Research Guide for Transformers
The problem with RNNs and CNNs is that they aren’t able to keep up with context and content when sentences are too long. This limitation has been solved by paying attention to the word that is currently being operated on. This guide will focus on how this problem can be addressed by Transformers with the help of deep learning.
Transformers are a type of neural network used in neural machine translation, which mainly involves tasks that transform an input sequence to an output sequence. Such tasks include speech recognition and text-to-speech transformation, just to mention a few.
These kinds of tasks require memory—the upcoming sentence has to work with some context from the previous sentence. This is quite critical so as not to lose any important context between sentences.
Until recently, recurrent neural networks (RNNs) and convolutional neural networks (CNNs) have been used to tackle this challenge. The problem with these is that they aren’t able to keep up with context and content when sentences are too long. This limitation has been solved by paying attention to the word that is currently being operated on. This guide will focus on how this problem can be addressed by Transformers with the help of deep learning.
Attention Is All You Need (2017)
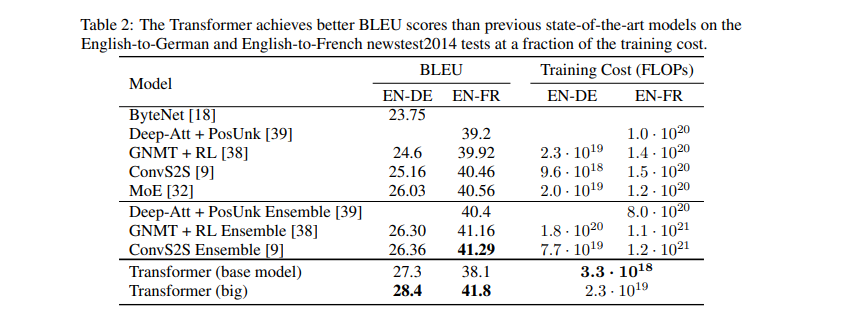
Authors of this paper propose a network architecture — the Transformer — that’s solely based on attention mechanisms. The model achieves 28.4 BLEU (Bilingual Evaluation Understudy) on the WMT 2014 English to-German translation task. The Transformer’s transduction model uses self-attention to compute representations of its input and output without using convolution or sequenced-aligned RNNs.
The majority of neural sequence transduction models have an encoder-decoder model. The Transformer uses the same model with the incorporation of self-attention. Fully connected layers are used for both the encoder and decoder. The encoder is made up of a stack of 6 identical layers, with each layer having 2 sub-layers. The first sub-layer is a multi-head self-attention mechanism, while the second is a position-wise fully connected feed-forward network. There is a residual connection around each of the two sub-layers. This is then followed by a normalization layer.
The decoder also has 6 identical layers with two sub-layers. The decoder incorporates a third sub-layer which conducts multi-head attention over the output of the encoder stack. Each of the sub-layers is also surrounded by residual connections followed by layer normalization. In order to prevent positions from attending to subsequent positions, the self-attention layer in the decoder stack is modified.
The Attention function involves mapping a query and a set of key-value pairs to an output. The query, keys, values, and output are all vectors. The weighted sum of the values forms the output. The weight that’s assigned to each value is calculated by a compatibility function of the query with the corresponding key.
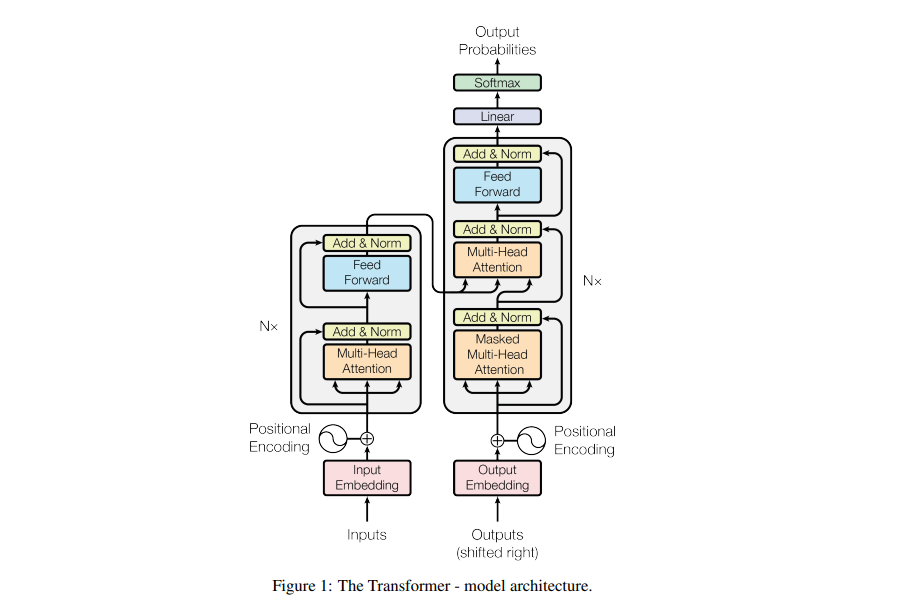
The model was trained on the WMT 2014 English-German dataset, which has about 4.5 million sequence pairs. Here are the results obtained on the English-to-German and English-to-French newstest2014 tests.
Machine learning models don’t have to live on servers or in the cloud — they can also live on your smartphone. And Fritz AI has the tools to easily teach mobile apps to see, hear, sense, and think.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2019)
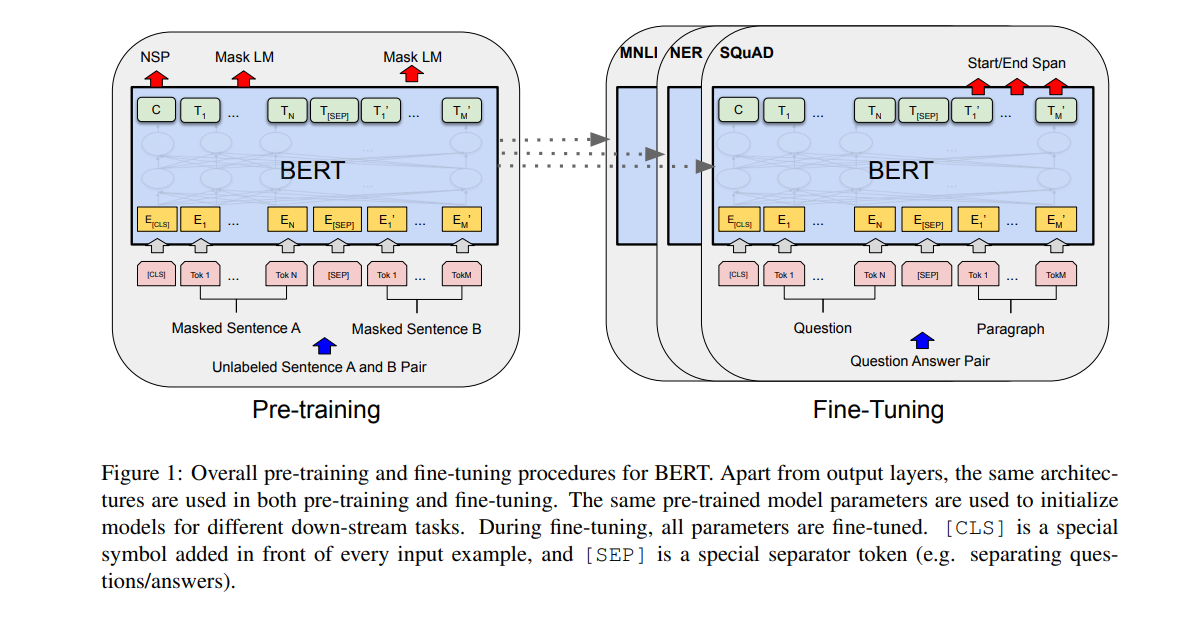
Bidirectional Encoder Representations from Transformers (BERT) is a language representation model introduced by authors from Google AI language. BERT pre-trains deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers.
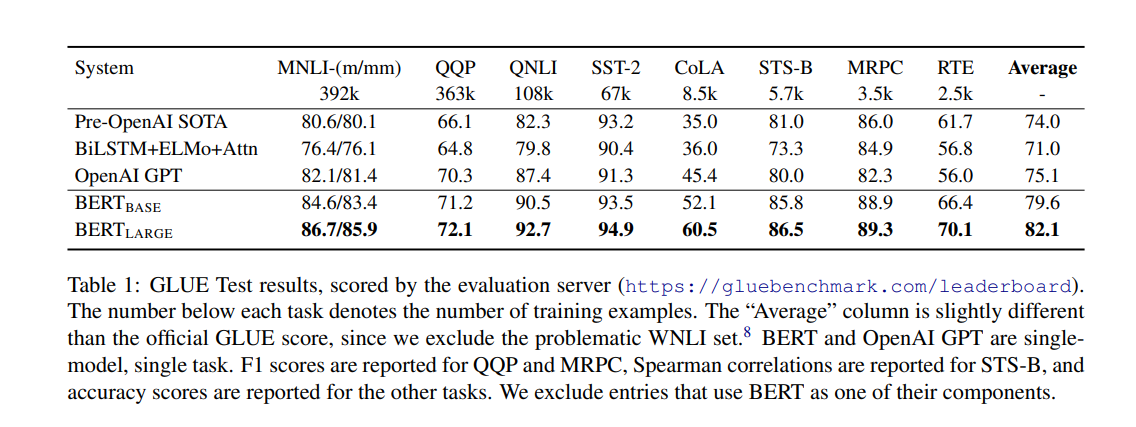
The pre-trained BERT model can be fine-tuned with one additional layer to create models for tasks as such as question answering and language inference. BERT achieves state-of-the-art result on natural language processing tasks. These results include an 80.5% GLUE (General Language Understanding Evaluation) score, and 86.7% MultiNLI accuracy.
In order to allow pre-trained deep bidirectional representations, BERT uses masked language models. BERT has two major steps—pre-training and fine-tuning.
During the pre-training stage, the model is trained on unlabeled data over different pre-training tasks. During fine-tuning, the model is initialized with the pre-trained parameters. The parameters are then fine-tuned with labeled data from the downstream tasks. Each of the downstream tasks is initialized by the same pre-trained parameters but have separate fine-tuned models.
The figure below shows an example of a question-answering task. The BERT architecture is unified across different tasks with minimal difference between the pre-trained and the final downstream architecture.
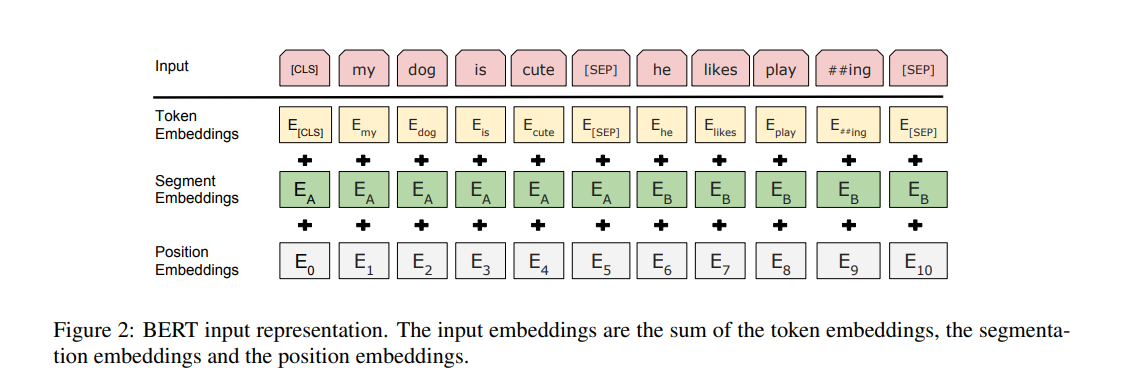
BERT’s architecture is a multi-layer bidirectional Transformer encoder. It uses WordPiece embeddings with a 30,000 token vocabulary. A special classification token [(CLS)] forms the first token for every sequence. Sentence pairs are packed together into a single representation. Sentences are differentiated with a special token [(SEP)] and by adding a learned embedding to every token that indicates if it belongs to sentence A or B.
Pre-training for the model was done on the BooksCorpus (800M words) and English Wikipedia (2,500M words). Here are the GLUE Test results.
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context (ACL 2019)
Transformer-XL (meaning extra long) allows for the learning of dependency beyond a fixed-length without disrupting temporal coherence. It incorporates a segment-level recurrence mechanism and a positional encoding scheme. TransformerXL learns dependency that’s 80% longer than RNNs and 450% longer than vanilla Transformers. It’s available on both TensorFlow and PyTorch.
The authors introduce recurrence to their deep self-attention network. Instead of calculating hidden states from scratch for each new segment, they reuse the hidden states obtained in the previous segments. The reused hidden states act as memory for the recurrent segment.
This builds up a recurrent connection between the segments. Modeling long term dependency becomes possible because information is passed through the recurrent connections. The authors also introduce a more effective relative positional encoding formulation that generalizes to attention lengths that are longer than the one observed during training.
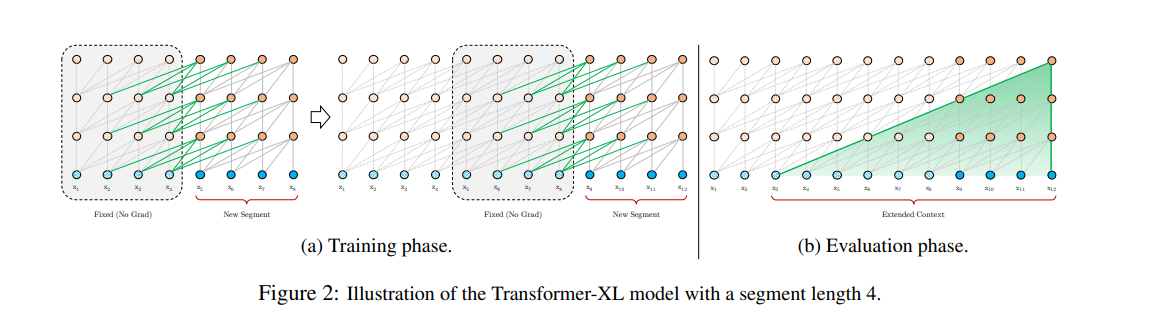
As shown above, during training, the hidden state sequence that’s been computed in the previous segment is fixed and cached to be reused as an external context when the model processes the new segment. The gradient remains within the segment.
The additional input enables the network to include historical information. This enables modeling of longer-term dependency and avoids context fragmentation. Since recurrence is applied to every two consecutive segments of a corpus, a segment-level recurrence is created in the hidden states. This results in context utilization going beyond the two segments.
The performance of this model is shown below.

XLNet: Generalized Autoregressive Pretraining for Language Understanding (2019)
XLNet is a generalized autoregressive pre-training method that enables learning bidirectional contexts by maximizing the expected likelihood over all permutations of the factorization order. It doesn’t use a fixed forward or backward factorization order.
Instead, it maximizes the expected log-likelihood of a sequence with regards to all possible permutations of the factorization order. As a result of these permutations, the context for each position can consist of tokens from both left and right. Bidirectional context is captured since each position learns to utilize contextual information from all positions.
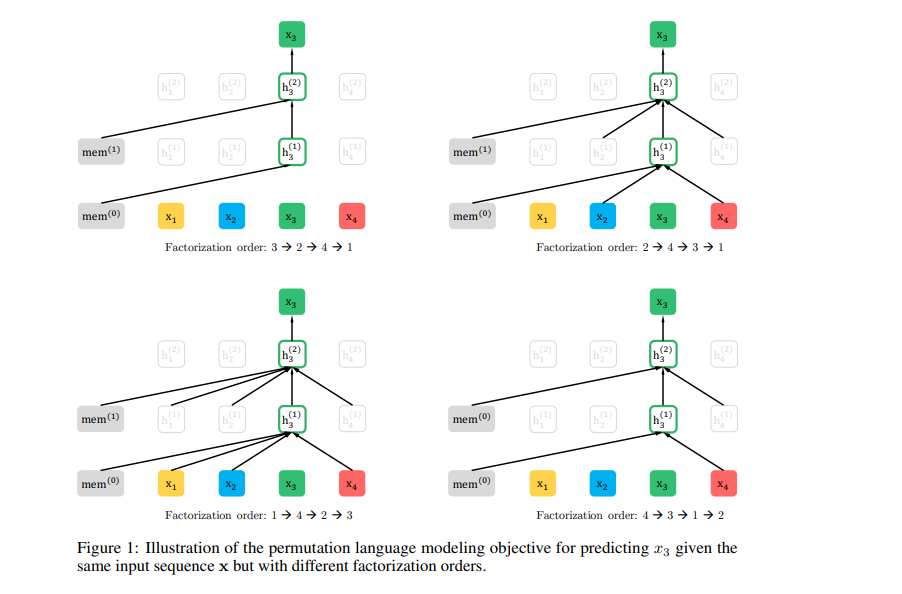
The proposed method’s content stream is the same as the standard self-attention. The query stream attention does not have access information about the context.

This paper implements two ideas from the Transformer-XL-relative positional encoding scheme and the segment recurrence mechanism. In the pre-training phase, the authors randomly sample two segments and treat the concatenation of two segments as one sequence to perform permutation language modeling. The only memory that’s reused is the one that belongs to the same context. The model’s input is similar to the one for BERT.
Here are the various results obtained on the model.

The latest in deep learning — from a source you can trust. Sign up for a weekly dive into all things deep learning, curated by experts working in the field.
Entity-aware ELMo: Learning Contextual Entity Representation for Entity Disambiguation (2019)
In this paper, an entity-aware extension of Embedding for Language Model (ELMo) known as Entity-ELMo (E-ELMo) is learned. Embedding for Language Model (ELMo) was introduced by Peters et. al to produce context-sensitive representation of words as a function of the entire sentence. E-ELMo trains the language model to predict the grounded entity when encountering its mentions, as opposed to the words in the mentions.
Since E-ELMo is, in fact, an extension of ELMo, let’s briefly look at ELMo. Given a sequence, ELMo produces word representations on top of a 2-layer bi-RNN. The input is characters convolutions. ELMo first computes a context-independent representation for each direction. This is done by applying a character-based CNN for each token at position k. The token representations are then passed through 2-layer LSTMs. E-ELMo is trained on a subset of the Wikipedia dataset. Training of E-ELMo is done via AdaGrad with a learning rate of 0.1 for 10 epochs.

Here are the results obtained by this model.

Universal Language Model Fine-tuning for Text Classification (ULMFiT) (2018)
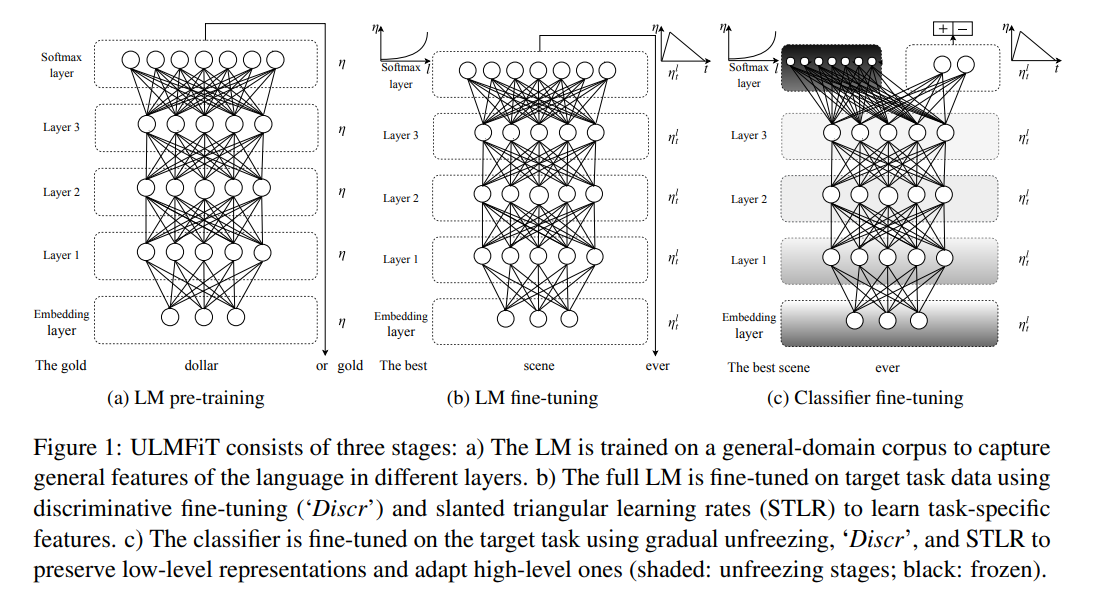
The authors introduce Universal Language Model Fine-tuning (ULMFiT), a transfer learning method that can be applied to any NLP task. ULMFiT pre-trains a language model on a large general-domain corpus and fine-tunes it on the target task. The method works across various tasks and uses a single architecture and training process. It also requires no custom feature engineering or pre-processing.
ULMFiT does not require additional in-domain documents or labels. The steps involved in ULMFiT are; general-domain LM pre-training, target task LM fine-tuning and target task classifier fine-tuning.
The language model is pre-trained on Wikitext-103 that is made up of 28,595 preprocessed Wikipedia articles and 103 million words. The LM is then fine-tuned on data of the target task. Discriminative fine-tuning and slanted triangular learning rates are suggested for fine-tuning the model. The target task classifier is fine-tuned by augmenting the pre-trained language model with two additional linear blocks. Each of the blocks uses batch normalization and a dropout. The ReLU activation is used for intermediate layers and a softmax activation function for outputting the probability distributions.
Here are the test error rates obtained by this model.

Universal Transformers (ICLR 2019)
The authors propose the Universal Transformer (UT), a parallel-in-time self-attentive recurrent sequence model that can be cast as a generalization of the Transformer model. The UT combines the parallelizability and global receptive field of feed-forward sequence models like the Transformer with the recurrent inductive bias of RNNs.
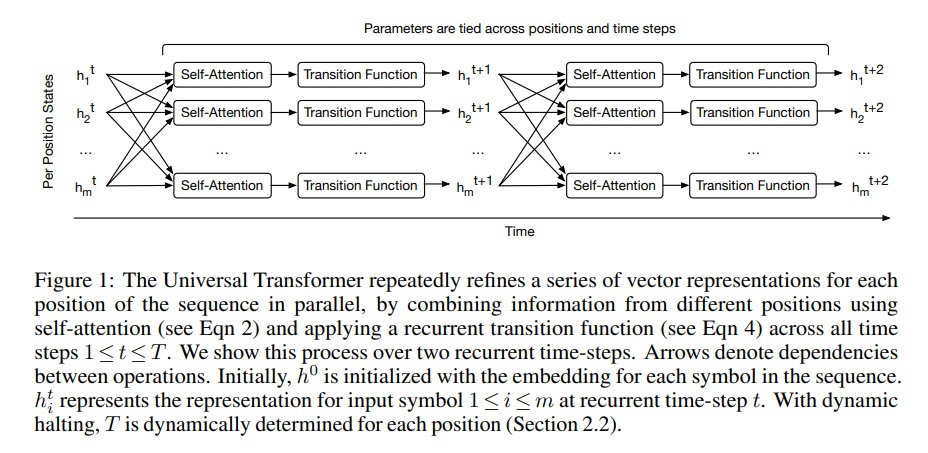
The UT refines its representations iteratively for all symbols in the sequence in parallel using a self-attention mechanism at each recurrent step. This is followed by a transformation that’s made up of a depth-wise separable convolution or a position-wise fully connected layer. The authors also add a halting mechanism that allows the model to choose the required number of refinement steps for each symbol dynamically.
The Universal Transformer architecture is an encoder-decoder one. The encoder and decoder work by applying recurrent neural networks to the representations of each of the positions of the input and output sequence. The recurrent neural network does not recur over positions in the sequence. Instead, it recurs over consecutive revisions of the vector representations of each position.
The representation of every position is revised in parallel in two sub-steps. This is done in every recurrent time-step. The first sub-step involves using a self-attention mechanism to transmit information across all positions in the sequence. This generates a vector representation for each position that’s informed by other representations at the previous time-step. UTs have a variable depth since the recurrent translation function can be applied any number of times. This a major difference between UTs and other sequence models such as deep RNNs or the Transformer.

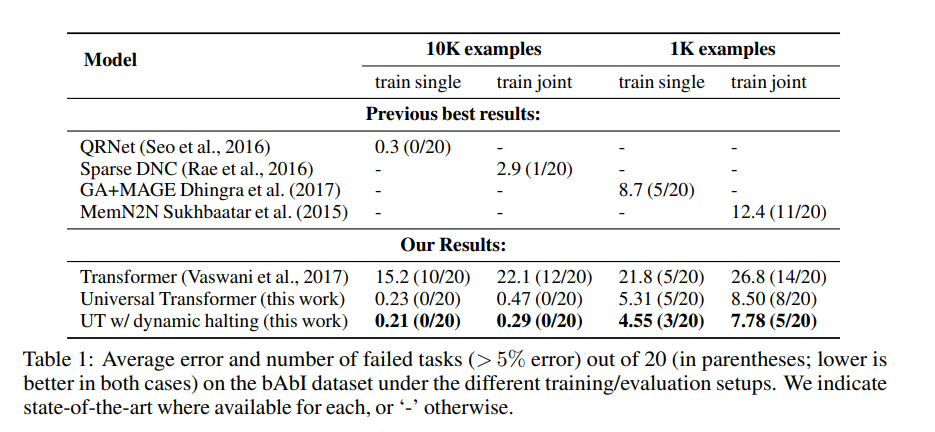
Here’s how this model performs.
Conclusion
We should now be up to speed on some of the most common — and a couple of very recent — techniques in Transformers.
The papers/abstracts mentioned and linked to above also contain links to their code implementations. We’d be happy to see the results you obtain after testing them.
Bio: Derrick Mwiti is a data analyst, a writer, and a mentor. He is driven by delivering great results in every task, and is a mentor at Lapid Leaders Africa.
Original. Reposted with permission.
Related:
- Research Guide for Neural Architecture Search
- Research Guide for Video Frame Interpolation with Deep Learning
- A 2019 Guide for Automatic Speech Recognition