single table.
SELECT Orders.OrderID, Customers.CustomerName FROM Orders INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerID;
The statement above returns the column’s order ID and customer names. We join the table orders (left) and customers (right), but only rows that have matching customer IDs. Re-read this sentence while looking at the inner join Venn diagram and hopefully this will be easier to grasp.
LEFT JOIN
SELECT Customers.CustomerName, Orders.OrderID FROM Customers LEFT JOIN Orders ON Customers.CustomerID = Orders.CustomerID ORDER BY Customers.CustomerName;
The LEFT JOIN statement, we join the left table (customer) and right table (order) returns all rows from the left table and matching records from the right table.
RIGHT JOIN
SELECT Orders.OrderID, Employees.LastName, Employees.FirstName FROM Orders RIGHT JOIN Employees ON Orders.EmployeeID = Employees.EmployeeID ORDER BY Orders.OrderID;
RIGHT JOIN returns all rows from the right table and matched records from the left table. This returns all employees and any order they might have placed.
OUTER JOIN
SELECT Customers.CustomerName, Orders.OrderID FROM Customers FULL OUTER JOIN Orders ON Customers.CustomerID=Orders.CustomerID ORDER BY Customers.CustomerName;
Also known as FULL OUTER JOIN and is used to combine all rows from one or more tables. No rows will be left out, all will be included in the joined tables.
SQL Aggregate Functions
A function is a set of procedures that takes an input and spits out an output. A SQL function is basically a set of SQL statements that takes an input, performs SQL actions on the input, then gives back the results as an output.
There are two types of functions in SQL: set functions and value functions. Any function that manipulates rows of data in a table and returns a single value is called a set function. Programmers usually call them aggregate functions because they take rows in the table and return an aggregation of information.
MIN
SELECT MIN(Price) AS LeastPricy FROM Products;
This SQL function returns the least expensive price of all the products in the Products table.
MAX
SELECT MAX(Price) AS MostExpensive FROM Products;
This SQL function returns the most expensive price of all the products in the Products table.
AVG
SELECT AVG(Price) AS AveragePrice FROM Products;
This SQL function returns the average price of all the products in the Products table.
COUNT
SELECT COUNT(ProductID) FROM Products;
This returns the number of products in the Products table.
SUM
SELECT SUM(Quantity) FROM OrderDetails;
This returns the sum of all the orders in the Order Details table.
Indexes
So far, all the queries that we’ve looked at are basic queries. Practically speaking, the queries that we execute in our day to day life usually consist of a combination of multiple SQL statements or functions. When operations are complex, this will lower the execution time of the queries.
Luckily, SQL has something called indexing which allows for faster lookup time. An index is a data structure that has a pointer to the data in a table. Without an index, the searching data in a table would be linear meaning it would go through one row after the other. Indexing is well suited for tabular data.
Creating an index
CREATE INDEX idx_lastname ON Persons (LastName);
This will create an index to look up data from the column quickly. It is to be noted that indexes are not stored in the table and are invisible to the naked eye. We most often use indexes when we have a lot of data retrieval on tables.
Database Transactions
Transactions are a collection of of SQL statements that must be executed for a successful operation. Transactions are all or nothing kinds of operations. If all but one operation fails, we consider that transaction to have failed.
A common example of the use of transactions is transferring money from one account to another in a bank. In order for a transfer to be successful money must be removed from account A and added to account B. Otherwise, we would roll back the transaction to start fresh. When the transaction is complete we say that the transaction is committed. This ensures the database maintains data integrity and consistency.
If you want to learn about database transactions in-depth, I suggest you take a look at this excellent video explanation of database transactions.
Database Triggers
Not all SQL queries are individual and isolated. Sometimes we would like to perform an action on table A when a different event happens to another table B. This is where we get to use a database trigger.
A database trigger is a bunch of SQL statements that are run when a specific action occurs within a database. Triggers are defined to run when changes are made to a table’s data, mostly before or after actions such as DELETE, UPDATE, and CREATE. The most common use case of database triggers is to validate input data.
Tips
- All SQL reserved words are uppercase. Everything else (tables, columns, etc.) is lowercase.
- Divide your queries into multiple lines instead of one long statement in a single line.
- You can’t add a column at a specific position in a table, so be cautious when designing the tables.
- Be aware when using
ASalias statements; the columns are not being renamed in the table. The aliases only appear in the dataset result. - SQL evaluates these clauses in the order:
FROM,WHERE,GROUP BY,HAVING, and finally,SELECT. Therefore, each clause receives the filtered results of the previous filter. It would look like this:
SELECT(HAVING(GROUP BY(WHERE(FROM...))))
Conclusion
You can generate powerful queries from endless permutations of the SQL statements we saw in this article. Remember, the best way to cement the concepts and get better at SQL is by practicing and solving SQL problems. Some of the examples above were inspired by W3School . You can find more interactive exercises in websites like hackerrank and LeetCode which have engaging UI to help you study longer.
The more you practice the better you’ll be, the harder you train the great in you they’ll see. — Alcurtis Turner
Wishing you peace and prosperity!
Bio: Muhsin Warfa builds and designs full stack web software applications for your organizational needs. As a Software product developer, he has worked on multiple projects ranging from commercial apps to student in-course apps having worked on all the life cycles of development from conceptualization and ideas to testing and deployment of apps. If you like this article, feel free to reach out and stay connected on LinkedIn and tune in for more articles/posts.
Original. Reposted with permission.
Related:
- Top Handy SQL Features for Data Scientists
- 7 Steps to Mastering SQL for Data Science — 2019 Edition
- Is SQL needed to be a data scientist?