5 Fundamental AI Principles
While AI may appear magical at times, these five principles will help guide you to avoid pitfalls when leveraging this tech.
By Gabor Angeli, Square.
AI works in mysterious ways, but these five AI principles ought to help you avoid errors when dealing with this tech.
A quick rundown of this post for the AI acolyte on the go:
- Evaluate AI systems on unseen data
- More data leads to better models
- An ounce of clean data is worth a pound of dirty data
- Start with stupid baselines
- AI isn’t magic
Brief caveat — this post will make much more sense with a basic understanding of machine learning. We wrote a blog post a few weeks ago explaining those basics. It’s not required reading to understand this post, but it would certainly be helpful!
1. Evaluate AI systems on unseen data
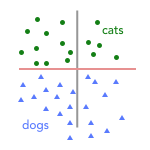
In our last post, we walked through how we’d build a classifier to label images as either cats (green circles) or dogs (blue triangles). After converting our training data to vectors, we got the below graph with the red line representing our “decision boundary” (the line that separates images into cats and dogs after they’ve been converted to vectors).

Clearly, the decision boundary wrongly labels one green-circle cat as a blue-triangle dog. It’s missed a training example. So, what’s to stop the training algorithm picking the following as the decision boundary?

In both cases, we’re classifying the training set with the same accuracy — both decision boundaries miss one example. But when we pass in a new unseen cat, like below, only one of the decision boundaries will correctly predict the point as a cat:

A classifier can look great on the dataset it was trained on, but it may not work well on data it was not trained on. Furthermore, even if a classifier works well on a particular type of input (e.g., cats in indoor scenes), it may not work well on different data for the same task (e.g., cats in outdoor scenes).
Blindly purchasing an AI system without testing it on relevant, unseen information can lead to costly mistakes. A practical method to test on unseen data — withhold some of the data you give the company or person developing your AI, then run the withheld data through the resulting system yourself. Or, at minimum, insist that you be able to try out demos yourself.
2. More data leads to better models
Given the training dataset below, where would you draw the decision boundary?

Your answer likely isn’t wrong — many decision boundaries could split this data accurately. While each of the hypothetical decision boundaries below correctly split the data, they are all very different from one another, and as we saw above, some of them are likely to work worse on unseen data (i.e., the data you care about):

From this small dataset, we don’t know which of these very different decision boundaries most accurately represents the real world. The lack of data leads to uncertainty. So, we collect more data points and add them to our initial graph, getting the graph below:The additional data helps us significantly narrow our options. We’re able to immediately rule out the green and blue decision boundaries, so we know our decision boundary has to be something like the below:

When an ML model behaves unexpectedly, the underlying problem is oftentimes that the model wasn’t trained on enough, or the right kind, of data. It’s also important to keep in mind, though, that while more data almost always helps, the returns are diminishing. The increase in accuracy is large when we double the data of the first graph. However, if we take that graph, now with double the data, and double it again, the increase in accuracy would not be as large. Accuracy grows roughly logarithmically with the amount of training data, so going from 1k to 10k examples is likely to have a much bigger effect on accuracy than going from 10k to 20k.
A last note on data in AI and a personal pet peeve of mine, especially in the tight-budgeted startup world: you’re paying your ML engineers often hundreds of thousands of dollars in salary; make sure you give them a sufficient budget for collecting data and give them the time to collect the data carefully.
3. An ounce of clean data is worth a pound of dirty data
While more data is clearly helpful in the example above, it is only helpful if it is accurate. In the previous example, after we collected our additional data, we had a graph and a decision boundary that looked like the below:

But what if some of these new data points were mislabeled and the real world looked more like this?

Note that although the changed dots occupy the same coordinates as the first graph, their meaning has changed. This leads to an entirely different decision boundary:
Even with only a quarter of the dataset mislabeled, it’s clear how much impact wrong data can have on how we create our model. There are techniques we can use during training to mitigate mistakes in labeling our data, but at the end of the day these can only do so much, and in most cases it’s easier and more reliable to clean the underlying data instead.
The point here is that “clean data” is vital. Clean data means the data is accurately labeled; it means the data covers a reasonable portion of the space of interest; it means there are easy cases and hard cases in the training set, so that the decision boundary doesn’t have as much wiggle room and there’s only one “right” answer; and so on.
4. Start with the stupid stuff
This isn’t to say that you should end with the stupid stuff. However, even if the final method you land on is modern and sophisticated, you’ll have developed it faster, and the final result will be better.
To give an example of this in action, back when I was a first-year grad student, Angel (a fellow student in our lab and researcher at Eloquent) and I each worked on separate projects grounding natural language descriptions of time to a machine-readable representation. Essentially, we were trying to get computers to understand such phrases as “last Friday” or “noon tomorrow”.
Since these projects were required for our grant, Angel worked on a practical, deterministic rule-based system. She was on the hook for making something actually work. On the other hand, I was a wee little rotation student. The team let me pick whatever fancy method I wanted, and I was like a kid in a candy store. I naively explored the newest, shiniest semantic parsing approaches. I went all out, playing with EM, conjugate priors, a whole custom semantic parser…the fun stuff.
Nearly a decade later, I’m grateful to be left with a somewhat well-received and moderately cited paper. However, Angel’s project, SUTime, is now one of the most used components in Stanford’s popular CoreNLP toolkit. The simple approach beat the shiny one.
You’d think I’d have learned my lesson. Just a few years later, now a senior grad student, I was working on getting another system up and running for another grant project. Again, I was trying to get a fancy ML model to train correctly with only modest success. On a particularly frustrating day, I got so fed up that I started writing patterns. Patterns are simple deterministic rules. For example, if the sentence contains “born in,” assume this is a location of birth. Patterns don’t learn and can only get you so far, but they’re easy to write and easy to reason about.
In the end, the pattern-based system didn’t just outperform our original system — it placed in the top 5 systems in the final NIST (National Institute of Standards and Technology) bakeoff organized by the grant and ended up heavily influencing our top-performing ML-based model.
The conclusion: do the simple thing first. Anecdotes aside, there are a number of good reasons for this:
- It’ll lower-bound the performance of the final model. You’d hope anything clever would beat the simple baseline. You should rarely if ever, do worse than a rule-based model. It’s good to know that if you’re doing worse, it means something is very broken, and it’s not just that the task is hard.
- Often, the simple thing requires less (or no!) training data, which lets you prototype without a large investment in data.
- It’ll often reveal what’s difficult about the task at hand, which will often inform the correct ML method to use to handle these difficult parts. Moreover, this will inform the data you collect for more data-intensive methods.
- Simple methods tend to generalize to unseen data with less effort (remember: always evaluate on unseen data!). Simpler models tend to be more explainable, which makes them more predictable and therefore more clear how they’d generalize to unseen data.
5. AI isn’t magic
This is something I regularly say. Everyone nods along, but the sentiment rarely sinks in. AI just seems like magic. When speaking about grand future plans for Eloquent’s AI, I’m guilty of reinforcing this faulty notion. The further I get from the nitty-gritty of training ML models, the less the models seem like curve-fitting and the more they seem more like arbitrary magic black boxes I can manipulate to do my bidding.
It’s easy to forget that, as a field, modern ML is still very young — only 2–3 decades old. Contrasted with the maturity and sophistication of modern ML toolkits, the field as a whole is still rather immature. Rapid advancement makes it easy to forget this.
Part of the nefariousness of ML is that it’s inherently probabilistic. It technically can do anything, just not necessarily at the level of accuracy that you’d like. I suspect that in many orgs, as news spreads up the org chart, the nuance surrounding “level of accuracy” gets dropped, leaving only the “AI can do anything” part of the narrative.
How do you separate the impossible from the possible? Some best practices that I try to follow:
- Talk to the person actually training the model. Not the team lead, not the department head, but the person who pushes “Go” on the model training code. They often have a much better insight into how the model works and what its limits are. Make sure they feel comfortable telling you that the model has limits and perform poorly on certain things — I promise you that it does, whether they tell you or not.
- For NLP projects at least, you can often check the feasibility of a task with a quick and dirty rule-based system. ML is a wonderful way to generate a very large and fuzzy rule set that you could never write down manually, but it’s usually a bad sign if it’s hard even to start writing down a plausible set of rules to do your task. Then, collect a small dataset and try a learned system. Then a somewhat larger one, and so on while you’re still getting improvements. An important rule-of-thumb: accuracy grows approximately logarithmically with the dataset size.
- Never trust accuracies that seem like magic: anything above ~95 or 97%. Certainly never trust accuracies above human-level, or above inter-annotator agreement. With overwhelming probability, either your dataset or your evaluation is broken. Both frequently happen, even to seasoned researchers.
- Everything you read on the internet about ML (news, blogs, papers) is misleading or false until proven otherwise — including this post :).
Original. Reposted with permission.
Bio: Gabor Angeli is an Engineering Manager at Square, and formerly the CTO at Eloquent Labs and a Stanford NLP Ph.D. Gabor works on building products at the forefront of NLP/AI.
Related: